Stanford University research group releases ThunderKittens, a domain-specific language for AI that runs on GPUs

A research team led by Professor Christopher Le of Stanford University has released ' ThunderKittens ,'
ThunderKittens: A Simple Embedded DSL for AI kernels Hazy Research
https://hazyresearch.stanford.edu/blog/2024-05-12-quick-tk
GPUs Go Brrr · Hazy Research
https://hazyresearch.stanford.edu/blog/2024-05-12-tk
The research team used the NVIDIA H100 to maximize GPU utilization. The H100's performance in half-precision matrix multiplication calculations using Tensor cores is 989 TFLOPS, far exceeding the total of all other computing capabilities, which is about 60 TFLOPS. In other words, the GPU utilization of the H100 is almost entirely dependent on the utilization of the Tensor cores.
The research team focused on improving four areas: WGMMA instructions, address generation, shared memory, and occupancy, so that the Tensor cores could work on every GPU cycle.
・WGMMA command
The H100 has a new instruction set called 'warp group matrix multiply accumulate (WGMMA)'. With the WGMMA instruction, 128 threads of the streaming multiprocessor (SM) synchronize cooperatively and perform matrix operations directly from shared memory. According to the research team's microbenchmarks, without the WGMMA instruction, GPU utilization would plateau at about 63%.
However, the problem of how to place data in shared memory when using the WGMMA instruction is very complicated, and the research team had a hard time finding the right way to place data because NVIDIA's documentation was incorrect. However, it was an unavoidable problem because not using the WGMMA instruction would result in a loss of 37% of GPU utilization.
Address generation
Because both the Tensor cores and memory of the H100 operate very fast, even generating memory addresses to fetch data consumes a significant amount of chip resources. By using an instruction called Tensor Memory Accelerator (TMA) provided by NVIDIA, it is possible to specify a multidimensional tensor layout in global memory or shared memory and fetch parts of the tensor asynchronously. Using TMA, it is possible to significantly reduce address generation costs.
·shared memory
The latency of a single access to shared memory is relatively small, about 30 cycles, and has been overlooked in the past because other areas were the bottleneck. However, when working on 'maximum optimization' like this, it is important to pay attention to even these small latencies.
The research team tried to reduce data movement between registers and shared memory as much as possible, and when data needed to be moved, they used the WGMMA and TMA instructions to move data asynchronously between shared memory and registers.
·Occupancy
Occupancy is a measure of how many warps a GPU has actually executed compared to the maximum number of
However, there is no doubt that a higher occupancy rate is more likely to improve the actual performance of the hardware. Also, hardware such as the A100 and RTX 4090 are more dependent on synchronous instruction dispatch than the H100, so improving the occupancy rate is important.
To address these issues, the research team designed and released 'ThunderKittens' as a domain-specific language (DSL) to be embedded within CUDA.
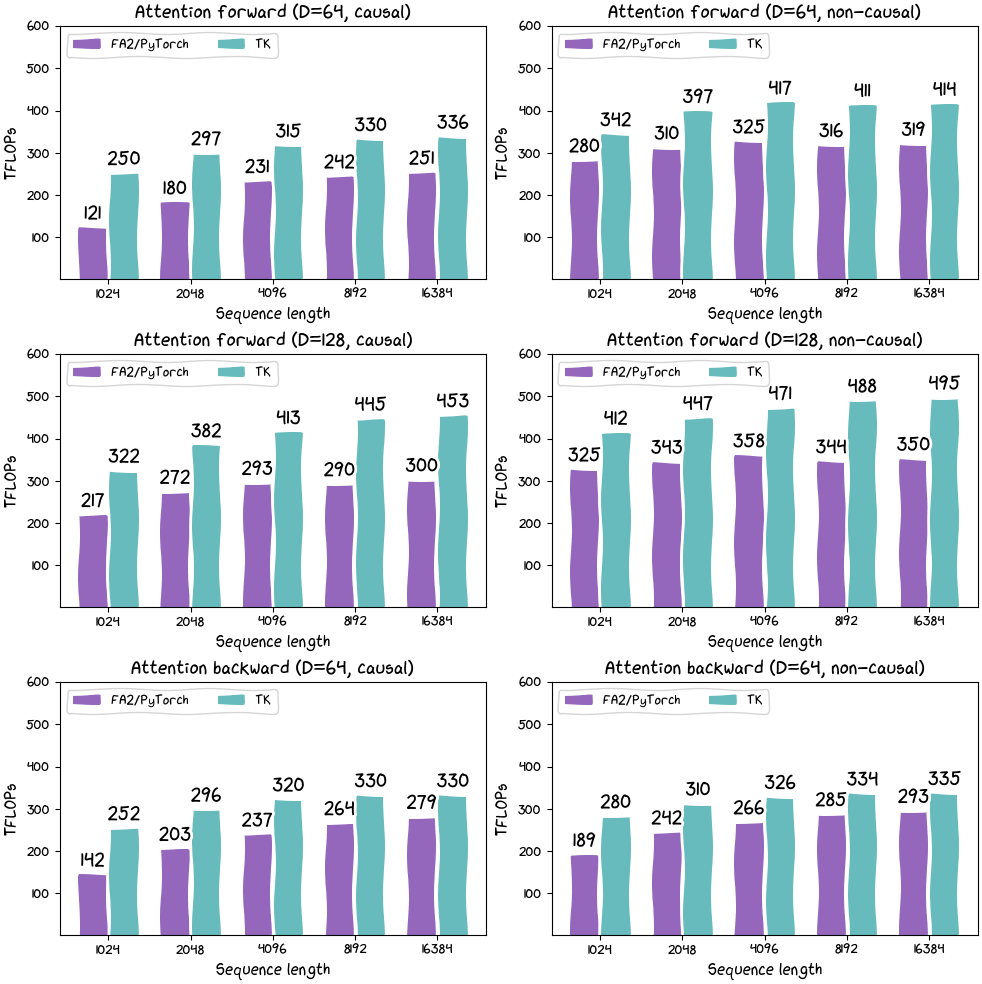
The results of measuring the difference in the computational power of
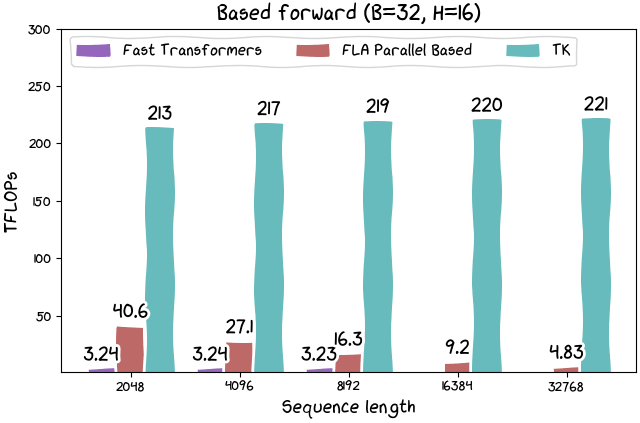
In addition, ThunderKittens can perform calculations for Linear Attention at approximately 215 TFLOPS, which is a 'significant' increase in speed compared to conventional methods.
The ThunderKittens code is available on GitHub under an open source license , so if you're interested, check it out.
Related Posts:







