It is reported that AMD's AI specialized chip 'MI300X' demonstrated up to 2.1 times the performance performance in the same environment as NVIDIA chip 'H100'

AMD's AI-specialized chip '
AMD strikes back at Nvidia with new MI300X benchmarks — MI300X shows 30% higher performance than H100, even with an optimized software stack | Tom's Hardware
https://www.tomshardware.com/pc-components/gpus/amd-strikes-back-at-nvidia-with-new-mi300x-benchmarks-mi300x-shows-30-higher-performance-than-h100-even- with-an-optimized-software-stack
The AI-specialized chip ``MI300X'' announced by AMD on December 6, 2023 is appealing for the fact that the GPU unit of MI300X outperforms the H100 in many applications.

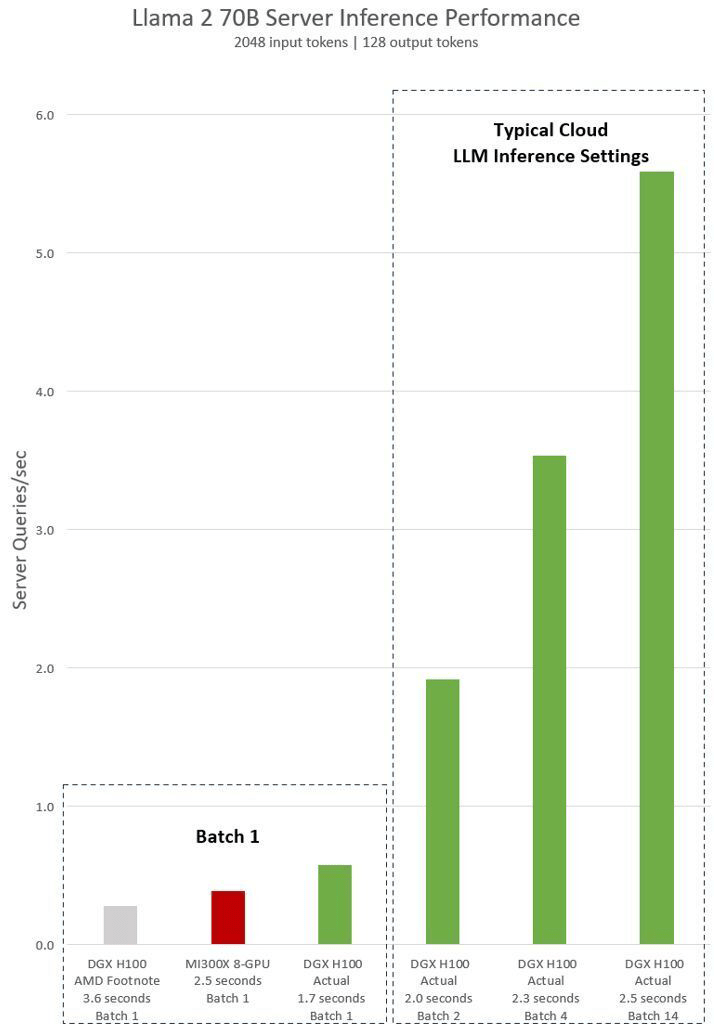
On the other hand, NVIDIA claims that ``When comparing the performance of MI300X and H100, we did not use the software `` TensorRT-LLM '' optimized for H100.'' With the right software, the H100's performance can exceed that of the MI300X.
According to NVIDIA, AI-specific chips such as the H100 are designed to operate optimally with NVIDIA's proprietary 'TensorRT-LLM', and that ' vLLM ', which is widely used in open source, may degrade performance. About.
Therefore, NVIDIA conducted a performance comparison between MI300X and H100 when using TensorRT-LLM. After comparing the number of queries that can be processed per second, it was reported that the H100 overwhelmingly outperformed the MI300X.
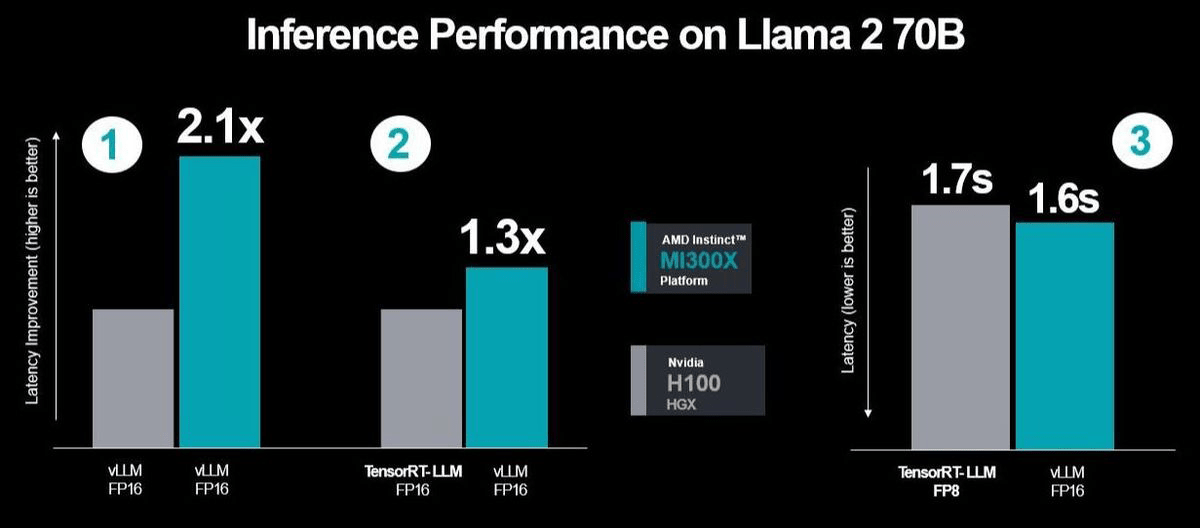
In response to this, AMD also conducted a test to compare the performance of MI300X and H100. According to AMD, when both use vLLM and compare at
Tom's Hardware, an overseas media outlet, says, ``It is up to NVIDIA to decide how to respond to this AMD performance test.''
Related Posts:







in Hardware, Posted by log1r_ut