Various Numbers Good to Know for Developers of Large Language Models

Learning from the `
ray-project/llm-numbers: Numbers every LLM developer should know
https://github.com/ray-project/llm-numbers
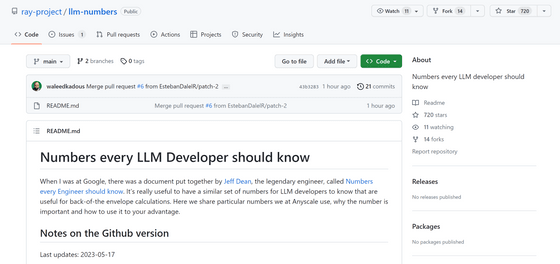
◆ Prompt Edition

40-90%: How much you can save by adding 'briefly' to prompts
LLM responses are charged per token, so requesting LLM responses to be concise can significantly reduce costs. Instead of just adding 'briefly' to the prompt, for example when prompting for 10 ideas, specifying 5 instead will cut the cost in half.
1.3: Average number of tokens per word
LLM works with
In addition, in the case of Japanese, it will be about 1.1 tokens per character .
◆ Price

Prices are subject to change, of course, but the numbers in this section are significant given how expensive it is to run an LLM. The numbers here are from OpenAI, but prices from other providers such as Anthropic and Cohere are similar.
50x: GPT-4 vs. GPT-3.5 Turbo cost ratio
For many practical applications, it is much better to use GPT-4 to generate data and use it to fine-tune small models. With GPT-3.5-Turbo, that cost is roughly 1/50th of GPT-4. So we really need to see what we can do with the performance of GPT-3.5-Turbo. For tasks such as summarization, GPT-3.5-Turbo is sufficient.
5x: cost ratio of text generation with GPT-3.5-Turbo and
This means that it is much cheaper to store and retrieve data in Vector Store than to ask LLM to generate it for you. Example: 'Where is the capital of Delaware?' with a neural engine search system costs about 5 times less than asking GPT-3.5-Turbo. Compared to GPT-4, its cost is a whopping 250 times less.
10x: Cost ratio between OpenAI embedding and self-hosted embedding
According to Kados's research, using g4dn.4xlarge, which is available for $1.20 (about 165 yen) per hour, HuggingFace's SentenceTransformers , which has the same performance as OpenAI's embedding, can generate about 9,000 tokens per second. You mentioned you were able to do the embedding. Doing some basic math on rates and node types shows that self-hosted embedding is about 10x cheaper. However, this number is an approximate value because it is affected by load and embedded batch size.
6x: cost ratio of query between OpenAI base model and fine-tuned model
A fine-tuned model is six times more expensive than OpenAI's base model. This is a fairly exorbitant amount, but the basic model probably has a large difference because it is multi-tenancy . This also means that it is much more cost-effective to tune the base model prompts than to fine-tune the model.
1x: cost ratio between self-host based queries and fine-tuned model queries
If you are self-hosting your model, serving a fine-tuned model costs about the same as serving a base model. The models have the same number of parameters.
◆Training and fine tuning

About $ 1 million (about 137 million yen): Cost of training a model with 13 billion parameters with 1.4 trillion tokens
The LLaMa paper states that it took 21 days to train LLaMa using 2048 A100 80GB GPUs. So I calculated the numbers assuming you train your own model on the Red Pajama training set . The above assumes that everything went fine, nothing crashed, and the calculation succeeded the first time. In addition, 2048 GPUs need to work together. That's not something most companies can do. Training your own LLM is possible, but not cheap. And it literally takes days to complete each run. It's much cheaper to use pre-trained models.
0.001 or less: cost ratio between fine-tuning and training from scratch
This is a bit of a generalization, but the cost of fine-tuning is negligible. For example, a 6 billion parameter model can be fine-tuned for about $7 . Even Davinci, OpenAI's most expensive fine-tunable model, has a rate of 3 cents per 1000 tokens. In other words, it will cost $ 40 (about 5500 yen) to fine-tune the entire work of Shakespeare (about 1 million words).
◆ GPU memory edition

If you are self-hosting your model, LLM will push your GPU's memory to the limit, so understanding GPU memory is very important. The statistics below are specifically for inference. Training and fine-tuning require significantly more memory.
V100: 16GB, A10G: 24GB, A100: 40/80GB
It's important to know how much memory different types of GPUs have. This limits the number of parameters an LLM can have. In general, A10G is available for $1.50 to $2 (about 200 to 280 yen) per hour at the AWS On-Demand price, and has 24GB of GPU memory, so Mr. Kados likes to use A10G. matter. On the other hand, A100 costs about $ 5 (about 690 yen) per hour at the AWS on-demand price.
Twice the number of parameters: typical GPU memory requirements for LLM to serve
For example, if you have a model with 7 billion parameters, you will need about 14GB of GPU space. This is because in most cases you will need one 16-bit float per parameter, or 2 bytes. You usually don't need more than 16-bit precision, but in most cases, going to 8-bit precision starts to reduce resolution. Of course there are efforts to reduce precision, especially llama.cpp, which runs a 13 billion parameter model on a 6GB GPU by aggressively quantizing down to 4 bits, which is not common .
About 1GB: Typical GPU memory requirement for embedded models
Embedding models like
Embedded memory is usually pretty small, so you don't have to worry about how much it takes up on your GPU. Mr. Kados says that he has placed embedding and LLM on the same GPU.
Over 10x: LLM request batching increases throughput
Running LLM queries through the GPU has very long delays, but it is possible to reduce the delay by batching them. For example, consider a task that takes 5 seconds and a throughput of 0.2 queries per second. If I batch 2 tasks together, it takes something like 5.2 seconds, and if I can batch 25 queries, it takes about 10 seconds and a throughput of 2.5 queries per second. improve. However, be aware of the GPU memory limitations mentioned below.
About 1MB: GPU memory required for 1 token of output for 13B parameter model
The amount of memory required is directly proportional to the maximum number of tokens you generate. So, for example, if you want to generate an output of up to 512 tokens, you will need 512MB of memory. If you're using 24GB of memory, 512MB doesn't seem like much, but if you're doing batch processing, the required amount will increase by the amount of batch. For example, if you batch 16 tasks, you need 512MB x 16 tasks = 8GB of memory.
Related Posts:







in Software, Posted by log1d_ts