I tried using the library ``Lit-Parrot'' on Google Cloud Platform that can easily fine-tune a large-scale language model like GPT with its own dataset

Fine-tuning is used to steer the output of a large language model in a particular direction, such as increasing knowledge about a particular domain, which takes far less data than building the model from scratch. It's a technique that can be trained on set & much less cost. ' Lit-Parrot ' is a library that makes fine tuning easy, so I tried using it to see how easy it is.
lit-parrot/scripts at main Lightning-AI/lit-parrot GitHub
How To Finetune GPT Like Large Language Models on a Custom Dataset - Lightning AI
https://lightning.ai/pages/blog/how-to-finetune-gpt-like-large-language-models-on-a-custom-dataset/
A machine with 32GB or more of memory and 12GB or more of GPU memory is required for fine-tuning. This time, we will prepare a virtual machine on Google Cloud Platform (GCP). Open the GCP console , select 'Compute Engine' from the top left menu, and click 'VM Instances'.

Click 'Create Instance'.
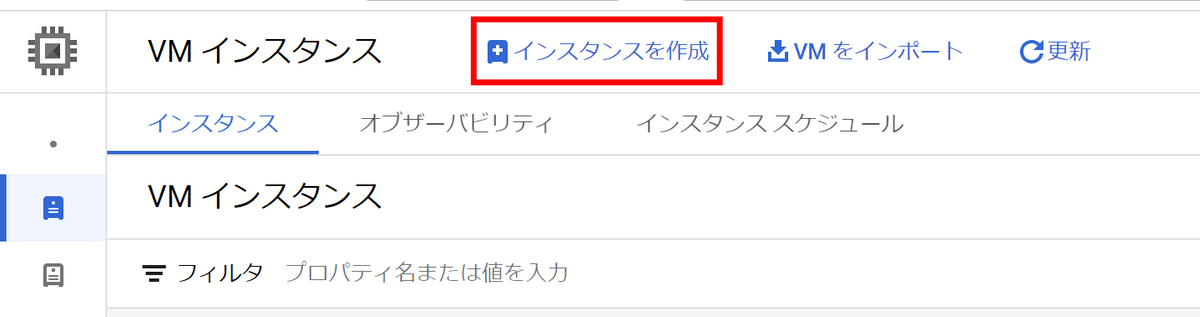
Give it a descriptive name and set the zone to 'asia-northeast1-a'. GPUs that can be used are different depending on this zone selection.
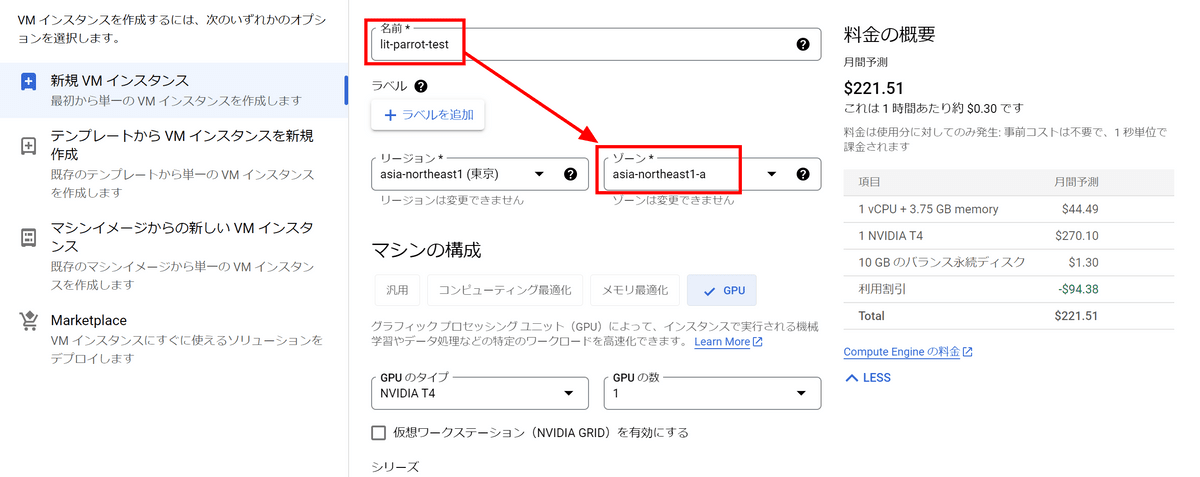
Lit-Parrot fine-tuning requires a GPU that supports
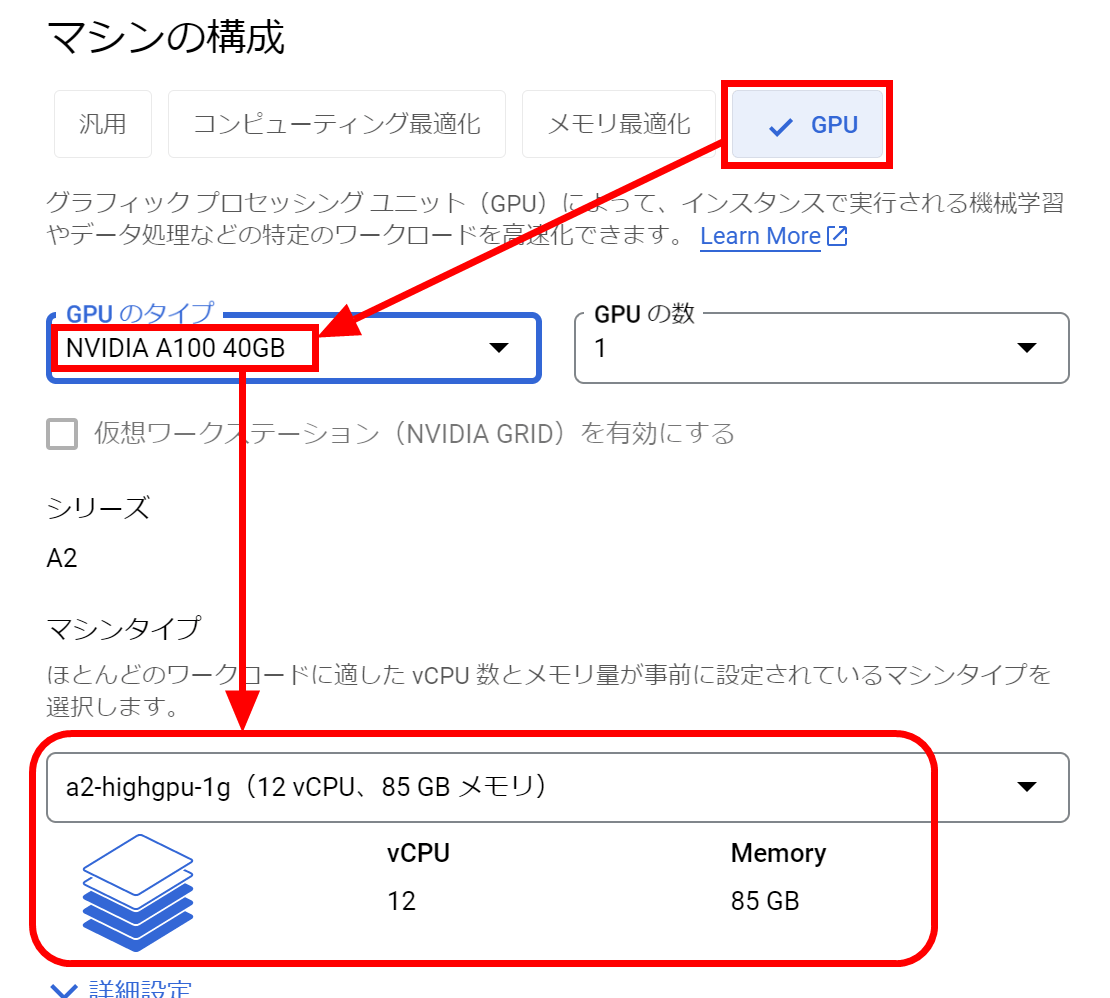
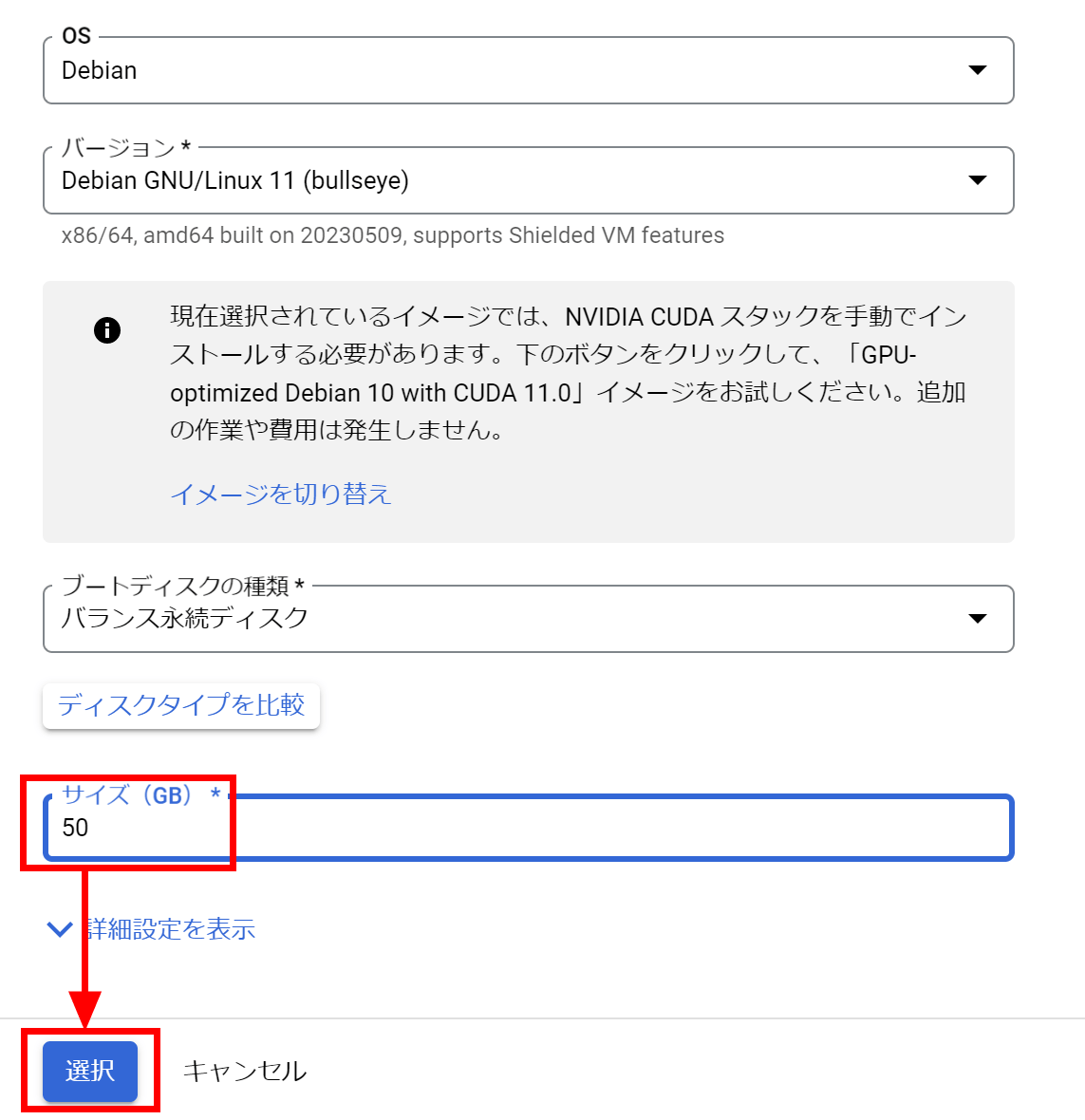
The disk capacity is small, so change it. Click 'Change'.
Change the size to 50GB and click Select. Although GCP provides an image with CUDA preinstalled, it does not match the version of CUDA you want to use, so this time you will install CUDA manually.
The usage fee for the A100 GPU is quite high, so we will take some measures. Click to open Advanced Options, then click Manage.
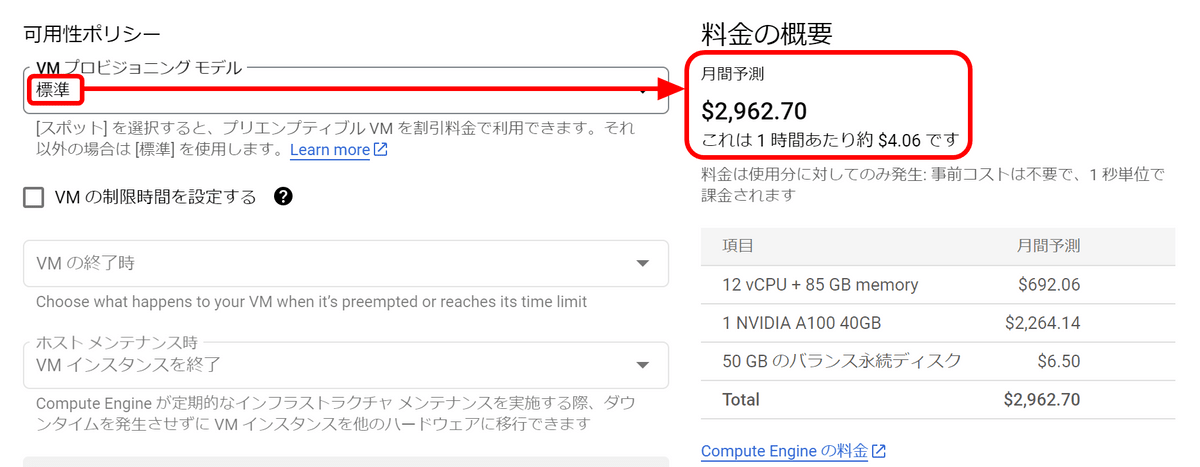
'VM Provisioning Model' in 'Availability Policy' is standard. Currently, it costs $ 4.06 (about 570 yen) per hour.
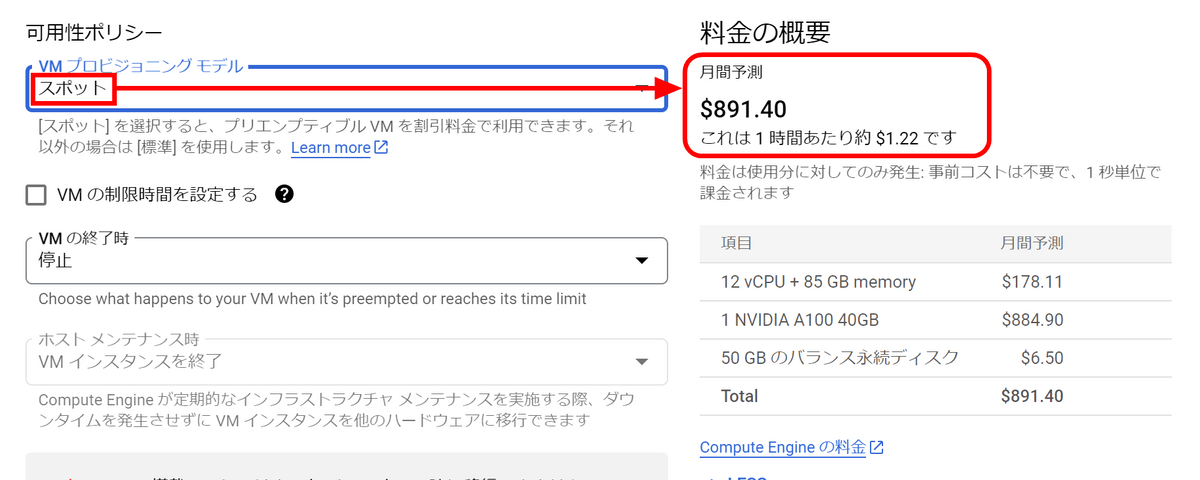
Changing this to 'spot' lowered the hourly rate to $ 1.22 (about 170 yen). Of course, by making it a spot, there is a possibility that it will be shut down suddenly due to Google's convenience, but this time it will only start for a short time for fine tuning, and it will not handle data that will cause problems if it ends in the middle. So it seems that there is no problem.
Leave other settings as default and click 'Create'.

When there is a green check mark in the status column, click 'SSH' to connect to the server.

Since the SSH screen opens in the browser, we will enter the command from here.
First, update each package with the code below.
[code] sudo apt update && sudo apt upgrade -y[/code]
Install pip and git with the following commands.
[code]sudo apt install python3-pip git -y[/code]
Install the GPU driver and CUDA with the following command, referring to the '
[code]curl https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-installation/main/linux/install_gpu_driver.py --output install_gpu_driver.py
sudo python3 install_gpu_driver.py[/code]
This completes the environment construction. Clone the Lit-Parrot repository with the command below.
[code]git clone https://github.com/Lightning-AI/lit-parrot.git
cd lit-parrot[/code]
Lit-Parrot uses a function that is only installed in the nightly version of PyTorch at the time of writing the article, so install it separately from the normal library with the following command.
[code]pip install --index-url https://download.pytorch.org/whl/nightly/cu121 --pre 'torch>=2.1.0dev'[/code]
Then install the other libraries together with the following command.
[code]pip install -r requirements.txt[/code]
Also, a library for downloading models from Hugging Face is required, so install it separately.
[code]pip install huggingface-hub[/code]
This time, we will use Base-3B-v1 of 'RedPajama-INCITE' as the original model for fine tuning. RedPajama is explained in the article below.
Open source large-scale language model development project ``RedPajama'' releases the first model ``RedPajama-INCITE'', free for commercial use - GIGAZINE

Enter the code below to automatically download the model.
[code]python3 scripts/download.py --repo_id togethercomputer/RedPajama-INCITE-Base-3B-v1[/code]
After the model download is complete, format the weight information in Lit-Parrot format with the following command.
[code]python3 scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1[/code]
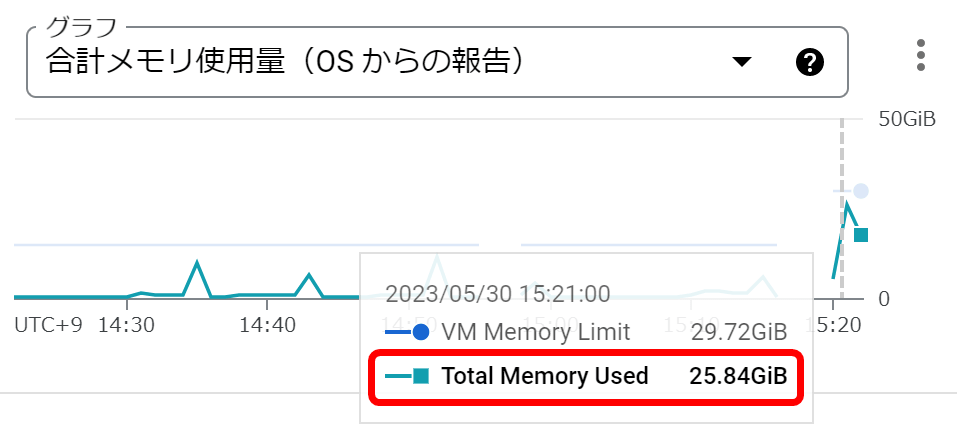
This process required about 26GB of normal memory.
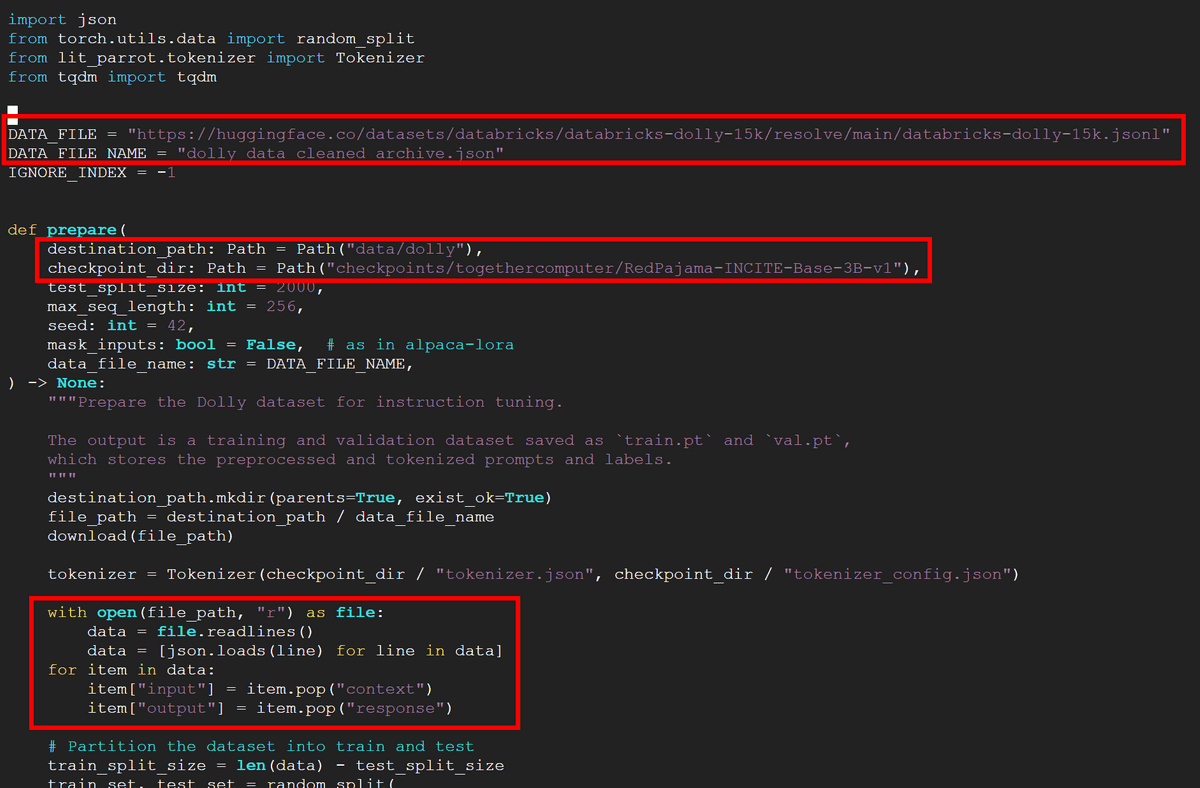
Enter the code below and open prepare_alpaca.py in a text editor to set fine tuning.
[code]vi scripts/prepare_alpaca.py[/code]
As the training data for fine-tuning, we use the high-quality dataset 'databricks-dolly-15k' used for fine-tuning 'Dolly 2.0'. Dolly 2.0 is explained in the following article.

Set DATA_FILE described in prepare_alpaca.py to the URL where databricks-dolly-15k is hosted, and rewrite checkpoint_dir to RedPajama directory prepared earlier. Furthermore, in databricks-dolly-15k, the names of input and output are 'context' and 'response', so add code to rewrite them to 'input' and 'output' respectively.
Execute prepare_alpaca.py with the code below to prepare for fine tuning.
[code]python3 scripts/prepare_alpaca.py \
--destination_path data/dolly \
--checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1[/code]
And start fine-tuning with the code below.
[code]python3 finetune_adapter.py \
--data_dir data/dolly \
--checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1 \
--out_dir out/adapter/dolly[/code]
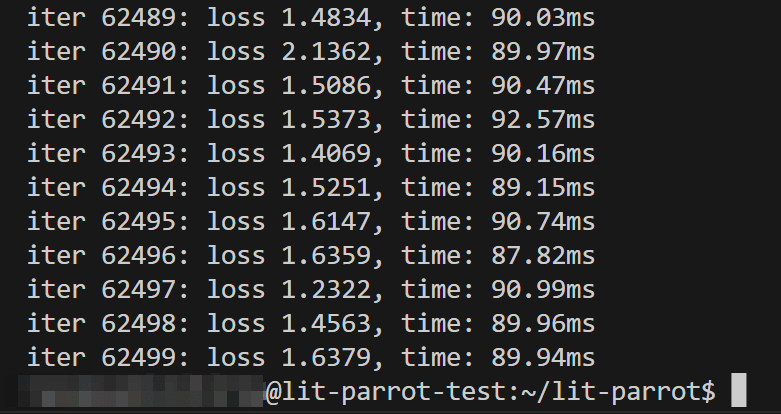
Fine tuning was completed in about 2 hours using A100 40GB GPU.
Enter the code below and try the response in the fine-tuned model.
[code]python3 generate_adapter.py \
--adapter_path out/adapter/dolly/lit_model_adapter_finetuned.pth \
--checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1 \
--prompt '[type your question here]'[/code]
For example, when I asked the question, 'Who is the author of Game of Thrones?', the answer was 'George RR Martin' as follows.
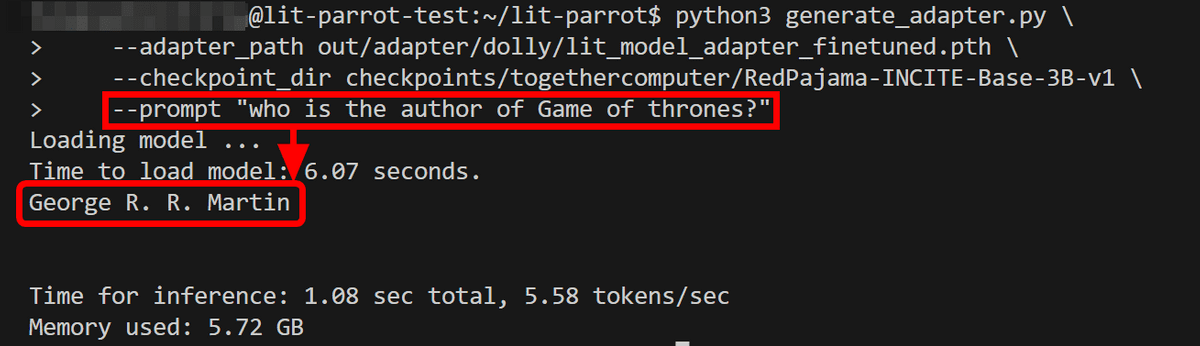
The 'databricks-dolly-15k' dataset used for fine tuning contains information on Game of Thrones, and this information was learned to generate a response.

Of course, you can't answer correctly for information that isn't included in your dataset. When I asked for an explanation about GIGAZINE as a trial, I got a reply saying 'Monthly digital magazine about music'.

Related Posts:




in Software, Web Service, Review, Posted by log1d_ts