How to easily run 'llamafile', a system that allows you to easily distribute and run AI using large-scale language models with just one executable file of only 4 GB, on Windows and Linux

' llamafile ' is a file format that contains model and weight information of a large-scale language model in one executable file. It is said that it is possible to run a large-scale language model without installation on six OSes: Linux, macOS, Windows, FreeBSD, NetBSD, and OpenBSD, so it is actually possible to run it on Debian, which is one of the Windows and Linux distributions. I tried moving it.
Mozilla-Ocho/llamafile: Distribute and run LLMs with a single file.
Introducing llamafile - Mozilla Hacks - the Web developer blog
https://hacks.mozilla.org/2023/11/introducing-llamafile/
The models distributed in llamafile format are as follows. This time, we will try to operate 'LLaVA 1.5', a model that can recognize images.
| Model | License | Command-line llamafile | Server llamafile |
|---|---|---|---|
| Mistral-7B-Instruct | Apache 2.0 | mistral-7b-instruct-v0.1-Q4_K_M-main.llamafile (4.07 GB) | mistral-7b-instruct-v0.1-Q4_K_M-server.llamafile (4.07 GB) |
| LLaVA 1.5 | LLaMA 2 | (Not provided) | llava-v1.5-7b-q4-server.llamafile (3.97 GB) |
| WizardCoder-Python-13B | LLaMA 2 | wizardcoder-python-13b-main.llamafile (7.33 GB) | wizardcoder-python-13b-server.llamafile (7.33GB) |
◆I tried running it on Windows
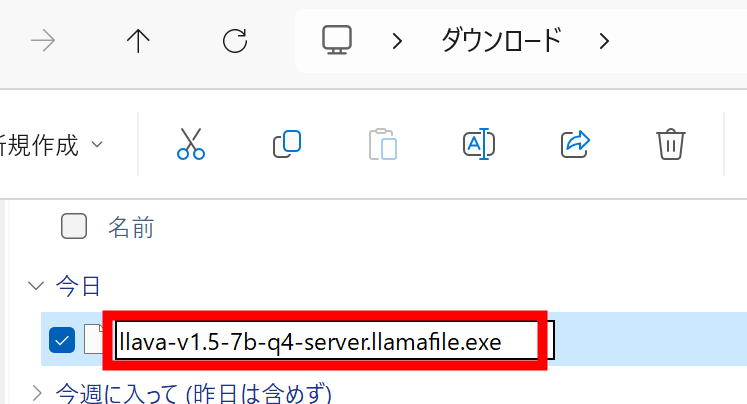
Download the llava-v1.5 executable file and edit the name to add '.exe' at the end.
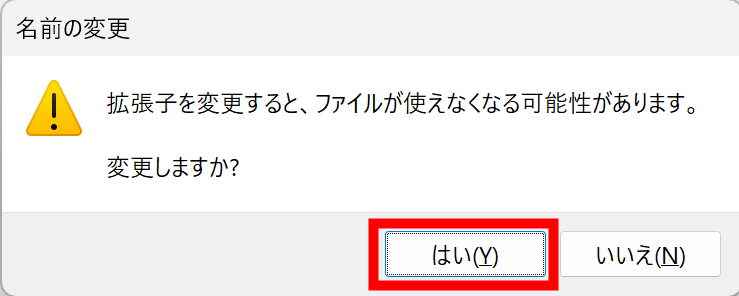
A warning will appear, so click 'Yes'.
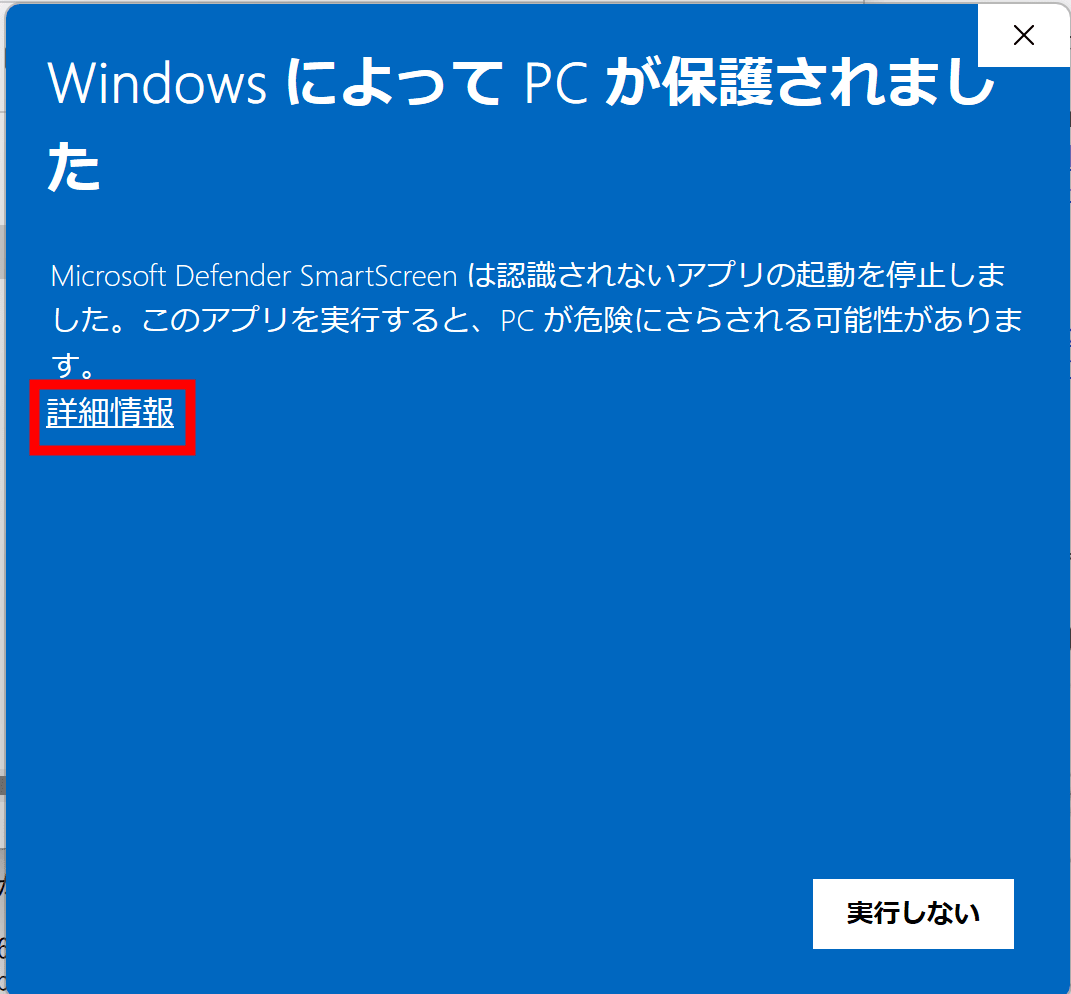
Double-click to run it and the Microsoft Defender SmartScreen screen will be displayed. Click 'More information'.
A 'Run' button will appear, so click it to run it.

The server started successfully, the browser opened automatically, and the llama.cpp UI appeared as shown below.
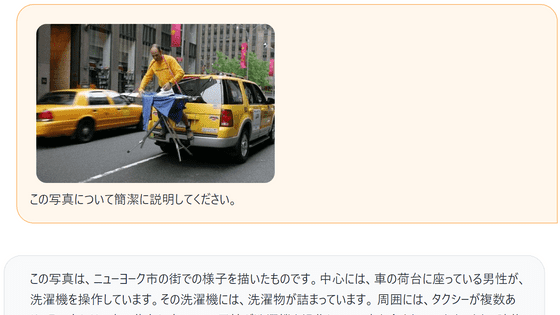
This time, I will try Llava, a model that can recognize images, so I will ask it to explain the image below.

Click 'Upload Image' at the bottom, select the image and click 'Open'.
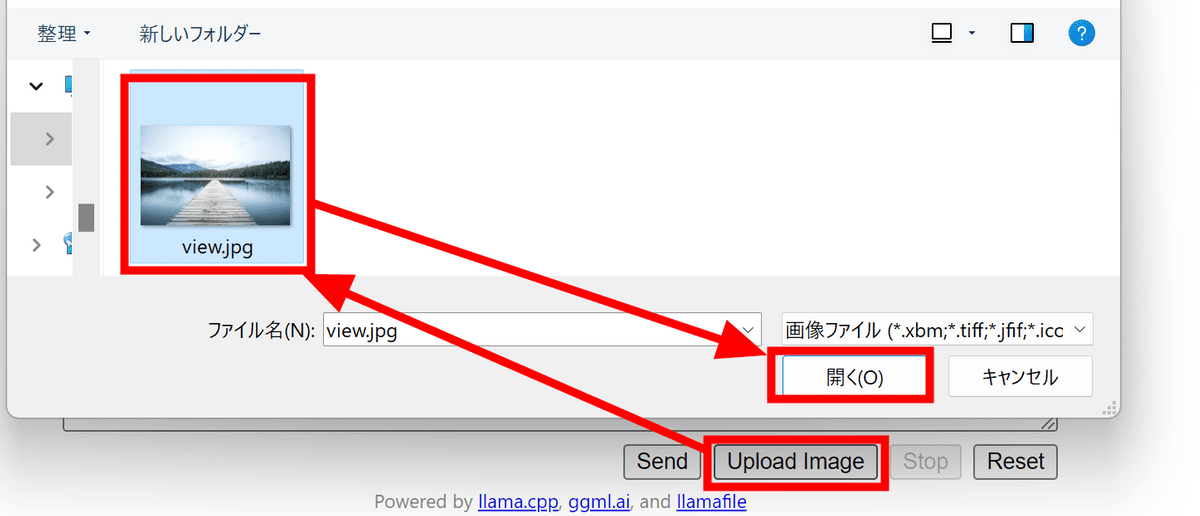
I'm not sure if it's uploaded correctly because the UI doesn't change, but enter the text and click 'Send'.
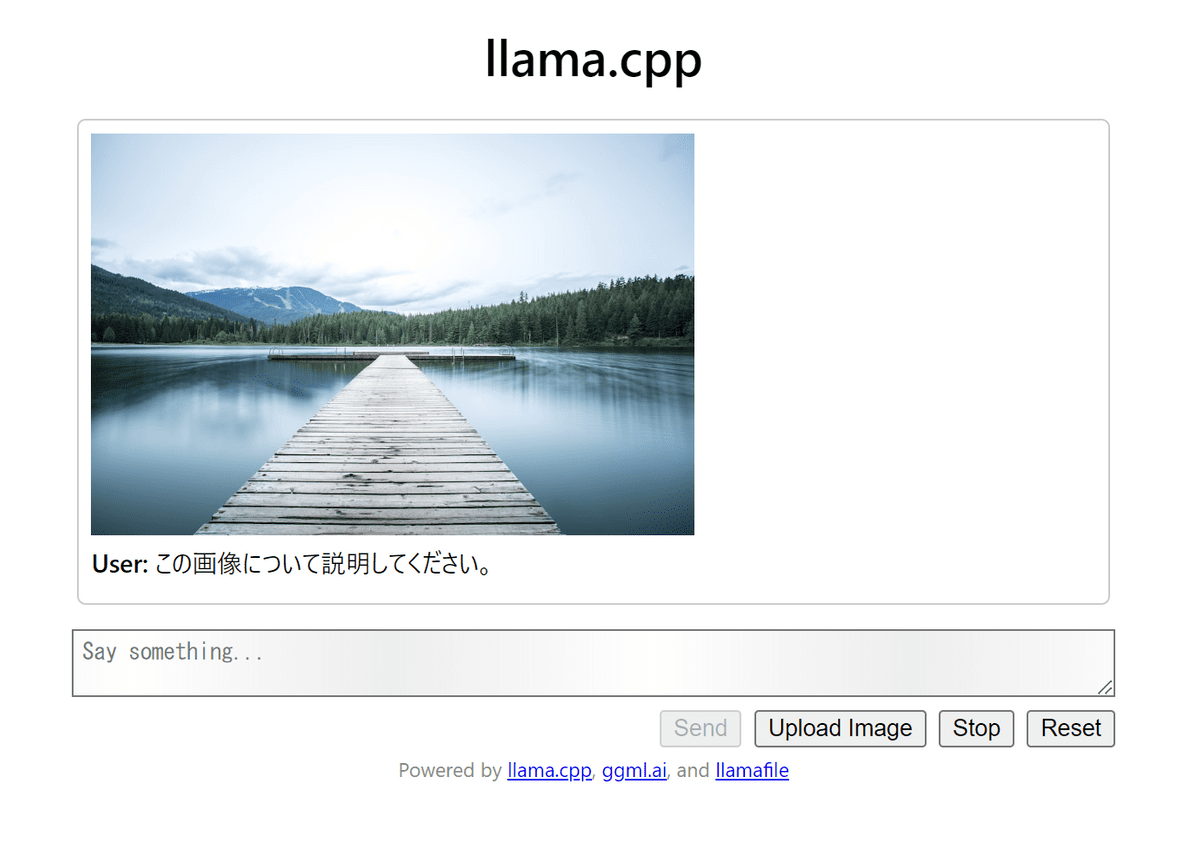
Then, the screen changes as shown below, and the image and prompt are entered.
The CPU usage rate and memory usage during inference is like this. CPU usage is high, but memory consumption is displayed as almost zero.
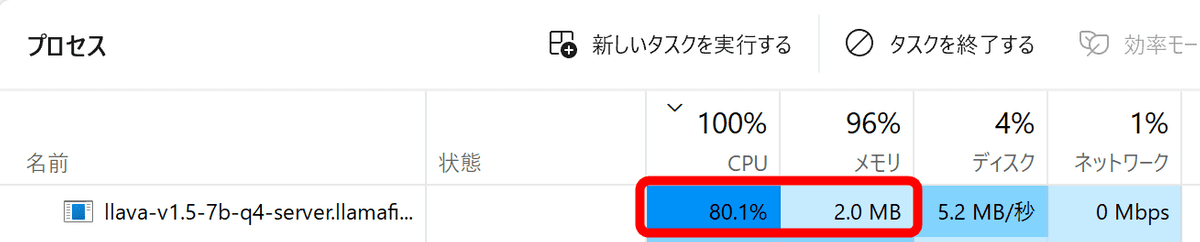
I thought it might be displayed as another process, but when I sorted it by memory usage, there was no process that seemed like it.

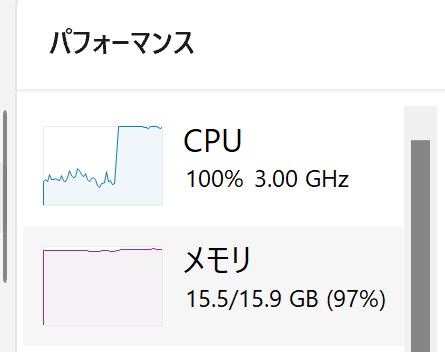
Of course, it does not mean that memory is not used, and if you look at the entire PC, memory is used almost to the maximum limit.
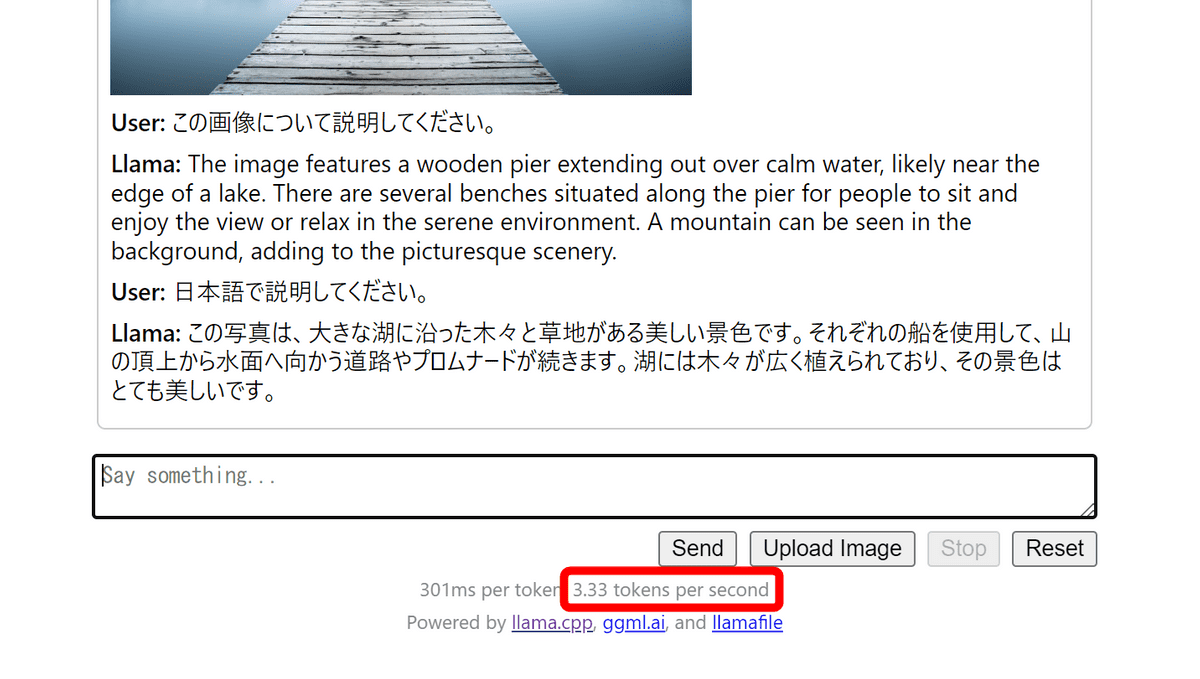
Inference is completed in about a few minutes. You can also output in Japanese by specifying 'in Japanese'. Answers were generated at a rate of 3.33 tokens per second on a laptop with an Intel Core i7-8650U processor.
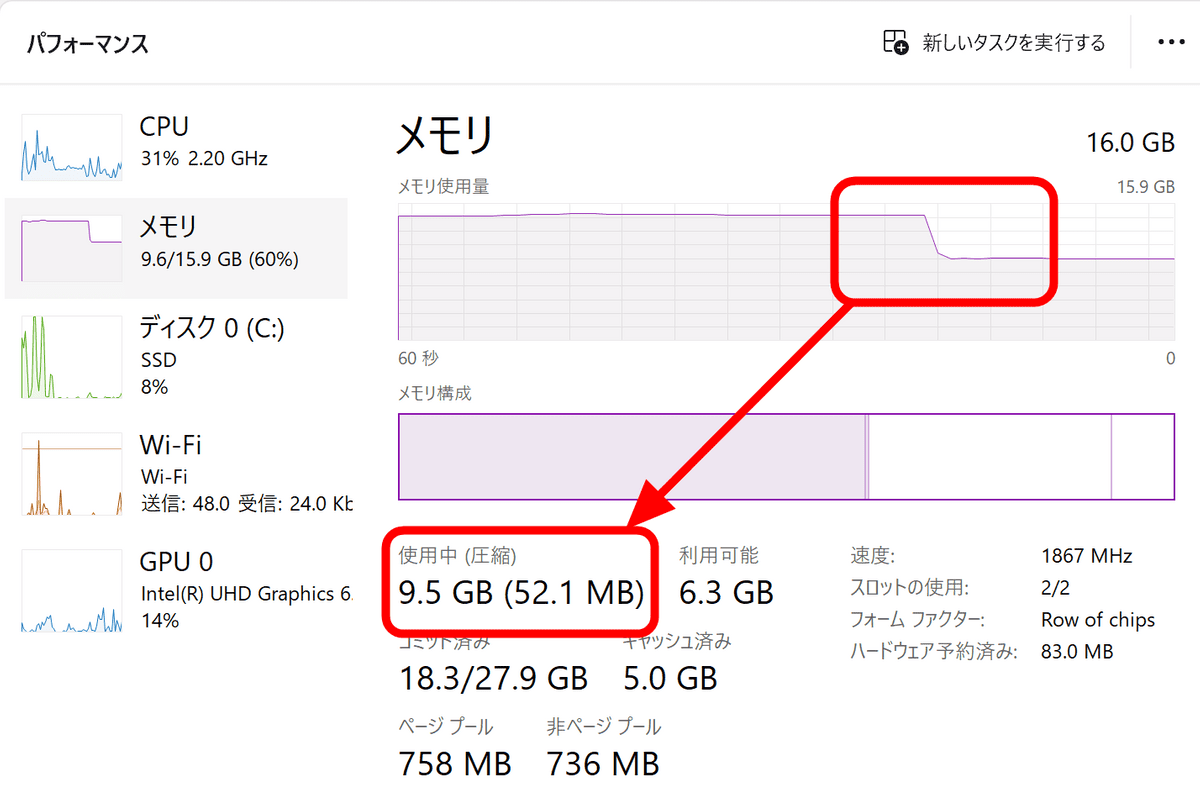
When I terminated llamafile, the memory usage decreased from 15.5GB to 9.5GB, so when I calculated backwards, it seemed that about 6GB was being used at most.
◆I tried running it on Debian
Since we will try the operation on an instance on Google Cloud Platform, access
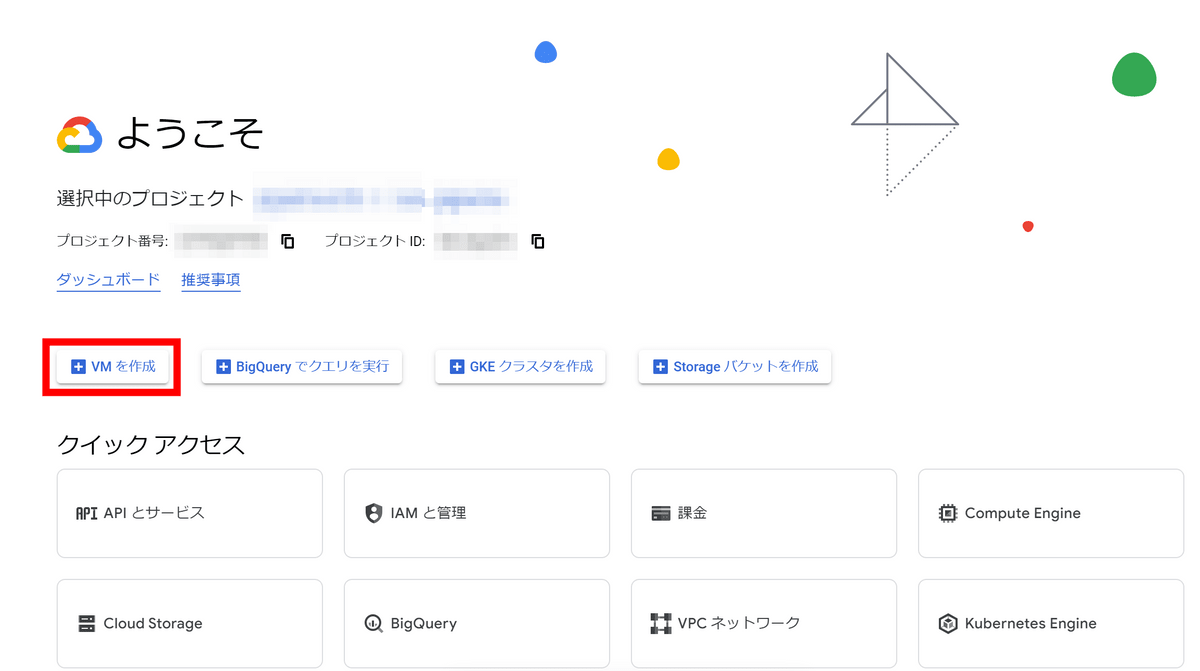
Enter 'test-llava' in the name field and select GPU in machine configuration. This time I decided to use NVIDIA T4, which has 16GB of VRAM.
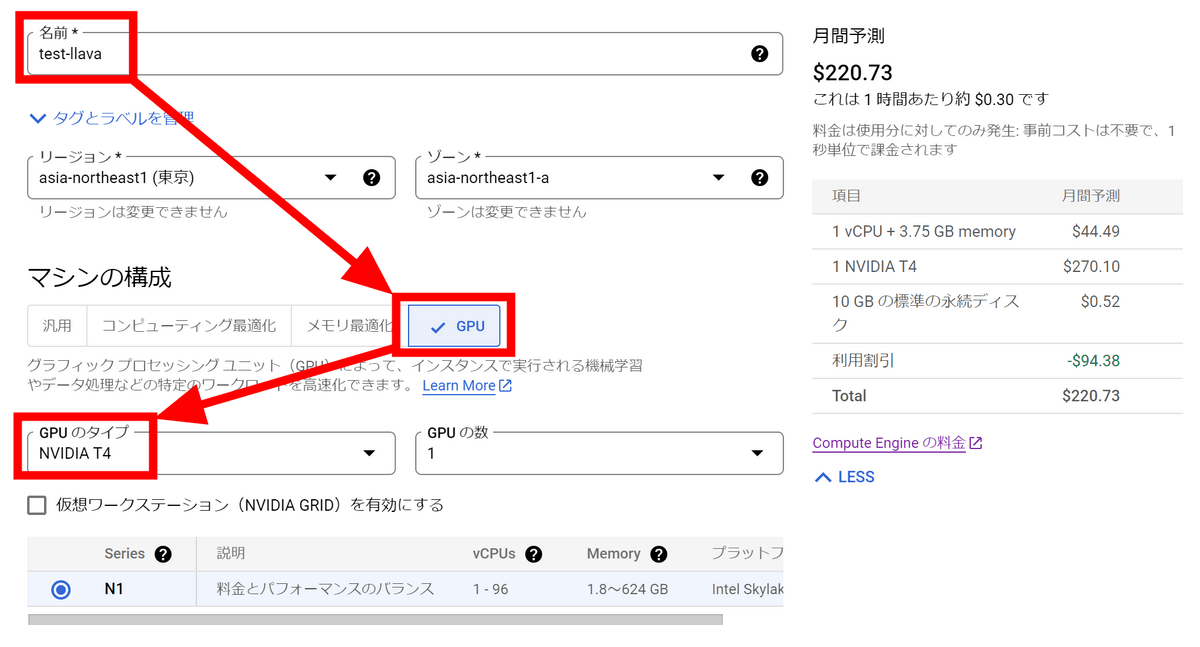
Select 'n1-standard-4' as the machine type. This time, since it was for testing, I set the VM provisioning model to 'Spot'. Although instances may suddenly stop due to GCP circumstances, you can keep the charges low.
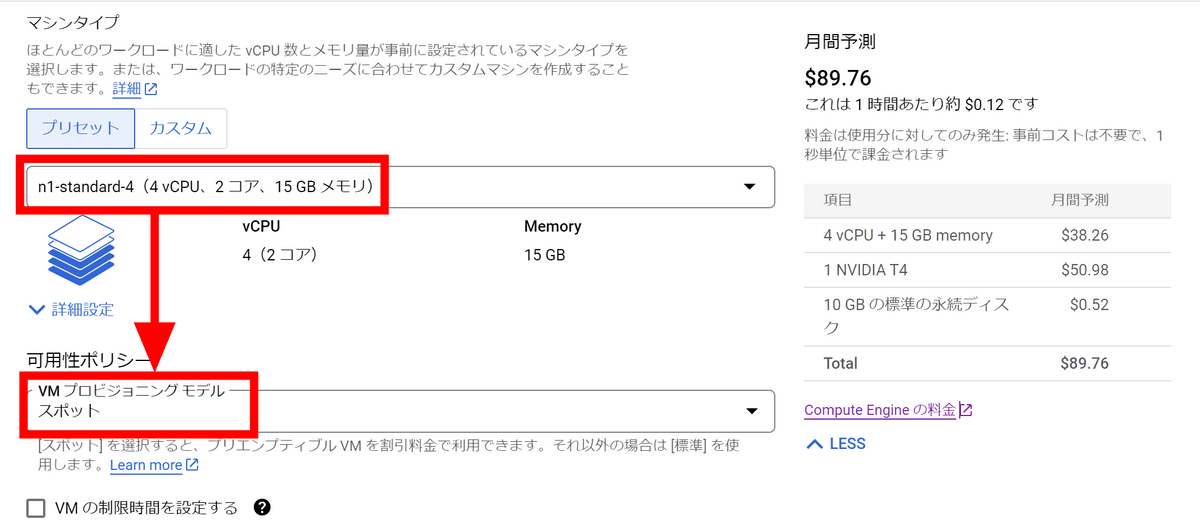
We want to boot the NVIDIA CUDA stack using the installed image instead of manually installing it, so click Switch Image.
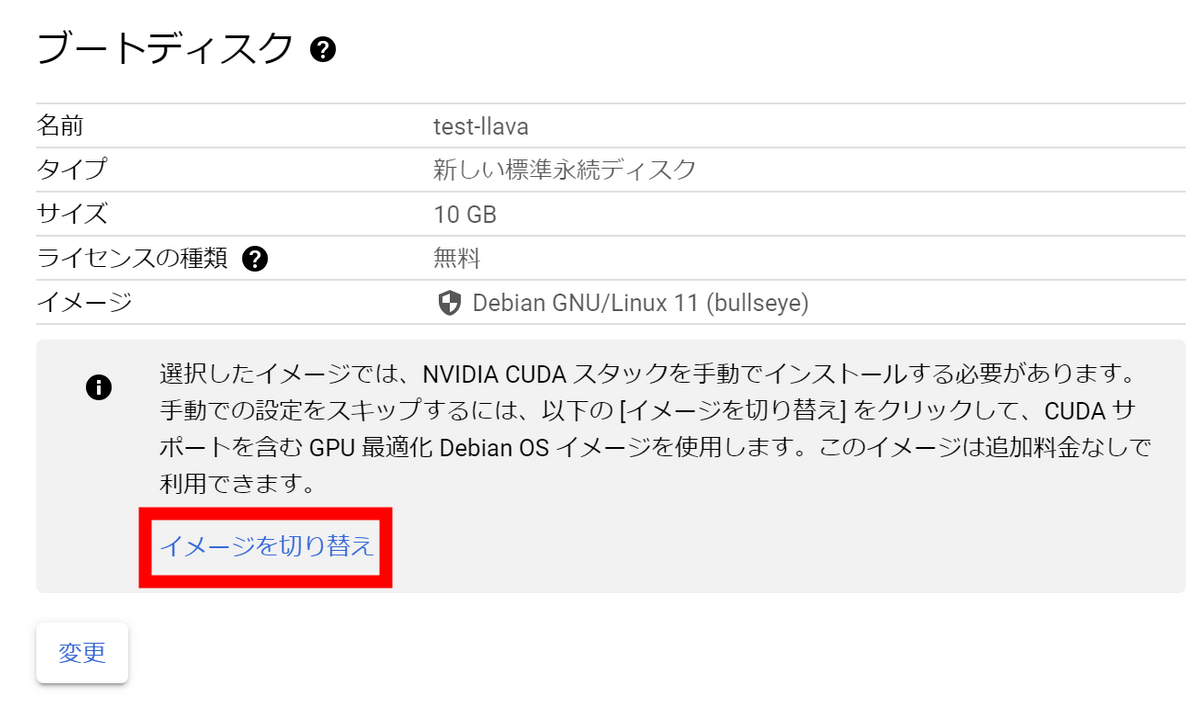
Since the image with CUDA preinstalled is selected, decide the disk size and click 'Select'.
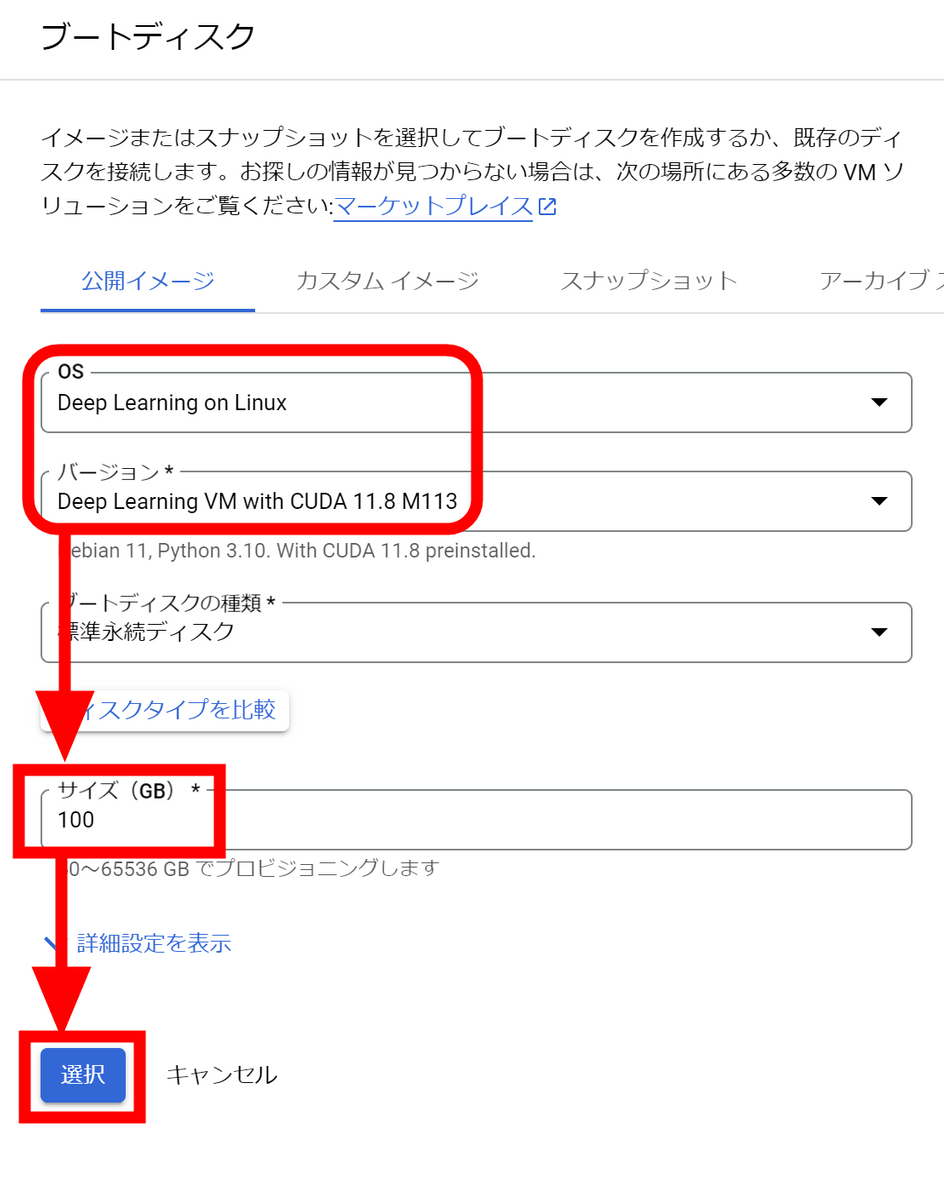
Click the 'Create' button at the bottom of the screen to create an instance.

Once the instance has started, click the 'SSH' button.

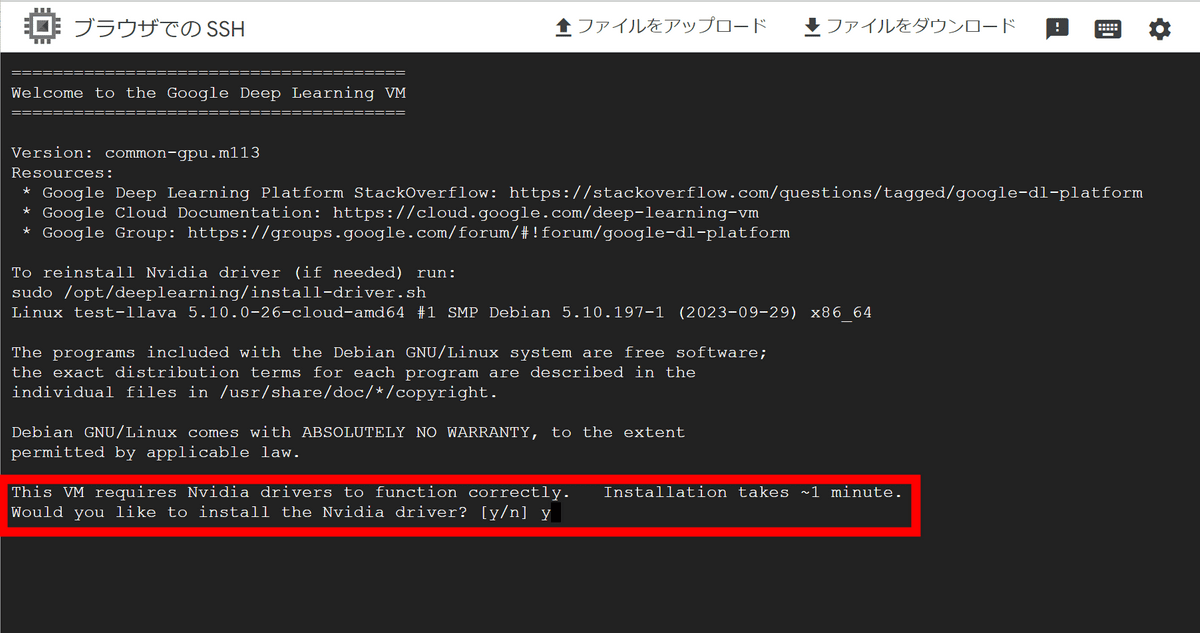
A separate window will open and you will be able to connect to the instance via SSH. First, you will be asked if you want to install the Nvidia driver, so type 'y' and press the enter key.
Download the llamafile of Llava 1.5 using the command below.
[code]wget https://huggingface.co/jartine/llava-v1.5-7B-GGUF/resolve/main/llamafile-server-0.1-llava-v1.5-7b-q4[/code]
and grant execution privileges.
[code]chmod 755 llamafile-server-0.1-llava-v1.5-7b-q4[/code]
Then run the command below.
[code]./llamafile-server-0.1-llava-v1.5-7b-q4[/code]
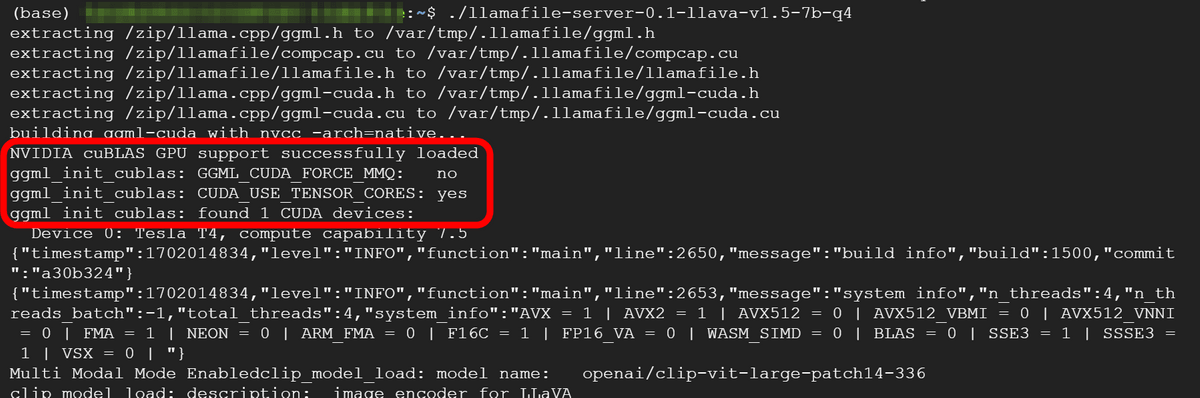
When you start it up, the model will be loaded into memory. Among the output logs, there were also logs that seemed to recognize the existence of the GPU.
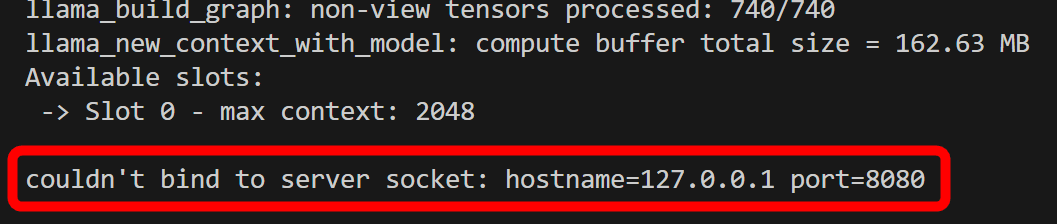
However, as soon as the loading was finished, the error 'couldn't bind to server socket: hostname=127.0.0.1 port=8080' appeared and the program ended. It looks like you are trying to use a port that is already in use.
It seems that llama.cpp is running internally, so refer to the llama.cpp documentation and run it again with the '--port' option.
[code]./llamafile-server-0.1-llava-v1.5-7b-q4 --port 8181[/code]
This time, the server started successfully. Make inferences with images and prompts similar to what you do on Windows.
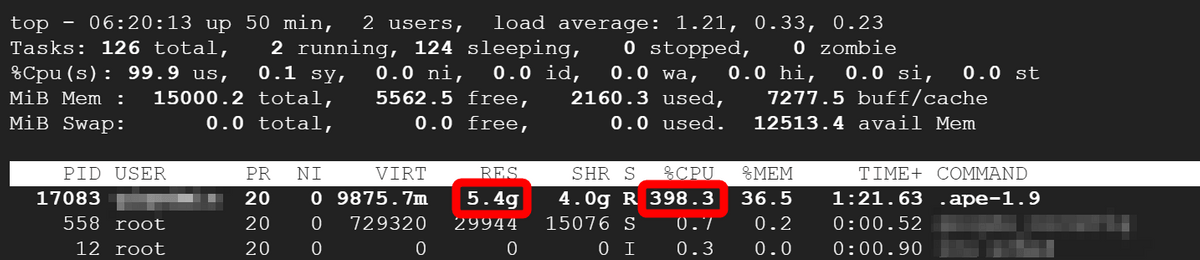
If you check the state of the CPU during inference, it is as shown in the figure below. Memory usage is 5.4GB and CPU usage has risen to about 400%.
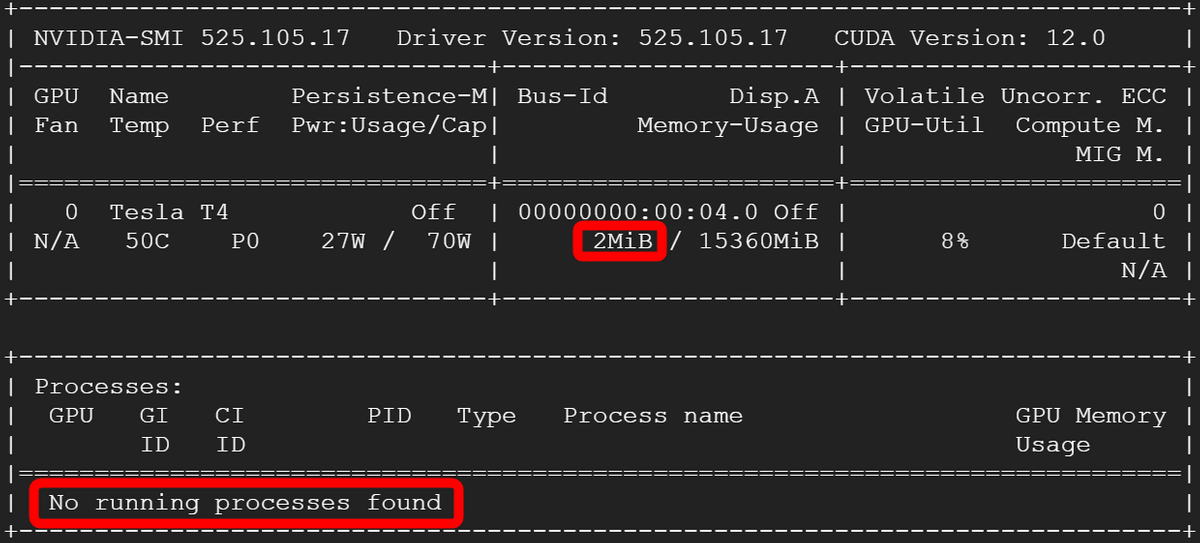
On the other hand, as shown in the figure below, the GPU consumed 2MB of memory and there were no running processes, so inference was performed only using the CPU.
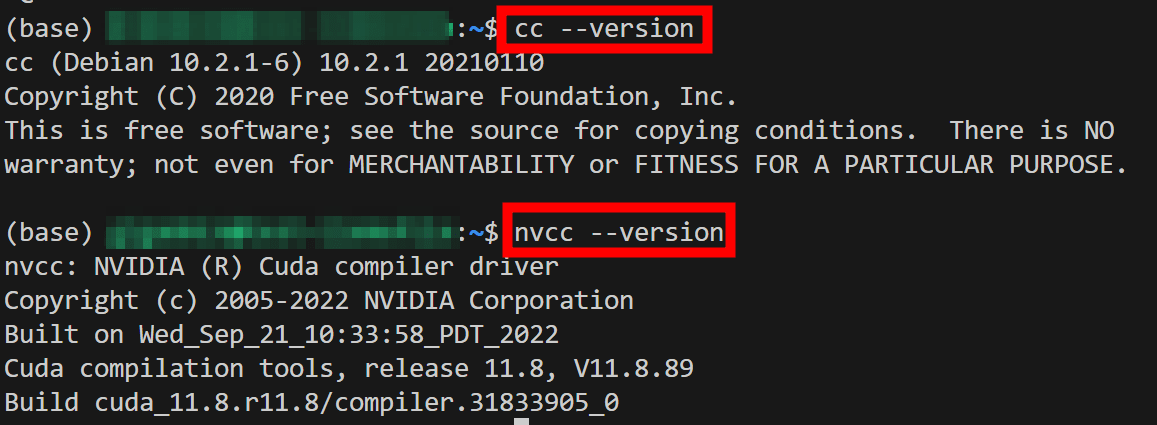
When I reconfirmed the conditions for GPU usage, I found that 'cc' and 'nvcc' are required, and I also need to add the flag '--n-gpu-layers 35'. CC and nvcc are ready for use as shown in the figure below.
Run the inference again with the '--n-gpu-layers 35' flag.
[code]./llamafile-server-0.1-llava-v1.5-7b-q4 --port 8181 --n-gpu-layers 35[/code]
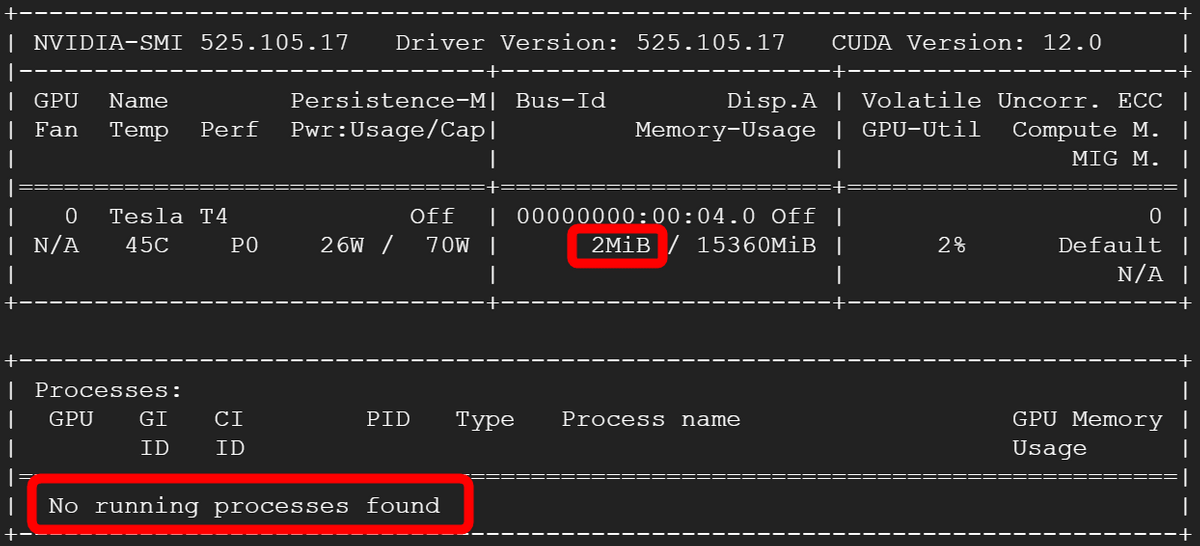
However, the GPU remained unused. It states, ``If GPU support cannot be compiled for some reason, inference will be made on the CPU,'' and this pattern seems to have taken into account that ``some reason.''
The llamafile repository explains how to create an executable file that can be run on multiple platforms at the same time, and how to create an executable file in the llamafile format, so if you are interested, please check it out.
Related Posts: