Meta announces large-scale language model 'LLaMA', performance comparable to GPT-3 but can operate on a single GPU

Meta AI
LLaMA: Open and Efficient Foundation Language Models - Meta Research
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
Meta unveils a new large language model that can run on a single GPU [Updated] | Ars Technica
https://arstechnica.com/information-technology/2023/02/chatgpt-on-your-pc-meta-unveils-new-ai-model-that-can-run-on-a-single-gpu/
The number of parameters of LLaMA is 7 billion to 65 billion, and it is learning with publicly available datasets such as Wikipedia, Common Crawl , and C4 . 'Unlike GPT-3, DeepMind's Chinchilla , and Google's PaLM , LLaMA only uses publicly available datasets and is open-source compatible with reproducible work,' said Guillaume Lample, a researcher at Meta AI Research. 'Most existing models are trained using unpublished or undocumented data.'
Unlike Chinchilla, PaLM, or GPT-3, we only use datasets publicly available, making our work compatible with open-sourcing and reproducible, while most existing models rely on data which is either not publicly available or undocumented.
— Guillaume Lample (@GuillaumeLample) February 24, 2023
2/n pic.twitter.com/BNz9oHqblZ
Also, according to Meta AI Research, LLaMA-13B with 13 billion parameters was run on a single GPU, and ``common sense reasoning'' was measured with eight benchmarks: BoolQ , PIQA , SIQA , HellaSwag , WinoGrande , ARC , and OpenBookQA . , Some themes showed performance exceeding GPT-3 with 175 billion parameters.
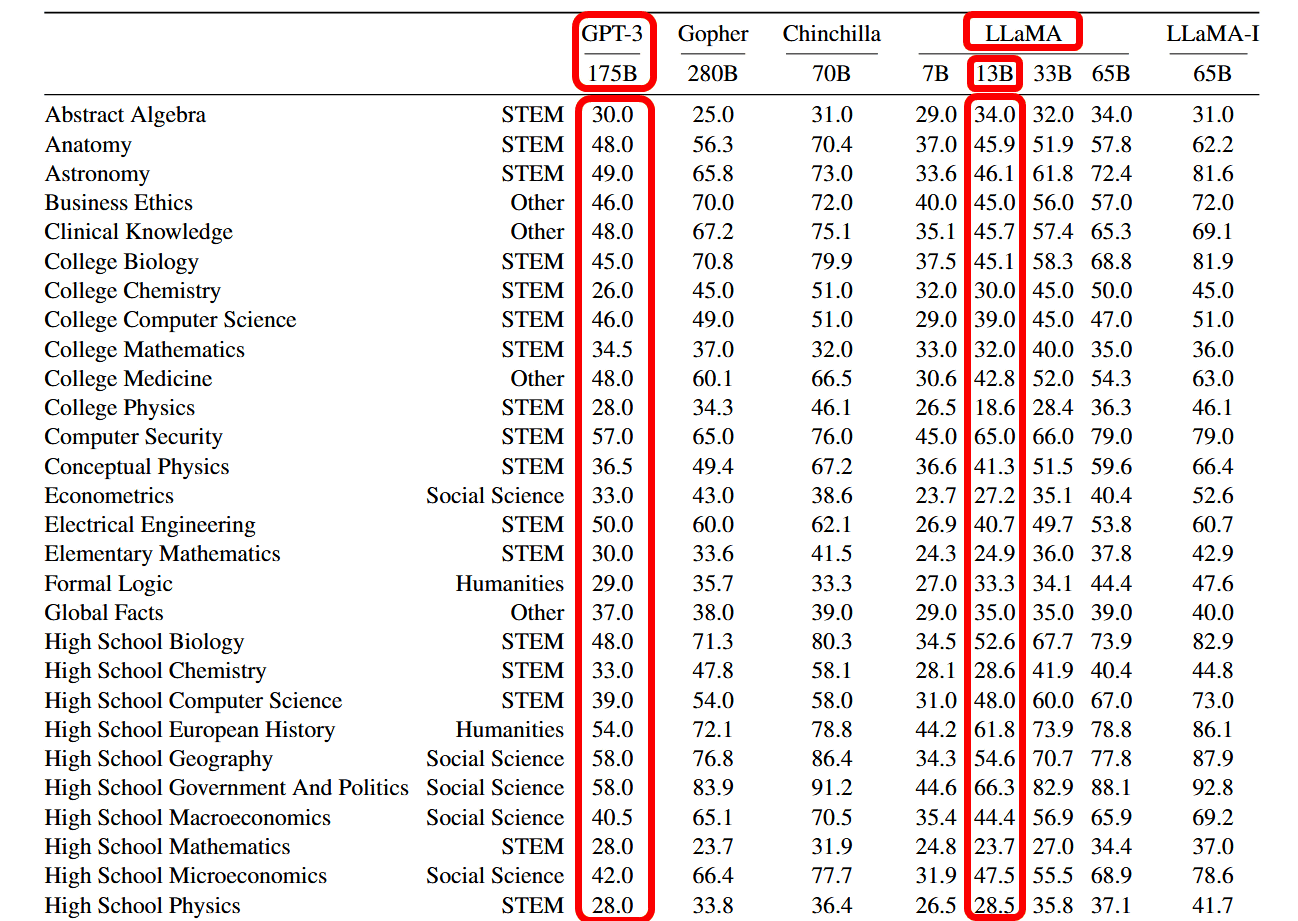
The number of parameters is the amount of variables (parameters) used by the machine learning model to make predictions and classifications based on the input data, and is an important factor that affects the performance of the model. A larger number of parameters can handle more complex tasks and produce stable output, but the larger the number of parameters, the larger the size of the model itself and the more computational resources it requires.
LLaMA-13B, which ``showed the same performance as GPT-3 with an overwhelmingly smaller number of parameters than GPT-3,'' can be said to have better cost performance than GPT-3. Also, while GPT-3 does not work without using multiple AI-optimized accelerators, LLaMA-13B worked without problems even with a single GPU, so even in a consumer-level hardware environment, ChatGPT will not work. It is possible to move AI.
Meta AI Research considers LLaMA to be the 'basic model', which will serve as the foundation for Meta's natural language processing model in the future, 'question answering, natural language understanding or reading comprehension, understanding the capabilities and limitations of current language models.' , and potentially enhance their applications.
Although LLaMA is not scheduled to be released to the public at the time of writing the article, part of the simple inference model by LLaMA is published on GitHub, and the complete code and weights learned by the neural network are available on Google Form You can download it by contacting Meta AI Research through
GitHub - facebookresearch/llama: Inference code for LLaMA models
https://github.com/facebookresearch/llama
Related Posts:







in Software, Posted by log1i_yk