How has Google's new natural language processing model 'ALBERT' evolved?

By
The natural language processing model `` Bidirectional Encoder Representations from Transformers (BERT) '' announced by Google is necessary to learn the natural language processing model from scratch to pre-learn context understanding and emotion analysis from huge existing text data Without having to know the language in advance. In September 2019, ' ALBERT ', which made BERT lighter and faster, was released by Google.
Google AI Blog: ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
Google announced ALBERT, an upgrade to BERT at the International Conference on Learning Representations (ICLR) 2020 . Radu Solicut, a Google researcher, states that ALBERT performs well in 12 natural language processing tasks, including the Stanford Question Answering Dataset and the RACE benchmark.
BERT and ALBERT learn both context-independent and context-dependent expressions for a single word. For example, the word 'bank' classifies different expressions depending on the context, such as the meaning of the word itself, the expression 'bank' in the context of financial transactions, and the expression 'bank' in the context of rivers. This improves learning accuracy.
Improving the learning accuracy leads to an increase in the capacity of the model itself. `` Although the capacity of the model increases, the performance improves, but the length of time required for pre-learning and the unexpected increase in the model capacity increase, '' said Jeng Jong Lan, a Google researcher like Solicut It is more likely that bugs will occur and the model capacity cannot be increased. '
ALBERT optimizes performance by designing parameterized training data so that model capacity is properly allocated. ALBERT reduces data capacity by as much as 80% at the expense of a slight performance penalty from BERT by using low-dimensional input parameters for context-independent words and high-dimensional input levels similar to BERT for parameters for context understanding. Has succeeded.

By
According to Solicut, ALBERT adds another important design. Natural language processing models, such as BERT, XLNet, and RoBERTa , rely on multiple independent layers of the stack structure, but add redundancy by performing the same processing on different layers. ALBERT optimizes processing by sharing parameters between different layers. By adopting this design, the accuracy of language processing has been slightly reduced, but the model capacity has been further reduced and the processing speed has been increased.
By implementing two design changes, ALBERT achieves 89% parameter reduction and improved learning speed compared to BERT. The reduced parameter size allows more memory, allowing more pre-learning and consequently significantly improving performance.
Solicut and colleagues have evaluated ALBERT's language comprehension skills with reading comprehension tests using a RACE dataset . The scores of the reading test of each natural language model are as follows, Gated AR which is a model pre-trained only for word expressions that do not depend on context is `` 45.9 '', BERT which performed language learning depending on context is `` 72.0 '' , XLNet and RoBERTa developed after BERT were '81.8' and '83.2', respectively, and ALBERT was '89.4'. The higher the score, the better the model gave the answer.
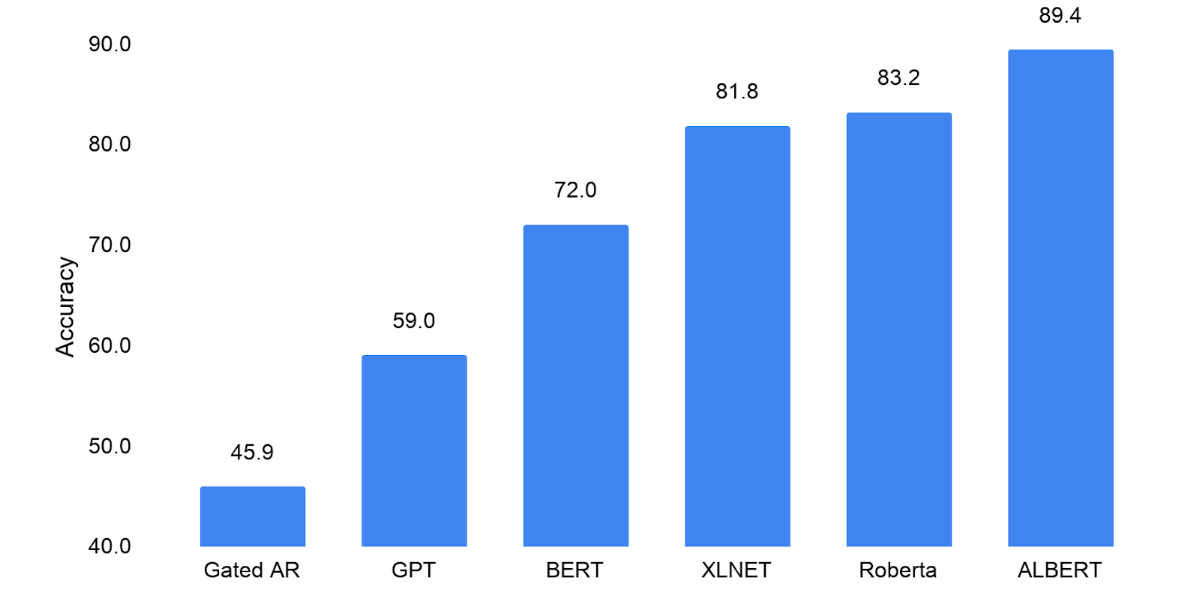
'Albert's high scores in reading comprehension tests show the importance of natural language processing models in producing more compelling contextual representations. Both model efficiency and performance for language processing tasks can be greatly improved. '
Related Posts:








in Software, Posted by darkhorse_log