Cerebras announces explosive AI inference service 22 times faster than NVIDIA H100, demo page also released so I tried it

Cerebras, a technology company developing AI processing processors, has announced a high-speed inference service called ' Cerebras Inference '. Cerebras Inference is 22 times faster than inference services using NVIDIA's H100, and costs one-fifth as much.
Inference - Cerebras
Introducing Cerebras Inference: AI at Instant Speed - Cerebras
https://cerebras.ai/blog/introducing-cerebras-inference-ai-at-instant-speed
AI-related computational processing can be broadly categorized into two parts: 'learning,' which builds an AI model, and 'inference,' which inputs prompts into the AI model to obtain output. Cerebras Inference is the service that handles the inference processing. The processing server for Cerebras Inference is built using Cerebras' proprietary chip, the WSE-3 , which enables high-speed inference processing.
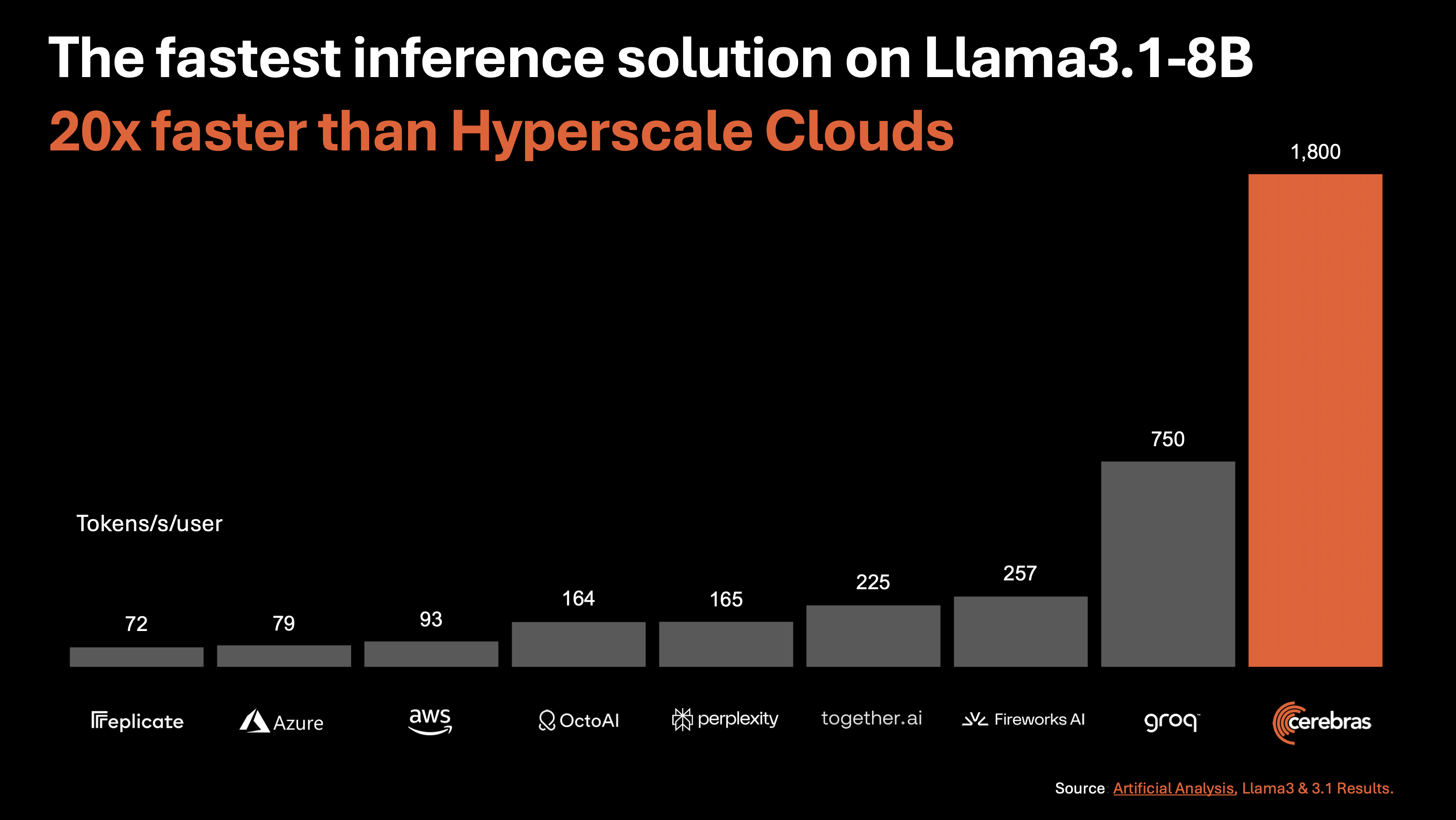
Below is a graph showing the 'number of tokens processed per user per second' for Cerebras Inference and other inference services. As a result of running the inference process of Llama 3.1 8B, Cerebras Inference has overwhelmingly higher inference performance than cloud inference services built with GPUs, and it is also capable of faster processing than the high-speed inference service ' Groq ' which uses a proprietary processor.
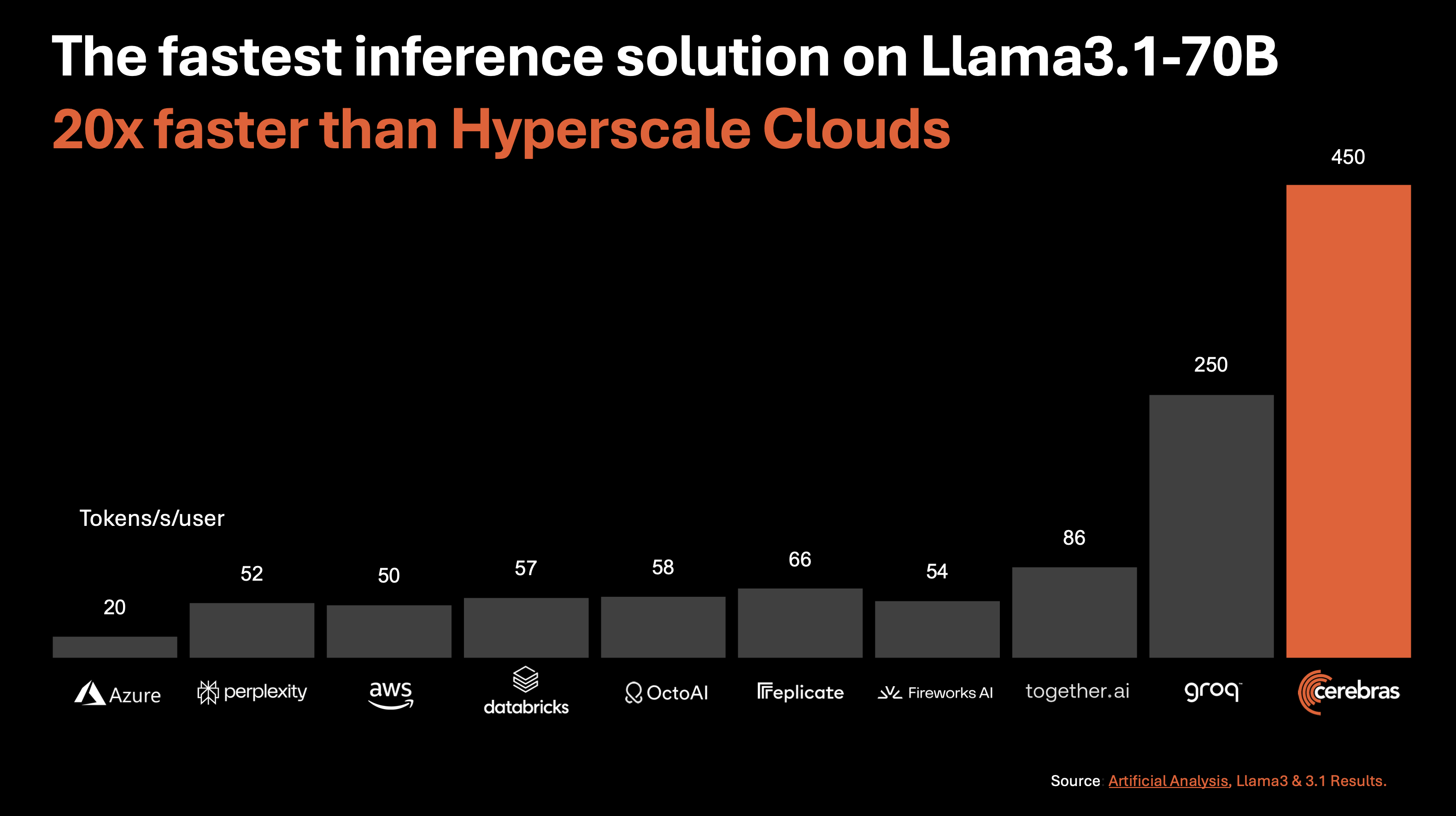
The Llama 3.1 70B also highlights the high performance of Cerebras Inference.
Here's a comparison of the performance and cost of Cerebras Inference with an inference service that uses the H100. The processing performance is 22 times that of the H100, and the cost is one-fifth of the H100.

On the following demo page, you can experience the performance of Cerebras Inference through chat with Llama 3.1 8B or Llama 3.1 70B. Please note that you will need to log in with your Google account or Microsoft account to run the demo.
Cerebras Inference
https://inference.cerebras.ai/
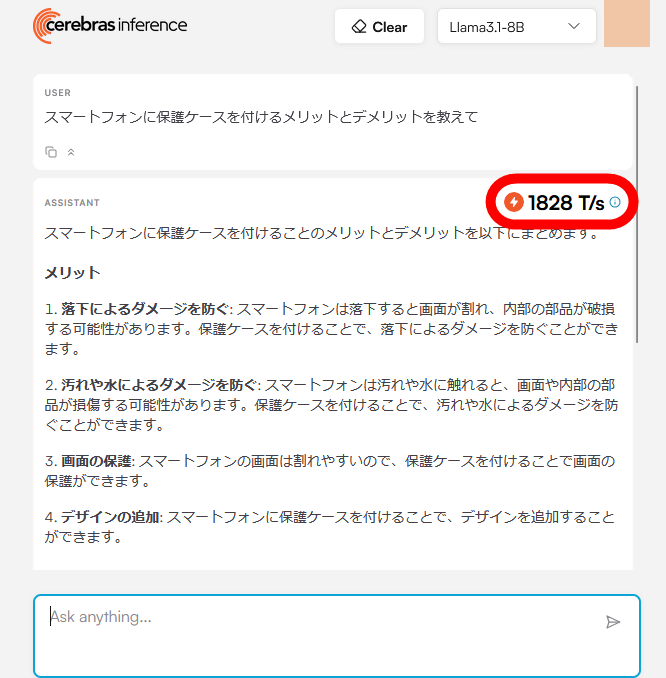
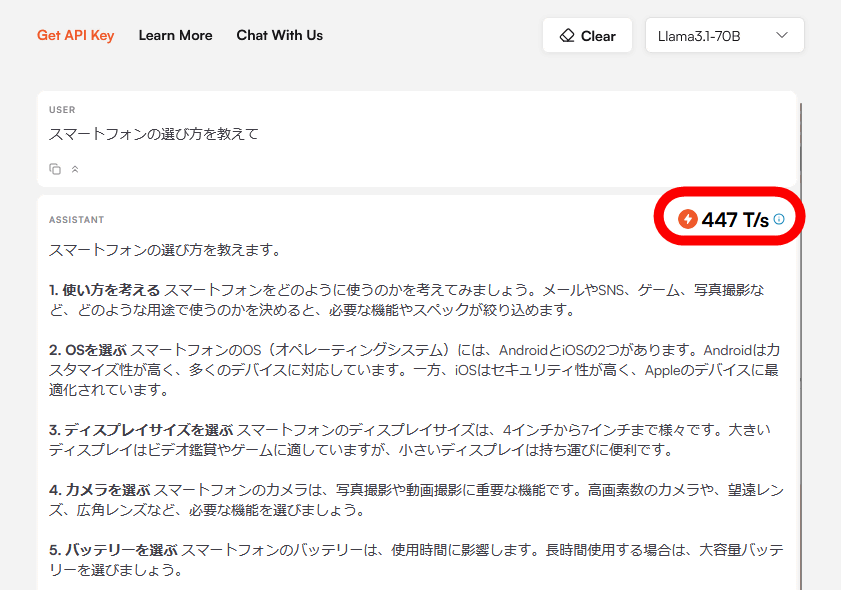
When I actually tried talking to Llama 3.1 8B, the response came back in an instant, and the top right corner of the response showed that it was able to process 1828 tokens per second.
You can change the language model in the dialog box at the top right of the screen. Switch to Llama 3.1 70B and try chatting.
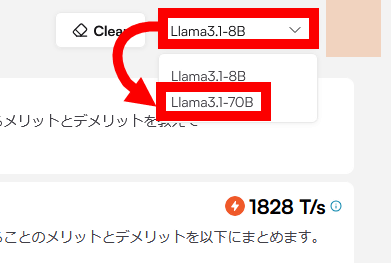
With Llama 3.1 70B, the tokens processed per second was 447.
Cerebras Inference's inference processing is extremely fast, and when you send a sentence, a reply is displayed in an instant. You can see how it actually talks to Llama 3.1 8B and Llama 3.1 70B in the video below.
Try a conversation with Llama 3.1 8B and Llama 3.1 70B with the explosive AI inference service 'Cerebras Inference' - YouTube
The fee for Cerebras Inference is 10 cents (about 14 yen) per million tokens for Llama 3.1 8B and 60 cents (about 87 yen) per million tokens for Llama 3.1 70B.
Related Posts:





in AI, Video, Hardware, Software, Web Service, Review, Web Application, Posted by log1o_hf