A library called 'GGML' that runs chat AI on a real home PC with no GPU required and 16GB of memory is currently under development, and a demo of voice recognition AI running on Raspberry Pi has already appeared.

Chat AIs such as those used in ChatGPT and
ggml.ai
http://ggml.ai/

ggerganov/ggml: Tensor library for machine learning
https://github.com/ggerganov/ggml
The features of GGML are as follows:
・Written in C
- Supports 16-bit float
- Supports 4-bit, 5-bit, and 8-bit integer quantization
・Automatic differentiation
- Equipped with optimization algorithms 'ADAM' and 'L-BFGS'
・Support and optimization for Apple Silicon
- Uses AVX and AVX2 on x86 architecture
Web support with WebAssembly, WASM, and SIMD
No third-party dependencies
-Do not use memory during operation
- Supports guided language output
The GGML code is available on GitHub , but with a bold warning: 'Please note that this project is under development.'

Although GGML is still under development, several demos have been released. For example, the video below shows how commands can be entered by voice using GGML and whisper.cpp . While this may seem like a normal example, what's amazing is that it runs on a lightweight PC called a Raspberry Pi.
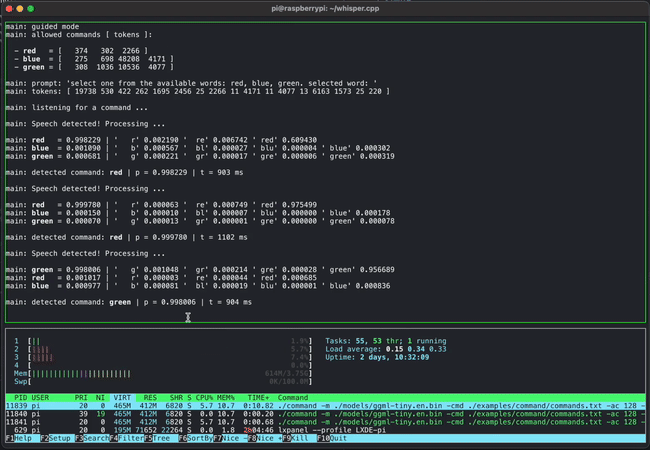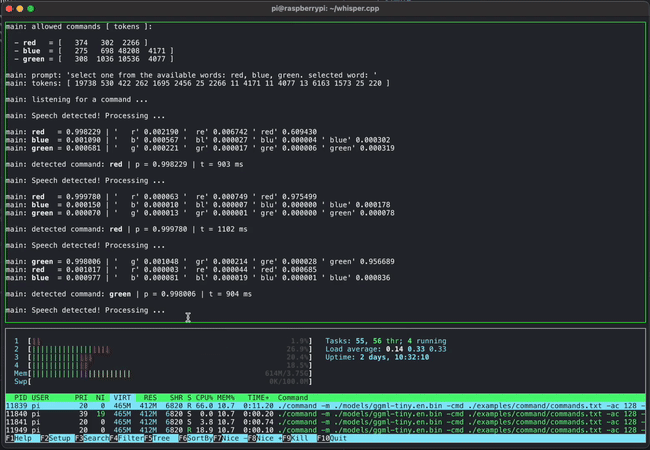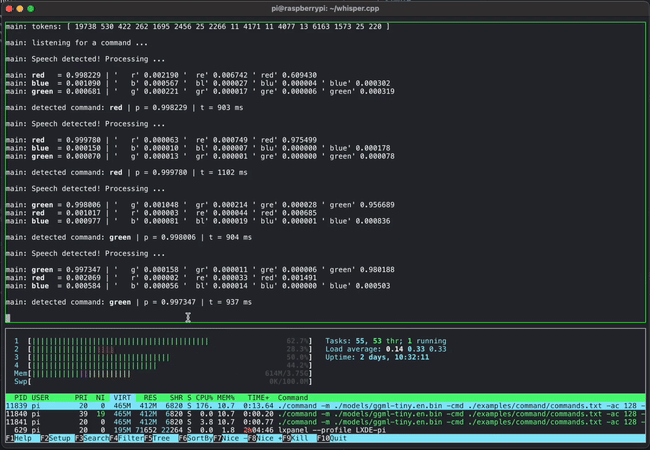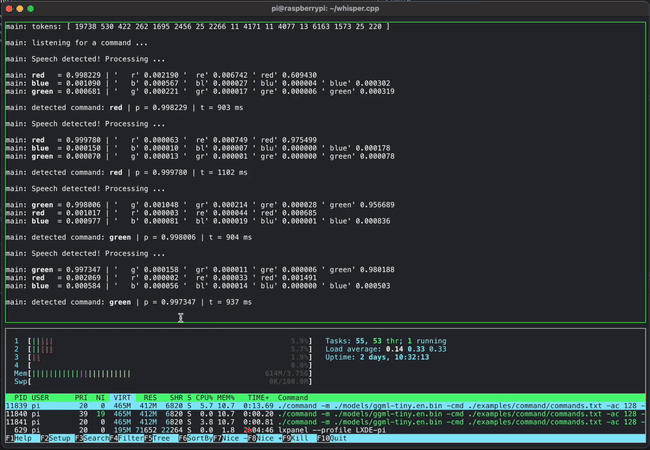
The article also includes a demo of four models combining 13 billion parameters (13B) of LLaMA and Whisper running simultaneously on an Apple M1 Pro , fully demonstrating the lightweight design.
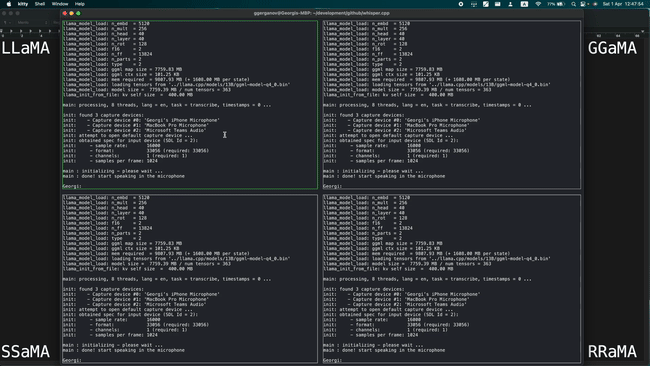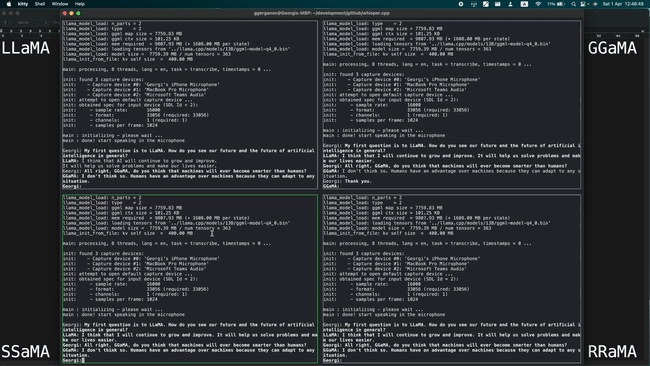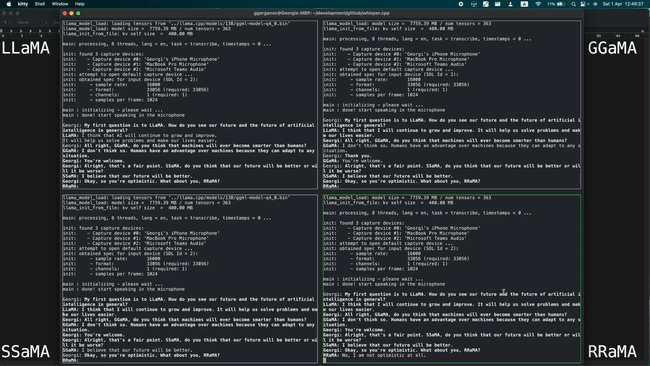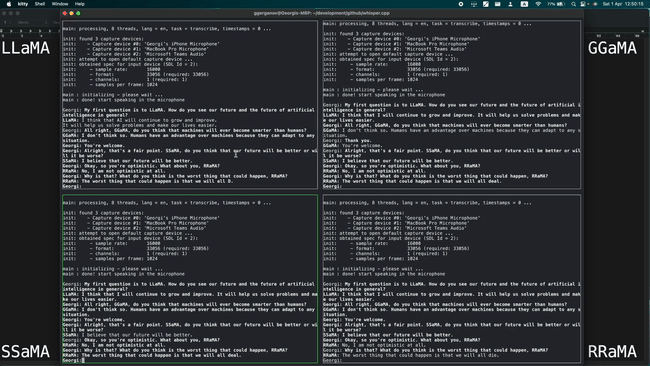
The Apple M2 Max running a 7 billion parameter (7B) LLaMA model can process 40 tokens per second, which is impressive.
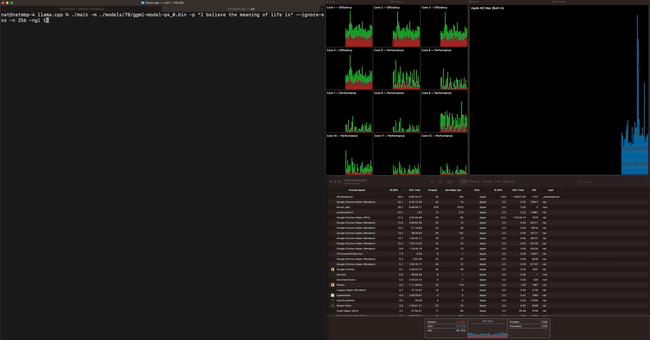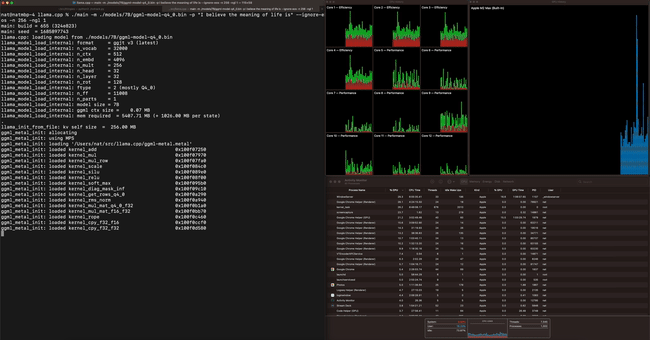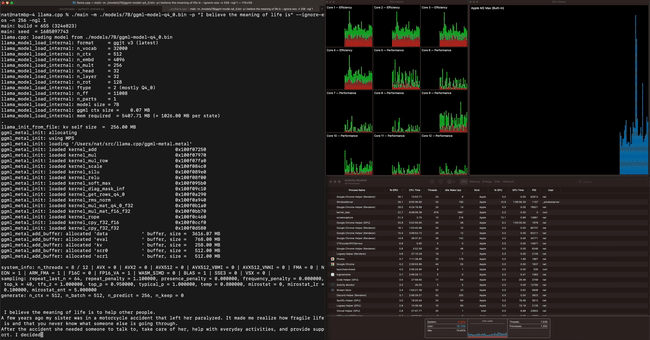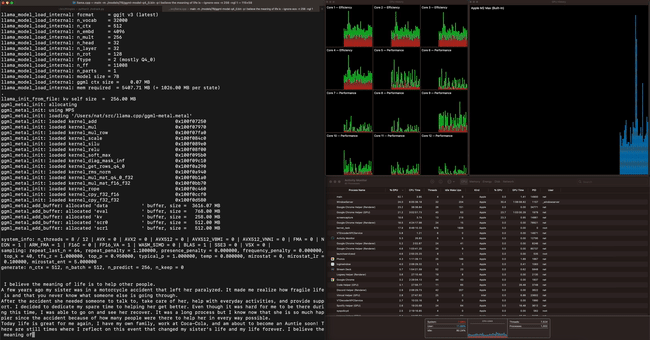
Other test results are as follows:
| Model | Machine | result |
|---|---|---|
| Whisper Small Encoder | M1 Pro: 7 CPU threads | 600 ms/run |
| Whisper Small Encoder | M1 Pro: ANE via Core ML | 200 ms/run |
| 7B LLaMA (4bit quantization) | M1 Pro, 8 CPU threads | 43 ms / token |
| 13B LLaMA (4bit quantization) | M1 Pro, 8 CPU threads | 73 ms / token |
| 7B LLaMA (4bit quantization) | M2 Max GPU | 25 ms / token |
| 13B LLaMA (4bit quantization) | M2 Max GPU | 42 ms / token |
GGML is available under the MIT license and is free for anyone to use. The development team is also looking for collaborators, stating that 'writing code and improving the library is the greatest support.'
We also tried to check whether it actually worked in our editorial department, but when we followed the instructions in the documentation, an error occurred during the build and we were unable to proceed.
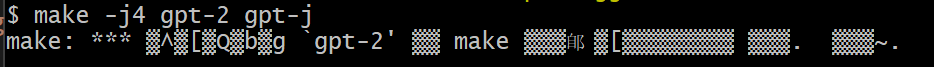
Related Posts: