What kind of mechanism is the technology that created a high-performance language model like ChatGPT? AI company engineers explain from scratch with many illustrations

Various AIs, including ChatGPT developed by OpenAI, are now able to conduct human-level conversations. Macro Ramponi, an engineer at AssemblyAI, explains what kind of technology such chat AI is made of in a polite way that even zero knowledge can understand.
The Full Story of Large Language Models and RLHF
It took only two months from the release of ChatGPT until it was used by more than 100 million people. It spread at an incredible speed.
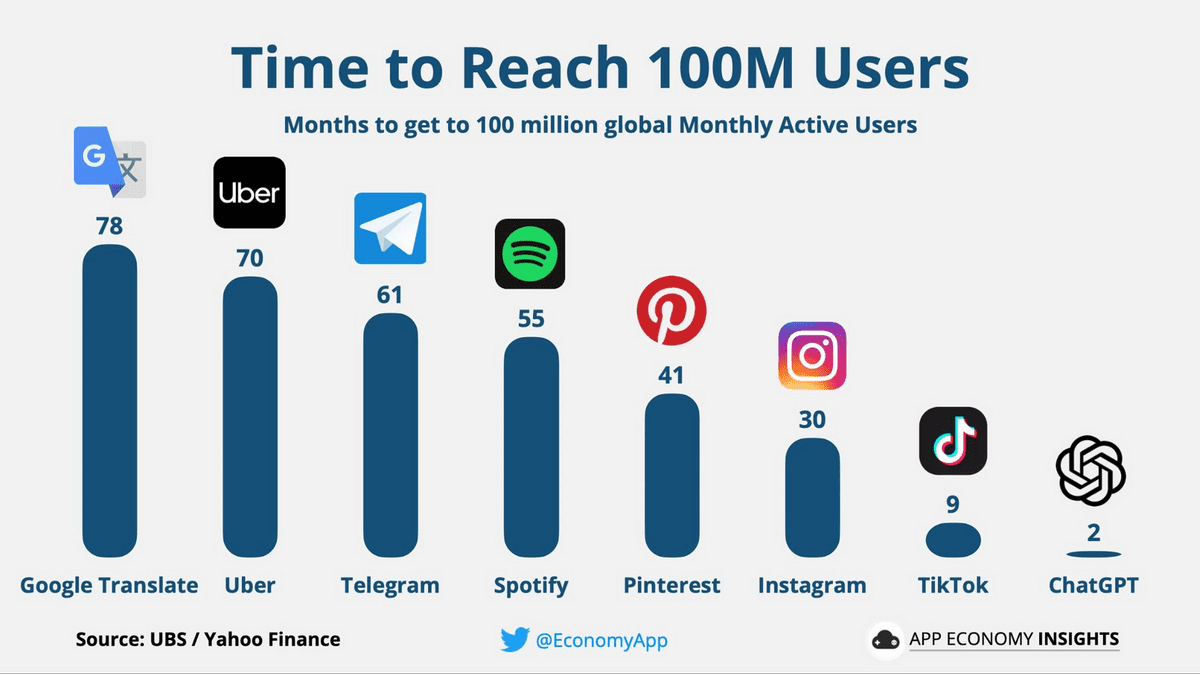
Since the hit of ChatGPT, various chat AIs have appeared, but those chat AIs were born from a technology called 'language model'. A language model is a computational model for calculating the probability that a certain character will follow a given sentence. For example, it is possible to calculate the probability that the word 'blue' follows the sentence 'The color of the sky is'.
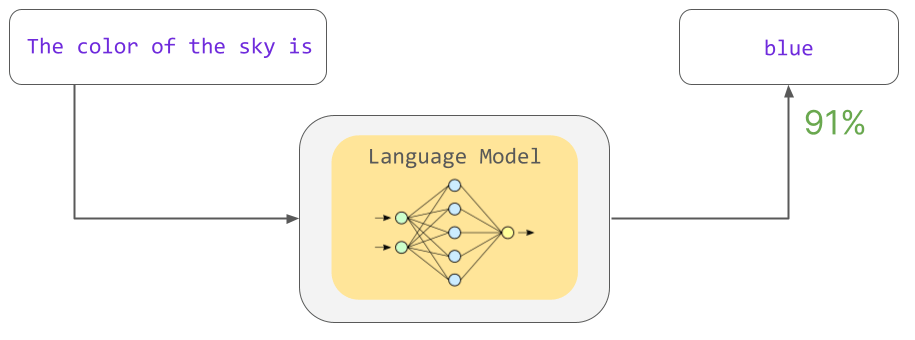
This probability is based on statistical patterns learned during training. In training, the language model learns various language patterns such as grammar and word relationships by calculating the probability of ``what is the missing word?'' from missing sentences. A model trained in this way is called a “pre-trained model”.
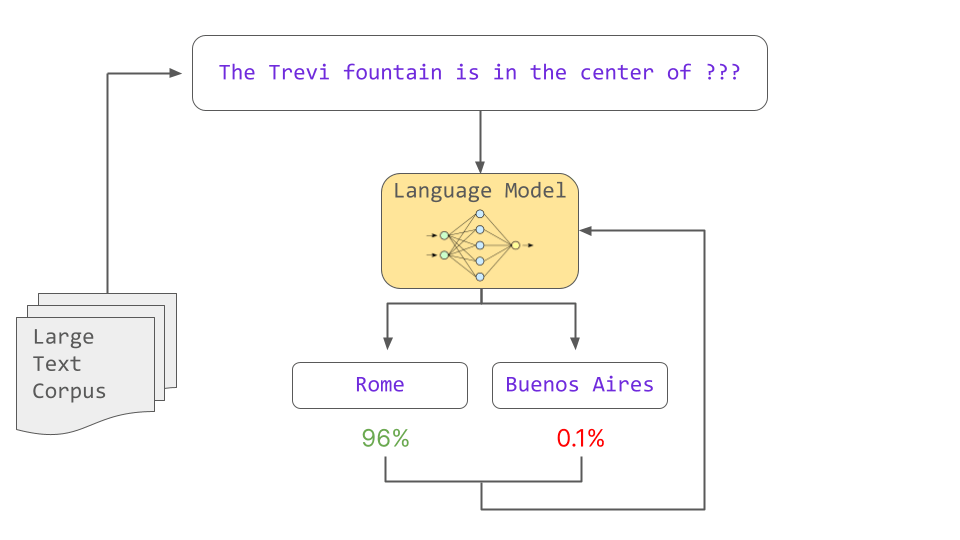
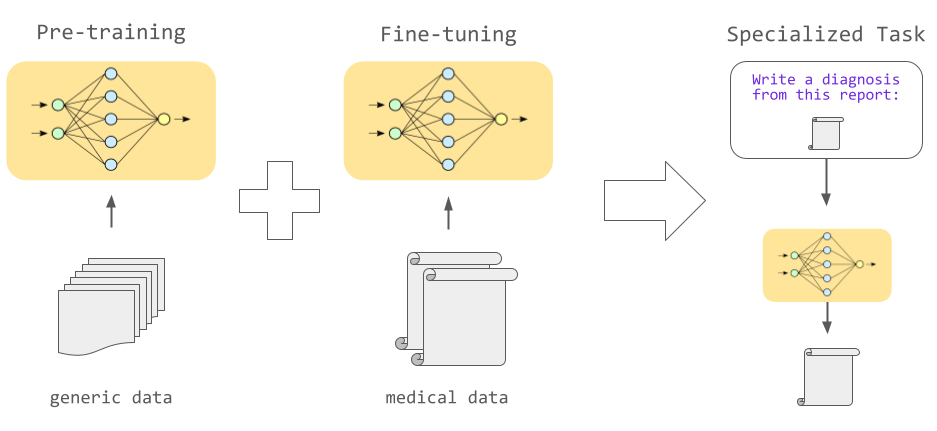
A certain amount of output can be achieved with only pre-training, but fine-tuning, in which additional learning is performed with appropriate data according to the intended use, enables various tasks to be performed with high accuracy.
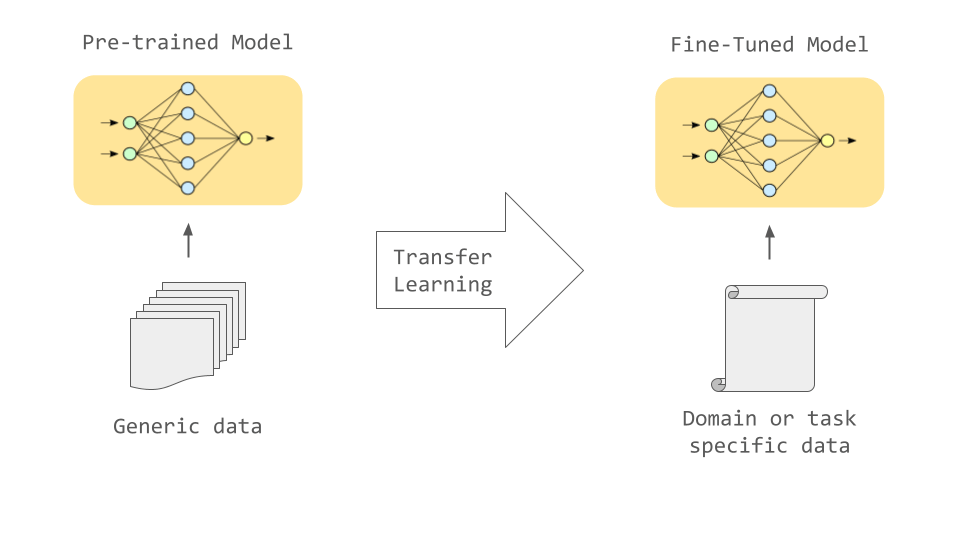
For example, if you want to do machine translation, you can translate text effectively by fine-tuning using parallel translation data of two languages. In addition, fine-tuning using data from a specific field such as the medical field or the legal field makes it possible to successfully process the wording and syntax specific to that field.
The performance of such language models is greatly affected by the size of the neural network that composes the language model. A neural network is based on the mechanism of the human brain, and has a structure in which a large number of neurons are connected. The connection strength between each neuron is represented by a 'parameter', and the higher the parameter value, the stronger the connection between neurons, and the signal input to the previous neuron is clearly transmitted to the next neuron.
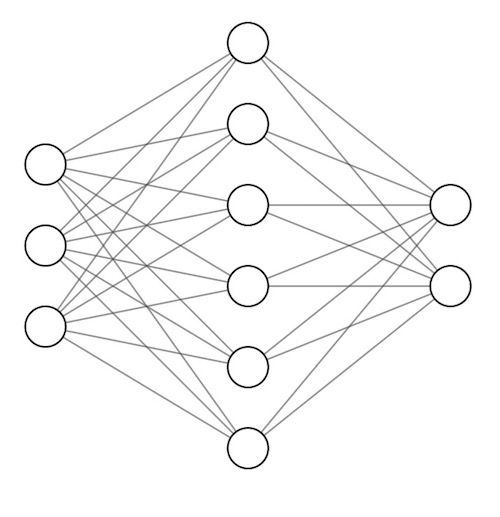
It has been found that the larger the number of parameters, which is the number of connections between neurons, the more diverse statistical patterns can be retained, and the higher the performance of the language model tends to be. On the other hand, the amount of data and time required for training will increase according to the number of parameters. A particularly large model with more than 100 million parameters is called a large-scale language model.

Although the language model is based on a neural network, it is not just a neural network. All language models active as of June 2023 use a neural network with a structure called 'Transformer' that appeared in 2017. Born in the natural language processing field, Transformer has revolutionized the AI field with its efficiency of being able to handle large amounts of data in parallel. Since we can handle data efficiently, it is now possible to train a large language model with a larger dataset. It has also shown remarkable ability to understand context on text data, making it a standard choice for almost all natural language processing tasks.
Transformer's ability to understand context is mainly based on two elements: 'embedding words' and 'attention'. Word embedding treats words as vectorized based on their semantic and syntactic properties, giving language models the ability to understand their relationship to specific contexts. On the other hand, attention is a mechanism that calculates an attention score for each word in a sentence, and the language model can compare and consider ``which words should be emphasized in order to perform the input task'' through the attention mechanism. It happened.
Transformer-based language models process sentences using encoder-decoder structures. Encoders can encode sentences into geometrically and statistically meaningful numbers, and decoders can generate sentences based on those numbers. Depending on the task, it is possible to use only one of the encoder and decoder. For example, the GPT model employs only decoders and specializes in the task of generating new sentences.
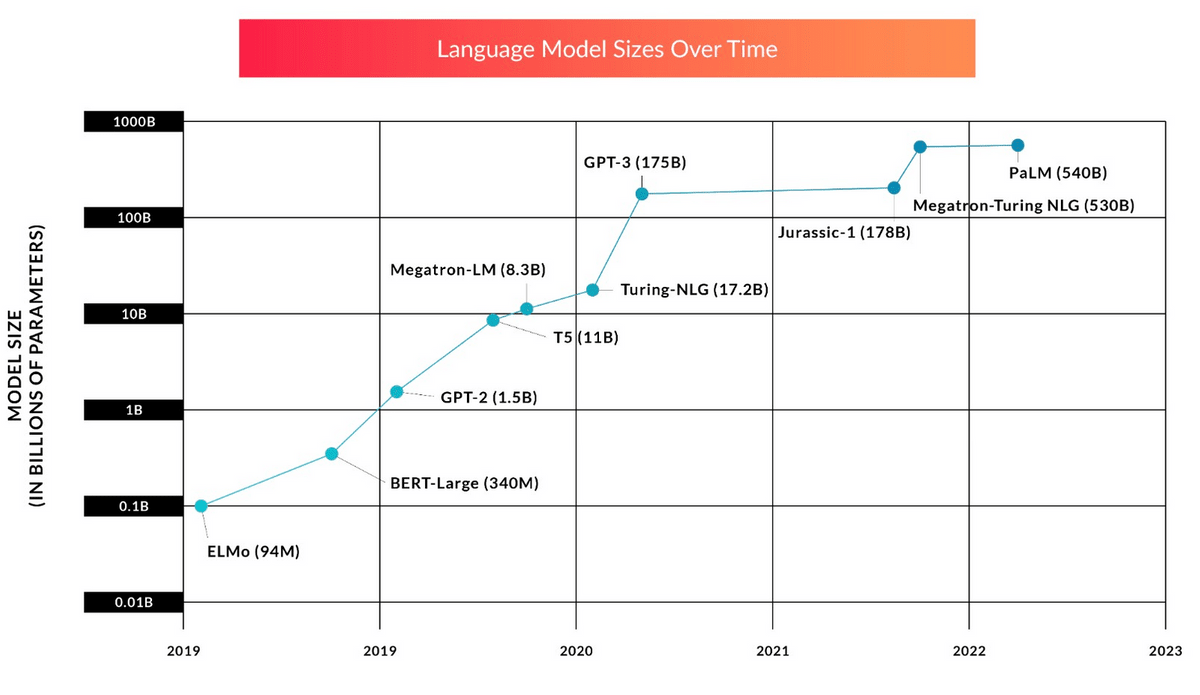
Since the appearance of Transformer, the development of large-scale language models has focused on how to increase the number of model parameters. The first GPT model and ELMo model had millions to tens of millions of parameters, but BERT and GPT-2 with hundreds of millions of parameters soon appeared, and around 2022 boasts hundreds of billions of parameters. Large language models are emerging. As the scale of the model increases, the amount of data and time required for training also increase, and although the detailed amount is not disclosed, it is estimated that it will cost billions of yen just for pre-training. Furthermore, most large-scale language models have been found to be inadequately trained, and if models continue to grow at their current pace, the lack of training data, not model size, will become the bottleneck to improving AI performance. There is a possibility.
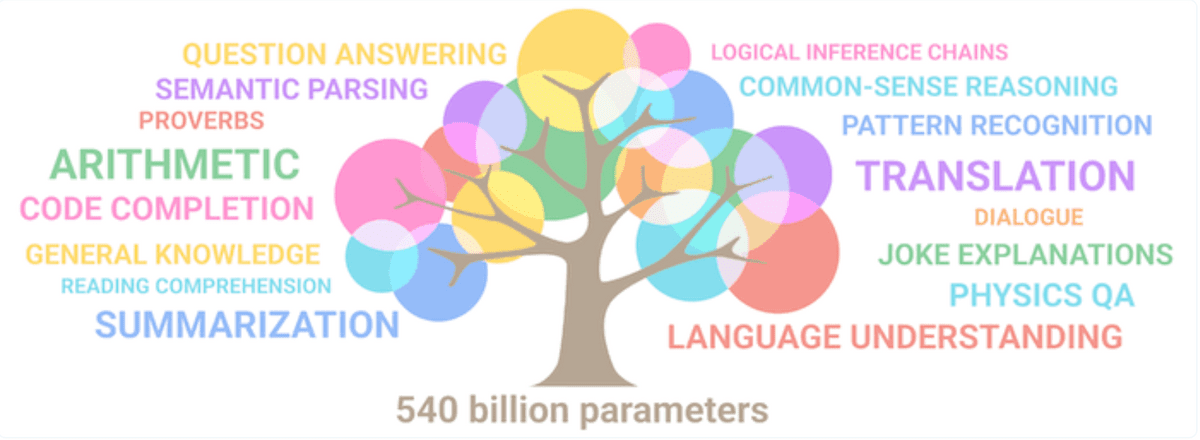
It has been found that increasing the number of parameters not only improves the performance of receiving and answering, but also that large-scale language models acquire completely new skills. Beyond a certain number of parameters, large language models can perform a wide range of tasks, including translating between different languages and the ability to write code, simply by repeatedly observing natural language patterns during training. It is amazing to suddenly be able to execute instructions that could not be executed without fine-tuning with appropriate data in the past.
However, language modeling technology has not brought only good things. The coding ability of the language model is used to create malware, AI-generated content is used for propaganda on SNS, privacy-violating data input during training is included in responses, and mental There is a danger of giving harmful answers to chats asking for professional support.
There are many concerns about language models, but the following three points are said to be the principles to aim for when creating language models.
·Usefulness
Ability to follow instructions and perform tasks, asking questions to clarify the user's intent when necessary.
・Truthfulness
Ability to provide factually accurate information and recognize the uncertainties and limitations of the language model itself.
・Harmlessness
Ability to avoid prejudicial, toxic, or offensive responses and to refuse support for risky activities.
As of June 2023, ``reinforcement learning with human feedback (RLHF)'' is said to be the most suitable for achieving these three points. In RLHF, there is a normal language model shown on the left side of the figure below, and a model shown in green on the right side of the figure below that receives two inputs and decides 'Which answer do humans prefer?' . The quality of answers to tasks is improved by training a normal language model to learn ``answers that are more likely to be preferred by humans''.
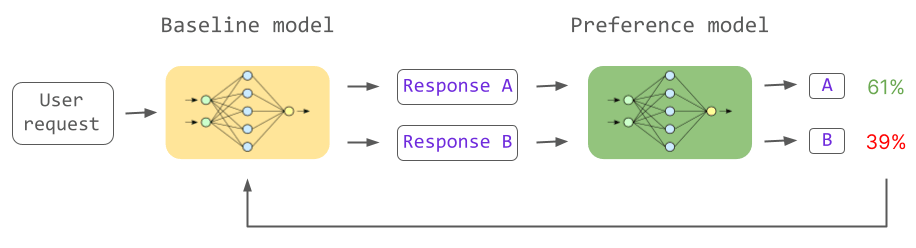
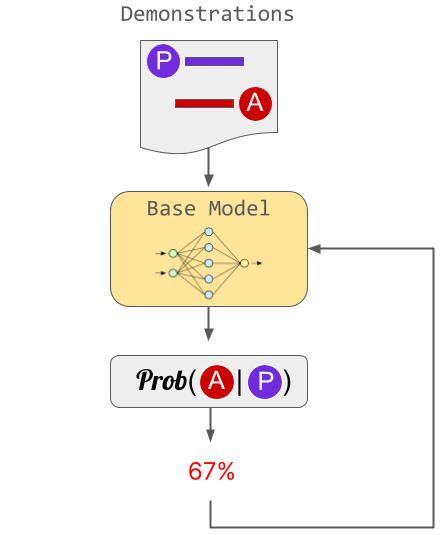
In ChatGPT, RLHF was advanced in three stages. In the first step, we trained the model using human examples as “ideal answers”. The problem with this approach is that it's hard to scale because it requires a human to write the example.
In the second stage, humans voted on the superiority or inferiority of multiple answers generated by the language model, and the answers and voting results were learned by the reward model. In this way, the reward model has acquired the ability to judge 'what kind of answer is human preference'.
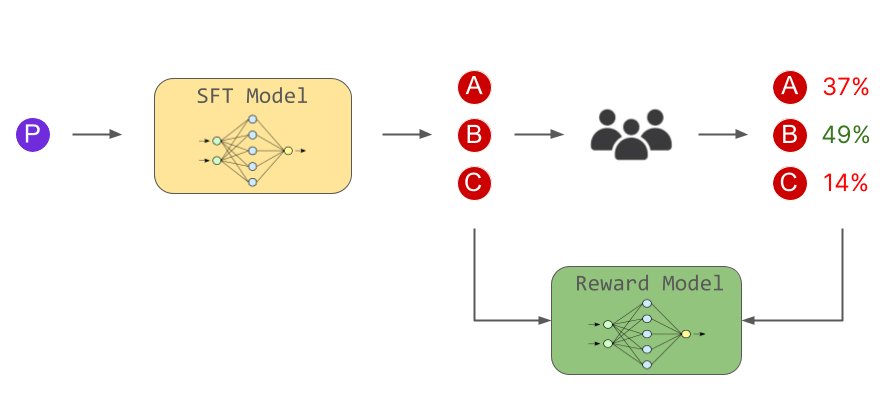
And in the third stage, we trained the language model to output human-preferred answers based on the reward model. It is said that the second and third stages were performed multiple times.
Without RLHF, answers would be generated from the jumble of texts on the Internet. In such a case, there is a possibility that the range of distribution is too wide and the answers are not stable. For example, if you ask a question about a politician, there is a possibility that you will give a neutral answer based on Wikipedia, but there is also a possibility that you will make an extreme statement based on a radical viewpoint such as a bulletin board.
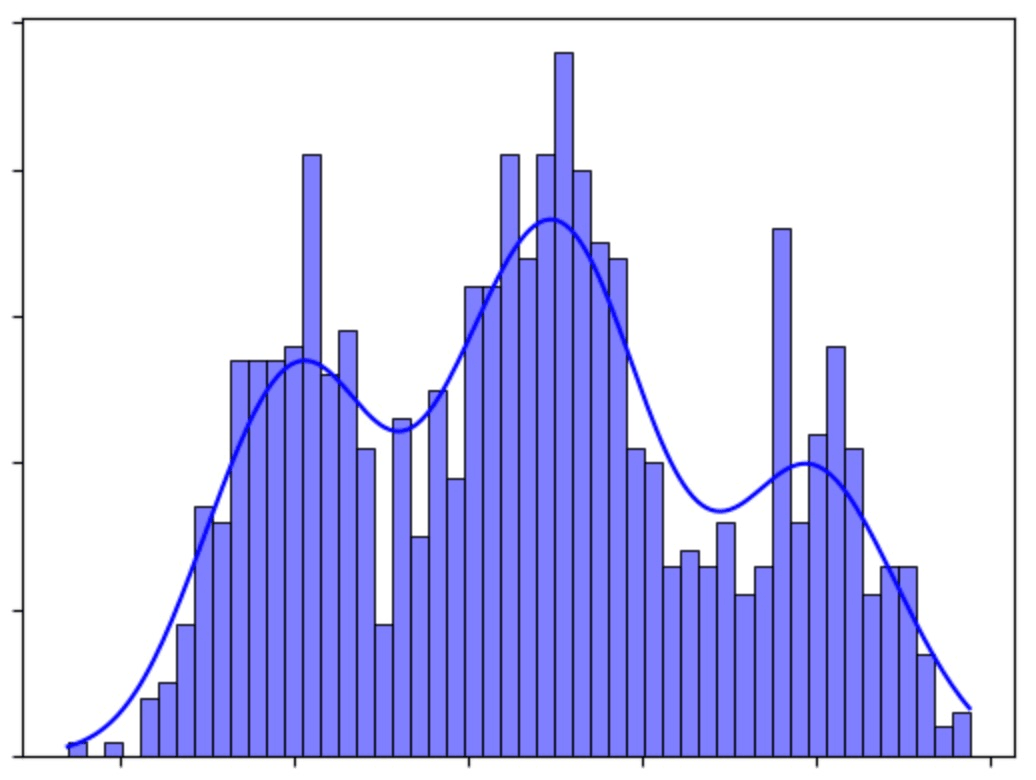
By injecting the human perspective in RLHF, we can think of it as biasing the model to narrow the range it generates. There is a trade-off between the diversity of answers and the stability/consistency of responses, and it is not possible to obtain only one of them. Of course, in fields where accuracy and reliability are required, such as search engines, it is desirable to have consistent and stable answers, so RLHF should be used. Ramponi says that the exploration of new and interesting concepts on which it is based can be hindered.
Related Posts:







in Software, Posted by log1d_ts