'VRAM Estimator' that estimates the amount of VRAM used when running a large-scale language model
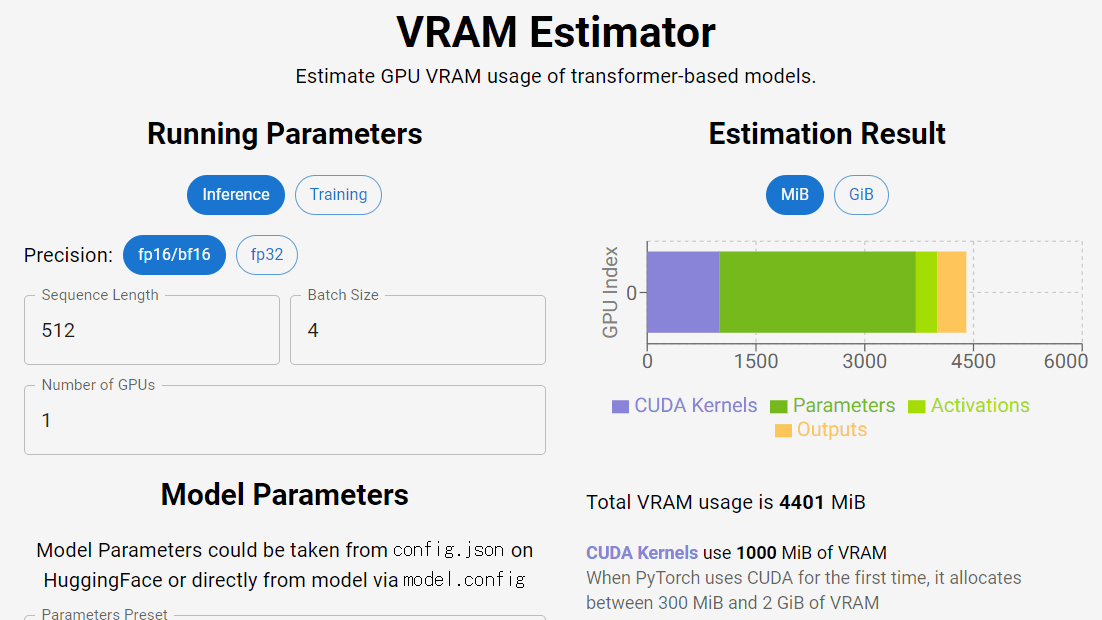
To operate large-scale language models, the GPU is used for calculation processing, so the capacity of graphics memory (VRAM) is important. ' VRAM Estimator ' is a web application that uses simulation to predict the amount of VRAM required for various models.
VRAM Calculator
When you access the VRAM Estimator, it looks like this.
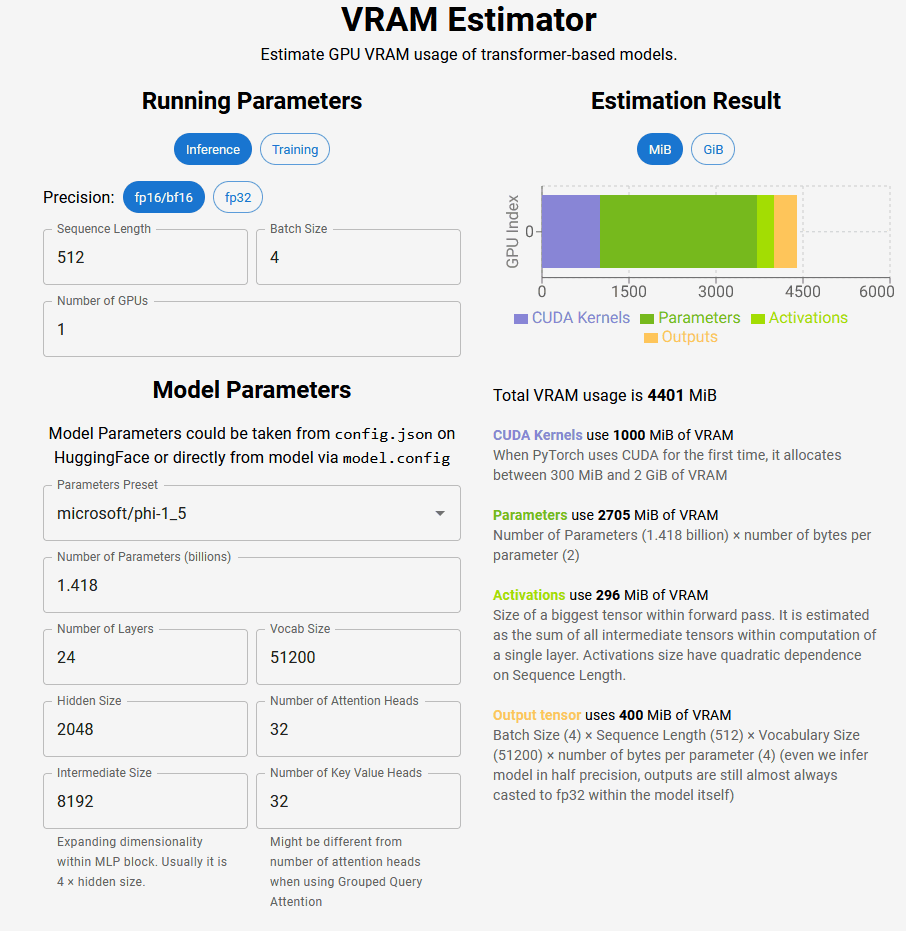
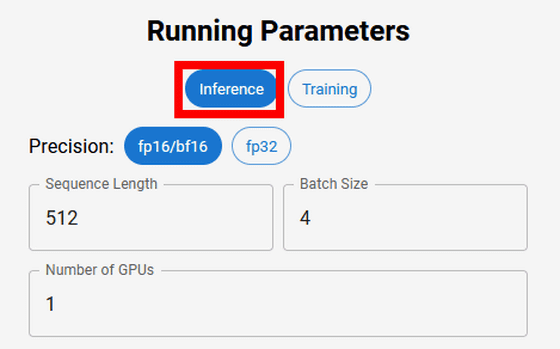
Specify the calculation details in 'Running Parameters' in the upper left. For Inference, you can select bf16 / fp16 or fp32 for Precision, and specify Sequence Length, Batch Size, and Number of GPUs.
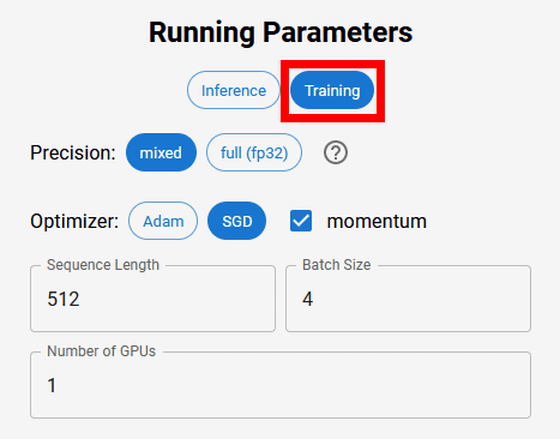
For Training, select ' mixed (mixed precision) ' or 'full (fp32)' for Precision, ' Adam ' or ' SGD ' for Optimizer (gradient method), and select Sequence Length, Batch Size, Number of GPUs can be specified.
In 'Model Parameters', enter the values shown in model.config or the Hugging Face of the AI platform. Select the model name in Parameters Preset, Number of Parameters (number of parameters, in billions), Number of Layers (number of layers), Vocab Size (vocabulary size), Hidden Size (hidden size), Number of Attention Heads (Attention- It is OK if you specify the number of Heads), Intermediate Size (size of intermediate layer), and Number of Key Value Heads (weight of key value).
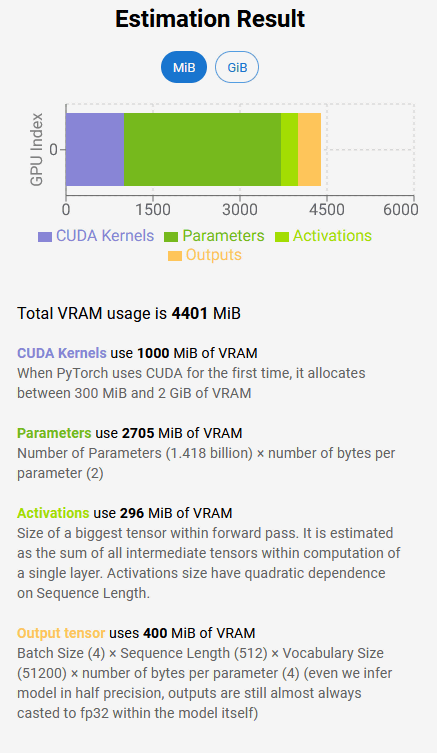
You will then see an estimate of your total VRAM usage on the right. In the case below, the total usage fee is 4401 MiB ( mebibytes ), which is estimated to include 1000 MiB for the CUDA kernel, 2705 Mi for parameters, 296 MiB for the maximum tensor in the forward path, and 400 MiB for the output tensor.
The meaning of each element is explained by developer Alexander Smirnov in the blog below.
Breaking down GPU VRAM consumption
https://asmirnov.xyz/vram
In addition, the source code of VRAM Estimator is published in the GitHub repository below.
vram-calculator/app/_lib/index.ts at main · furiousteabag/vram-calculator · GitHub
https://github.com/furiousteabag/vram-calculator/blob/main/app/_lib/index.ts
Related Posts:







