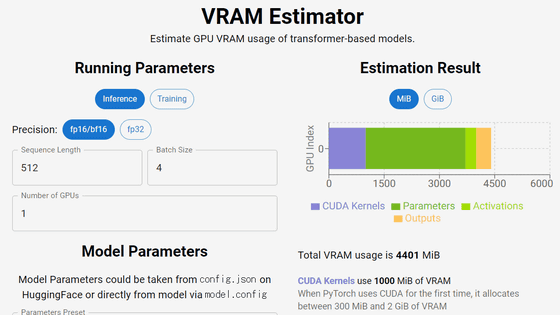
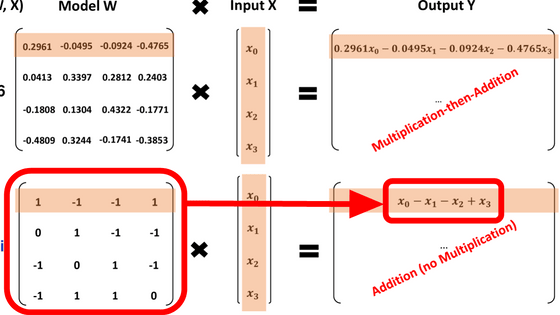
Dynamic quantization model that reduces the size of DeepSeek-R1 by up to 80% is now available

Run DeepSeek-R1 Dynamic 1.58-bit
https://unsloth.ai/blog/deepseekr1-dynamic
Quantization is a technique to reduce the size of data by reducing its precision. For example, a 32-bit floating point (FP32) can express precise values such as 0.123456, but when this is converted to an 8-bit integer (INT8), it is converted to an integer between 0 and 255. Of course, precision is lost, but in return, the data size is reduced to one-quarter.
Quantization can reduce memory usage, speed up calculations, or enable more efficient computations with reduced power consumption, but too much quantization can result in loss of precision, so a good balance must be found.
After analyzing the DeepSeek-R1 architecture, unsloth performed 'dynamic quantization,' which quantizes each part of the model at a different compression rate. As a result, unsloth reported that they were able to reduce the original model size from 720GB to 131GB, a reduction of about 80%.
For example, the first three layers of the model, which account for 0.5% of the total weight, play a very important role and are therefore quantized with 4 or 6 bits. In addition, the multiple 'experts' models used in
In particular, the layer 'down_proj', which is responsible for important processing in calculations, seems to be quantized with relatively high accuracy. There are four types of DeepSeek-R1 dynamically quantized by unsloth: '1.58-bit version (model size 131GB)', '1.73-bit version (model size 158GB)', '2.22-bit version (model size 183GB)', and '2.51-bit version (model size 212GB)'. The down_proj layer is quantized with different settings in each version.
And for layers that account for about 88% of the total weights, they have achieved a significant size reduction by quantizing them with a low precision of 1.58 bits. If all layers are quantized in the same way, problems such as infinite loops and meaningless outputs will occur, but unsloth says that dynamic quantization avoids these problems.
The dynamically quantized DeepSeek-R1 works best in environments with a total of 80GB or more of VRAM and RAM. In terms of specific performance, it achieved a throughput of 140 tokens per second and 14 tokens per second for single-user inference. It can also run without a GPU if you have 20GB of RAM, but the processing speed will be slower in that case.
To test the model, unsloth had them create a Flappy Bird- like game and evaluate its performance. As a result, unsloth reported that the 1.58-bit version was still powerful enough for practical use.
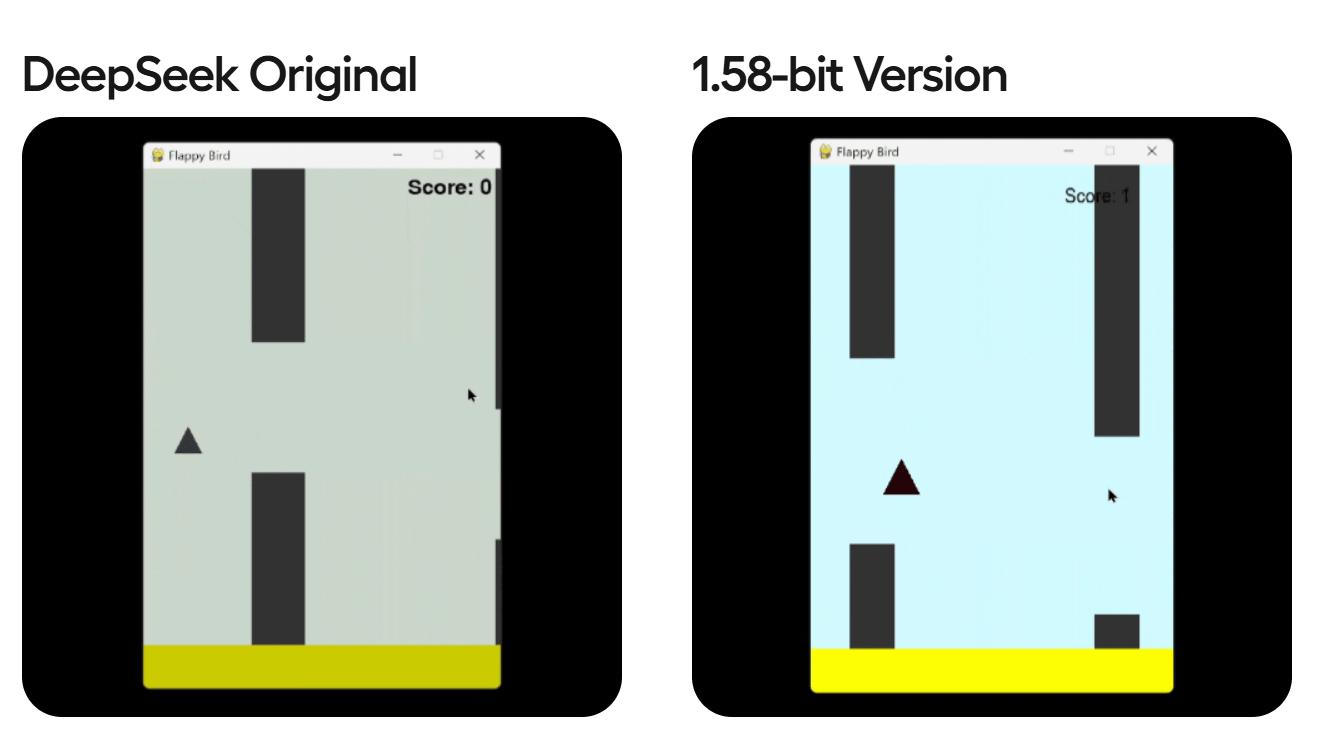
The performance comparison results between a dynamically quantized model (Dynamic) and a model with all layers quantized equally (Basic) are published on the following page.
DeepSeek-R1 Dynamic 1.58-bit | Unsloth Documentation
https://docs.unsloth.ai/basics/deepseek-r1-dynamic-1.58-bit
The four dynamically quantized models by unsloth are published in the Hugging Face below, and can be used in various frameworks such as llama.cpp, Ollama, and vLLM.
unsloth/DeepSeek-R1-GGUF at main: 1.58-bit version (model size 131GB)
https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_S
unsloth/DeepSeek-R1-GGUF at main: 1.73-bit version (model size 158GB)
https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ1_M
unsloth/DeepSeek-R1-GGUF at main: 2.22-bit version (model size 183GB)
https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-IQ2_XXS
unsloth/DeepSeek-R1-GGUF at main: 2.51 bit version (model size 212GB)
https://huggingface.co/unsloth/DeepSeek-R1-GGUF/tree/main/DeepSeek-R1-UD-Q2_K_XL
Related Posts: