An attempt to analyze and control the behavior of AI by dividing the contents of the neural network was successful, the point is to summarize it in units of 'features' rather than units of neurons

A research team at Anthropic, an AI startup invested in by Google and Amazon, is investigating how neural networks handle language and images by grouping individual neurons into units called 'features.' We announced the results of a study showing that it becomes easier to interpret the contents of the text.
Anthropic\Decomposing Language Models Into Understandable Components
A large-scale language model is a neural network with a large number of neurons connected, and it is not programmed based on rules, but rather acquires the ability to perform tasks skillfully by training based on a large amount of data. However, it is not known why the collection of multiple neurons that perform simple calculations allows us to handle languages and images, and it is difficult to understand how to correct problems when a problem is found in the model, or to improve the safety of the model. is difficult to prove.
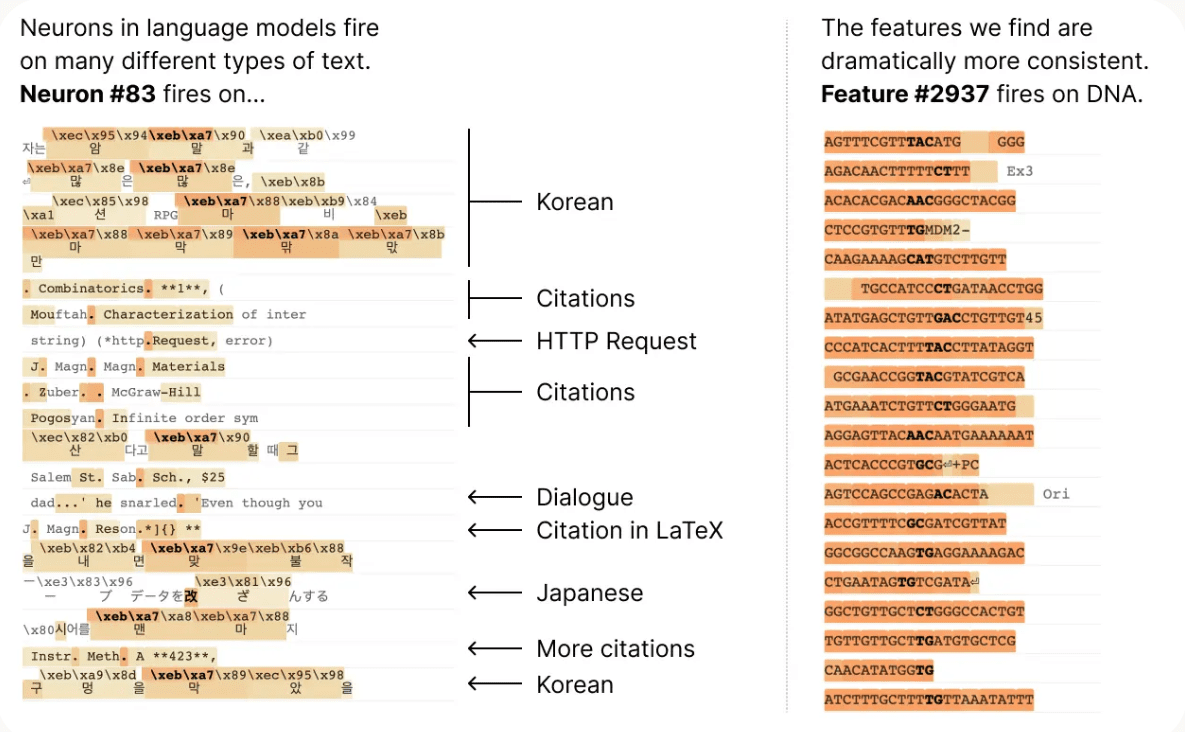
Anthropic's research team first investigated the behavior of individual neurons, but they were unable to find any special relationship between each neuron and the behavior of the entire network. For example, on the left side of the figure below, you can see that neuron 83 is active in various situations such as Korean, quotations, HTTP requests, and dialogue sentences.
Anthropic's research team published a paper on October 4, 2023 titled '
The figure below shows a layer containing 512 neurons of the Transformer language model decomposed into 4096 features. We are able to better show the parts involved in realizing various functions than when looking at individual neurons, such as ``characteristics that respond to legal texts'' and ``characteristics that respond to DNA sequences.''

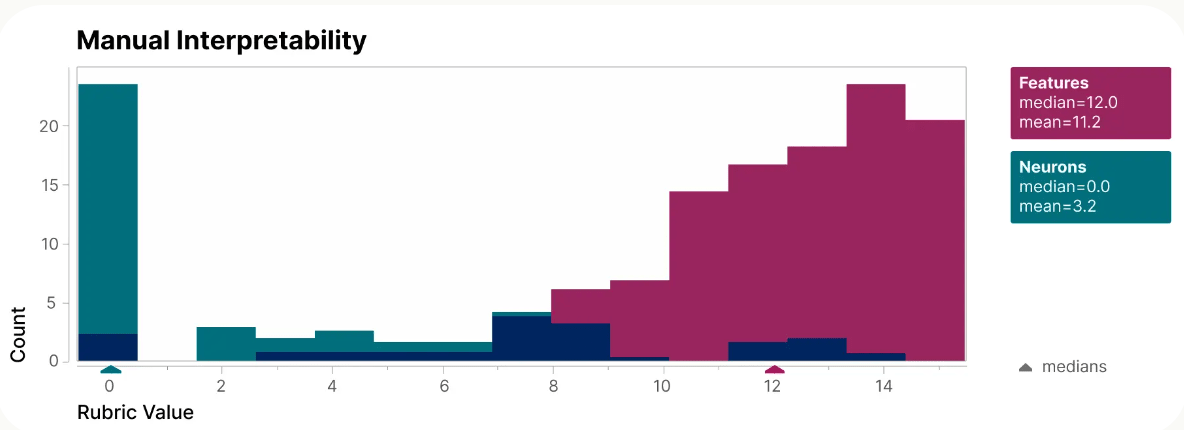
The figure below shows the results of a blind test in which humans were asked to evaluate the interpretability of each neuron individually and when decomposed by features. The results for the ``individual neuron'' case, shown in green, were concentrated at almost 0 points, whereas the results for the ``decomposed by features'' result, shown in red, received high scores.
Also, by fixing the 'feature' value to a high value, it is possible to generate consistent text.

Improving model interpretability will ultimately make it possible to monitor and control model behavior from within, ensuring safety and reliability essential for adoption in society and business. I can. Following this small-scale demonstration model, Anthropic plans to work on scaling up to models many times larger and more complex.
Related Posts:








in Software, Posted by log1d_ts