Can AMD's AI specialized chip 'MI300X' surpass NVIDIA's chip 'H100' which is also used for ChatGPT?

On Wednesday, December 6, 2023, AMD announced the AI specialized chips 'MI300X' and 'MI300A.' AMD claims that MI300X exhibits superior performance compared to NVIDIA's AI specialized chip 'H100', but at the time of article creation, only the results of benchmarks conducted by AMD have been released. Meanwhile, semiconductor-related consultant Dylan Patel is analyzing how much performance MI300X has based on AMD's official materials.
AMD Instinct™ MI300 Series Accelerators
AMD MI300 Performance - Faster Than H100, But How Much?
https://www.semianalysis.com/p/amd-mi300-performance-faster-than
The 'performance difference between MI300X and H100 GPU units' that AMD is promoting is as follows. MI300X is touted for its superior performance over H100 in many applications.
| index | MI300X | H100 | Performance difference between MI300X and H100 |
|---|---|---|---|
| TBP | 750W | 700W | |
| Memory capacity | 192GB | 80GB | 2.4 times |
| memory bandwidth | 5.3TB/s | 3.3TB/s | 1.6 times |
| FP64 Matrix / DGEMM(TFLOPS) | 163.4 | 66.9(Tensor) | 2.4 times |
| FP32 Matrix / SGEMM(TFLOPS) | 163.4 | incompatible | |
| FP64 Vector / FMA64(TFLOPS) | 81.7 | 33.5 | 2.4 times |
| FP32 Vector / FMA32(TFLOPS) | 163.4 | 66.9 | 2.4 times |
| TF32(Matrix) | 653.7 | 494.7 | 1.3 times |
| TF32 w// Sparsity(Matrix) | 1307.4 | 989.4 | 1.3 times |
| FP16(TFLOPS) | 1307.4 | 133.8|989.4(Tensor) | 9.8x|1.3x |
| FP16 w/Sparsity(TFLOPS) | 2614.9 | 1978.9(Tensor) | 1.3 times |
| BFLOAT16(TFLOPS) | 1307.4 | 133.8|989.4(Tensor) | 9.8x|1.3x |
| BFLOAT16 w/Sparsity(TFLOPS) | 2614.9 | 1978.9(Tensor) | 1.3 times |
| FP8(TFLOPS) | 2614.9 | 1978.9 | 1.3 times |
| FP8 w/Sparwity(TFLOPS) | 5229.8 | 3957.8(Tensor) | 1.3 times |
| INT8(TOPS) | 2614.9 | 1978.9 | 1.3 times |
| INT8 w/Sparsity(TOPS) | 5229.8 | 3957.8(Tensor) | 1.3 times |
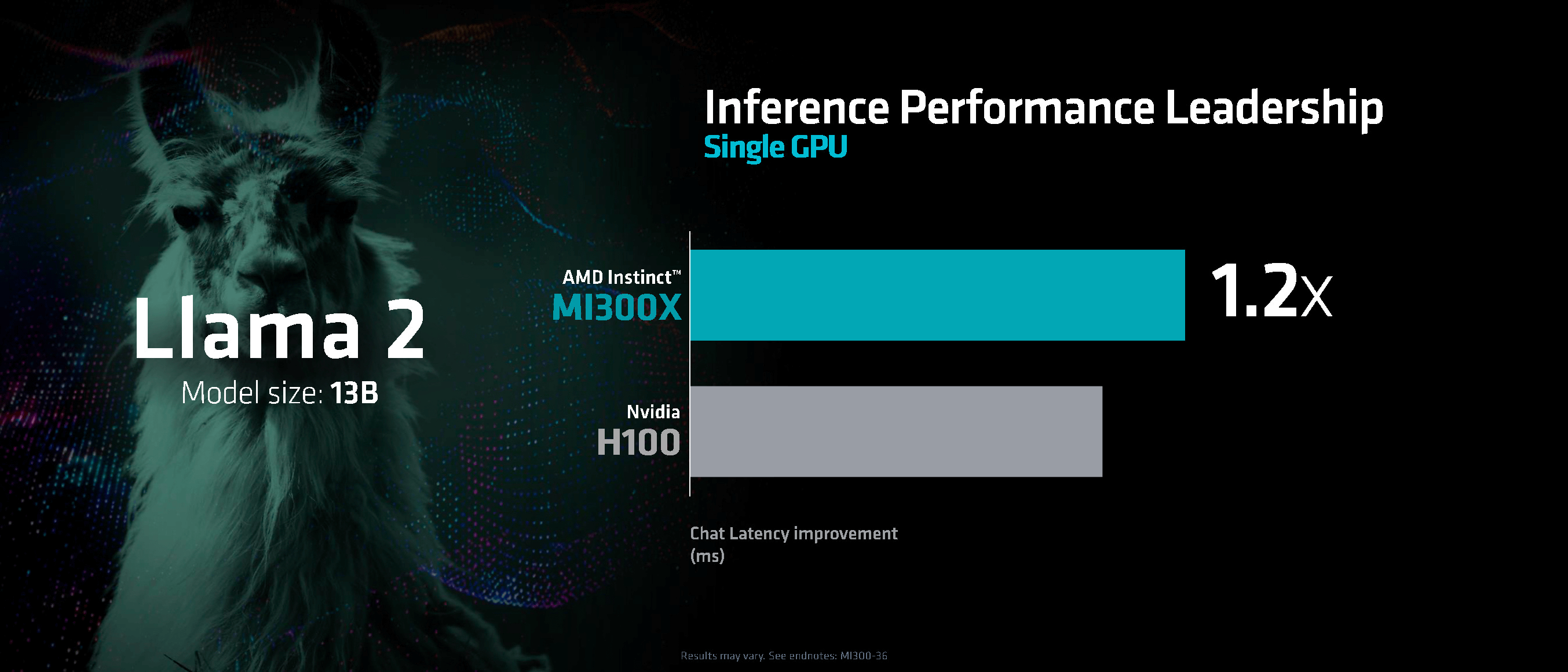
AMD presents performance comparison results on Llama 2-70B and Bloom to show the performance difference between MI300X and H100. Of these, Bloom shows that MI300X has 1.6 times the performance of H100, but Mr. Patel says, ``Bloom test results are greatly influenced by memory capacity, but in an actual environment, the throughput caused by the difference in memory capacity is The scenarios we focus on are limited.'

MI300X is said to exhibit 1.2 times the performance of H100 in Llama2-13B. Mr. Patel acknowledges the high performance of MI300X based on the fact that 'MI300X is cheaper than H100.' Furthermore, given that much of the existing AI-related software is optimized for operation with NVIDIA chips, he points out that ``If software optimization progresses, the MI300X may exhibit even greater performance.'' I am.
On the other hand, Mr. Patel also points out that the AI-specific chip `` H200 '' announced by NVIDIA in November 2023 may have better performance than MI300X.
Related Posts:








in Hardware, Posted by log1o_hf