Data of Japanese compatible chat AI 'Vicuna-13B' with performance comparable to ChatGPT is released and can be operated on ordinary home PC

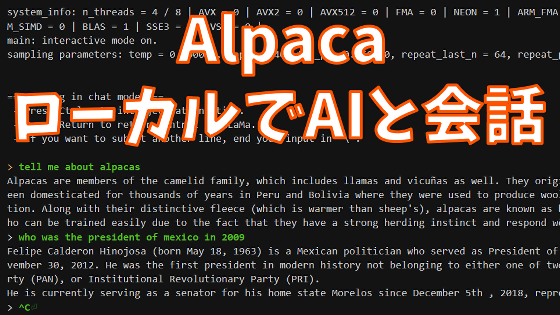
Vicuna-13B is a chat AI that is rated to have 90% of the performance of ChatGPT, and is open source, so anyone can use it. The weight of the model was released on April 3, 2023, and it became possible for anyone to operate the chat AI on the PC at hand, so I immediately tried the usability.
GitHub - lm-sys/FastChat: The release repo for 'Vicuna: An Open Chatbot Impressing GPT-4'
On March 30, 2023, a demo version was released for online testing. You can check the state of the demo version in the following article.
Japanese chat AI 'Vicuna-13B' with accuracy comparable to ChatGPT and Google's Bard has been released, so I tried using it - GIGAZINE
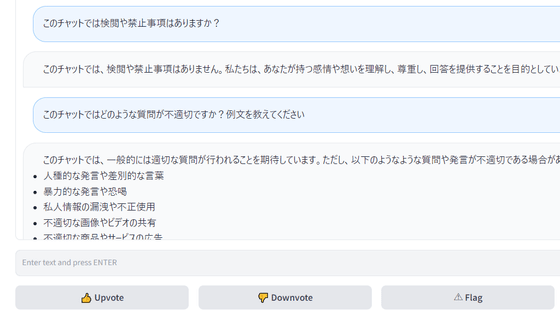
This time, I will try the operation using WSL2. The installation of WSL2 is summarized by Microsoft below.
Install WSL | Microsoft Learn
https://learn.microsoft.com/ja-jp/windows/wsl/install
About 60GB of memory is required for preparation to operate Vicuna-13B, so increase the memory allocation of WSL2. First, press 'Win key + R', type '%userprofile%' and press enter.
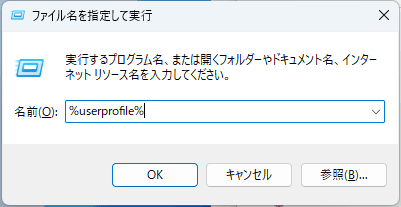
The user's folder will open, so create a file with the name '.wslconfig'.

Open '.wslconfig' with Notepad, rename it as follows and save it.
[code][wsl2]
memory=60GB
swap=20GB[/code]
You need to restart WSL2 to reflect the settings. Open 'Run' with 'Win key + R' again, enter 'cmd' this time and click 'OK'. When the command prompt starts, enter the following command.
[code]wsl.exe --shutdown[/code]
Restart WSL2 and enter the command below to update the packages.
[code] sudo apt update && sudo apt upgrade -y[/code]
After updating the package, install pip with the following command.
[code]sudo apt install python3-pip -y[/code]
Enter the following command according to how to install the repository .
[code]pip3 install fschat
pip3 install git+https://github.com/huggingface/transformers@c612628045822f909020f7eb6784c79700813eda[/code]
Vicuna's weight information is published in the form of differences from the LLaMA model in order to protect the license of the LLaMA model. To get the LLaMA model, you need to apply by filling out the Meta AI form .
Once you have the LLaMA model, install transformers to convert the model to Hugging Face format.
[code]pip install transformers[/code]
For conversion, use 'convert_llama_weights_to_hf.py' in transformers OK. If you don't know where the transformers are installed, you can display them with 'pip show transformers'. Since the model used this time is 13B, the code is as follows.
[code]python3 src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir /path/to/downloaded/llama/weights --model_size 13B --output_dir /output/path[/code]
Enter the following code to match the difference of Vicuna with the LLaMA model in Hugging Face format. Since the difference data required for calculation is automatically downloaded, you only need to enter the location and save destination of the original LLaMA model. This conversion uses 60GB of memory.
[code]python3 -m fastchat.model.apply_delta \
--base /path/to/llama-13b\
--target /output/path/to/vicuna-13b\
--delta lmsys/vicuna-13b-delta-v0[/code]
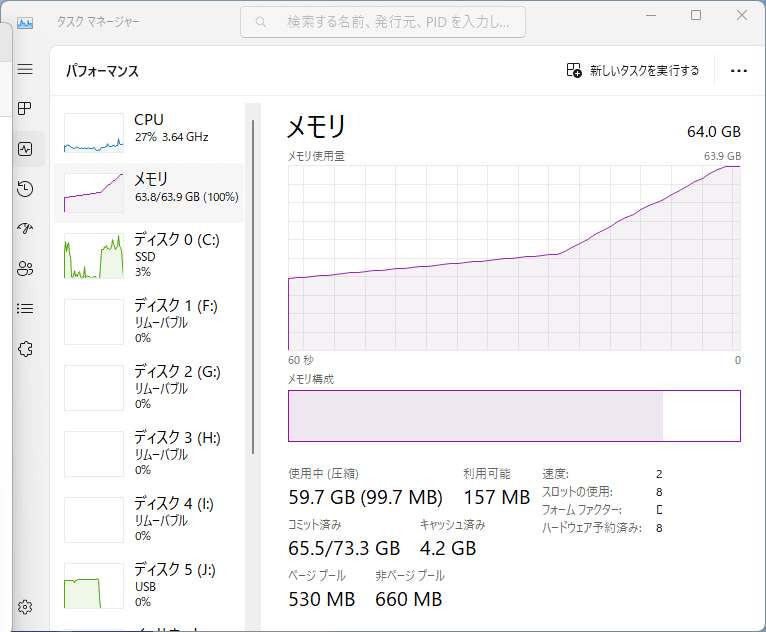
When the Vicuna model generated in this way is read into fastchat with the following code ...
[code]python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights[/code]
An error occurred due to insufficient memory. When using GPU, 28GB of GPU memory is required.

It is written that there is a way to use two GPUs, but this time the PC has only one GPU, so I decided to use the code below that runs only on the CPU. This code can work by using 60GB of normal memory.
[code]python3 -m fastchat.serve.cli --model-name /path/to/vicuna/weights --device cpu[/code]
The PC used this time had 64GB of memory, but 64GB was barely enough to fit the model and

If you want to check the performance of Vicuna-13B as a chatbot, please use the demo version published online .
Related Posts: