Google announces a language model 'LaBSE' that can translate even 'unknown languages'

Google has announced ' Language-agnostic BERT sentence embedding model (LaBSE) ' that enables highly accurate multilingual embedding in the natural language model 'BERT'. LaBSE pre-learns 109 languages and can perform highly accurate processing even in languages that are not in the learning data.
Google AI Blog: Language-Agnostic BERT Sentence Embedding
In a natural language model, it is necessary to perform 'embedding' to expand sentences in a vector space, and in a language model that handles multiple languages, it is necessary to embed sentences in different languages in the same vector space. In multi-language embedded models such as LASER and m~USE of Facebook, sentences are directly mapped from one language to another, but performance is inferior when compared to a dedicated bilingual model with limited languages, or due to mapping. There are weaknesses such as poor learning quality in languages that lack the resources of.
'LaBSE' developed by Google this time is a BERT embedding model that allows multilingual embedding in 109 languages. Masked Language Model (MLM), which trains a model by filling in monolingual sentences for 17 billion monolingual sentences and 6 billion bilingual sentences, and MLM is a multilingual bilingual sentence. By implementing the Translation Language Model (TLM) applied to, a model that is effective even for low-resource languages that do not have data during learning is realized. The graph of the number of datasets used for learning is shown below. The blue part is the number of sentences in a single language in each language, and the red part is the number of parallel translations with English.

The basic mechanism of LaBSE is the 'translation ranking task'. The translation ranking task is a task programmed to rank 'which sentence is the most appropriate translation' in a set of sentences in the translation destination language in a given sentence in the translation source language. ![]()
So far, the translation ranking task was excellent at embedding in two languages, but in multiple languages there was a limit on the size of the model and the number of vocabulary (big), so it was difficult to improve accuracy. However, by utilizing the development of language models including MLM and TLM, LaBSE has realized 12 layers of
The results of comparing the accuracy of m ~ USE, LASER, LaBSE using the data of Tatoeba , which publishes example sentences of various languages and their translations, are the results below. '14 Langs' is the result in the language supported by m-USE, '36 Langs' is the result in the language used in XTREME that evaluates multilingual ability, and '82 Langs' is included in the LASER learning data. As a result of the language, you can see that 'All Langs' is all the languages of Tatoeba, and LaBSE has a high score in every language group.
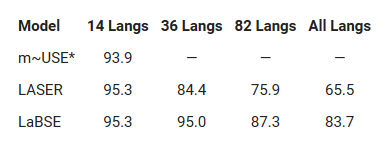
In addition, LaBSE is more than one-third more than 75% accurate in more than 30 languages that were not included in the training data, demonstrating the high multilingual ability of LaBSE.
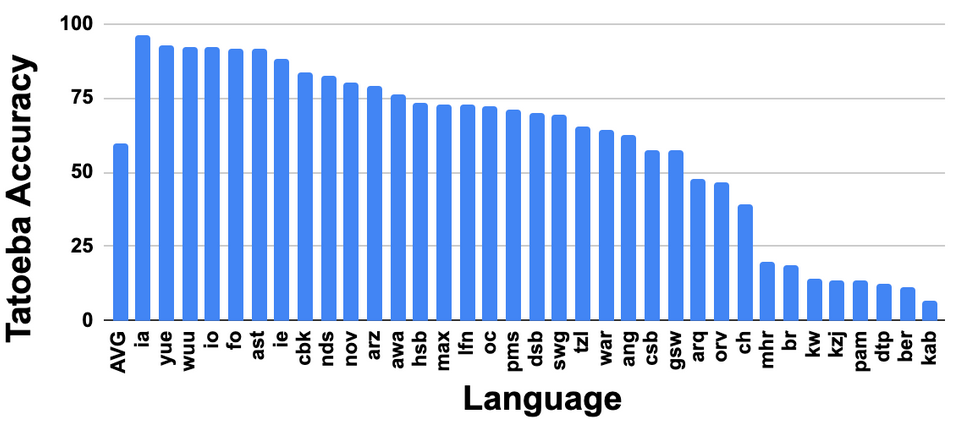
“What we're showing here is just the beginning. I believe there are more important research challenges, such as building better models that support all languages,” said Google. LaBSE is published on TensorFlow Hub.
LaBSE | TensorFlow Hub
https://tfhub.dev/google/LaBSE/1
Related Posts:







in Software, Posted by darkhorse_log