It is shown that Meta's 'LLaMA', a rival of GPT-3, can be executed on M1-equipped Mac, and large-scale language models can be executed on ordinary consumer hardware

As interest in the use of AI (artificial intelligence) in everyday life increases, large-scale language models (LLMs) such as OpenAI's GPT-3 and Microsoft's
GitHub - ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++
https://github.com/ggerganov/llama.cpp
l1x/dev | Using LLaMA with M1 Mac
https://dev.l1x.be/posts/2023/03/12/using-llama-with-m1-mac/
LLaMA is an LLM announced by Meta AI Research, Meta's AI research organization. The number of parameters indicating the size of LLM is 7 billion to 65 billion, and the result of the benchmark test of LLaMA's 13B (13 billion parameters) model is reported to be comparable to GPT-3 with 175 billion parameters.
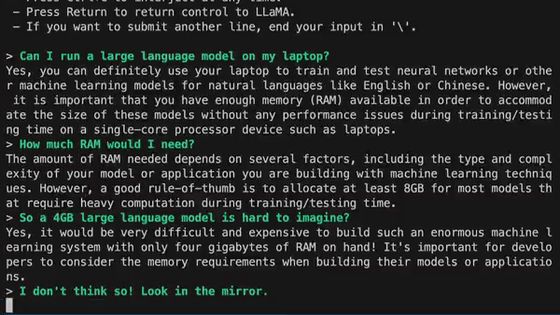
Also, unlike GPT-3, which is difficult to operate unless it is in a data center environment that uses multiple AI-optimized accelerators, LLaMA worked without problems even with a single GPU, so it can be used in a consumer-level hardware environment. It was also suggested that interactive AI such as ChatGPT could be operated.
Meta announces large-scale language model 'LLaMA', can operate with a single GPU while having performance comparable to GPT-3 - GIGAZINE

This LLaMA was published in the form that only a part of the code was hosted on GitHub, and the complete code including the weighting data could be received by contacting Meta AI Research. However, one week after the release, LLaMA's model data leaked to 4chan, an online bulletin board site.
Data of Meta's large-scale language model 'LLaMA-65B' leaked at 4chan - GIGAZINE

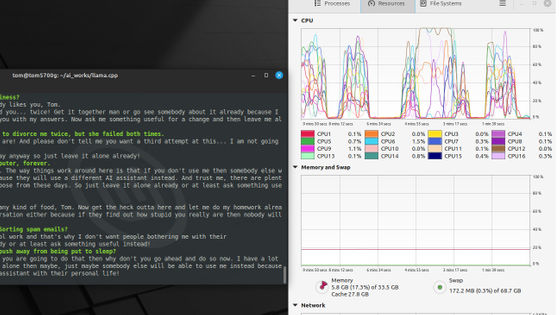
Mr. Gerganov is developing a project 'llama.cpp' that runs inference using LLaMA on macOS, Linux, and Windows, and said that he succeeded in running LLaMA on a MacBook Pro with M1.
Mr. Gerganov reports that LLaMA's 13B (13 billion parameters) model can be operated on a Mac with M1 at a processing speed of 10 tokens per second.
Just added support for all LLaMA models
— Georgi Gerganov (@ggerganov) March 11, 2023
I'm out of disk space, so if someone can give this a try for 33B and 65BB would be great ????
See updated instructions in the Readme
Here is LLaMA-13B at ~10 tokens/s https://t.co/kkhKR6ZHjO pic.twitter.com/NIIvJrRqwq
A movie actually running LLaMA's 65B (65 billion parameters) model with M1-equipped MacBook Pro (memory 64GB) is published in the following tweet.
65B running on m1 max/64gb!
— Lawrence Chen (@lawrencecchen) March 11, 2023
In addition, we have also released a demo on GitHub that simultaneously runs LLaMA's 7B (7 billion parameters) model and OpenAI's high-performance transcription AI `` Whisper '' on a single M1-equipped MacBook Pro. By clicking on the thumbnail below, you can see a movie showing how both LLaMA-7B and Whisper are actually running on the M1-equipped MacBook Pro.
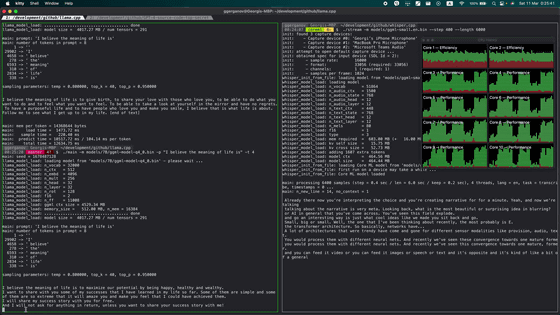
In addition, 'llama.cpp' is compatible with macOS and Linux at the time of article creation, and it is said that Windows is not yet compatible, but already in a 64-bit Windows environment (Intel Core i7-10700T, memory 16GB) It was reported to work and used only 5GB of memory.
Windows 64-bit, Microsoft Visual Studio - it works like a charm after those fixes! · Issue #22 · ggerganov/llama.cpp · GitHub
https://github.com/ggerganov/llama.cpp/issues/22
Related Posts: