I tried running the open source GPT-4 level AI 'LLaVA-1.5' that can answer questions by looking at images on GCP

' LLaVA ', developed by a research team including Microsoft and the University of Wisconsin-Madison and released on April 17, 2023, is an AI with 'vision' that can respond to images based on the input. Masu. LLaVA-1.5, which appeared on October 5, 2023, is said to have further improved quality, so I actually tried running it on Google's cloud computing service ``Google Cloud Platform (GCP)''.
LLaVA/pyproject.toml at main · haotian-liu/LLaVA
You can check the performance of the previous version released in April 2023 and how to use the demo site in the article below.
I tried using a free high-performance chat AI ``LLaVA'' that can recognize images and guess ages and correctly answer people's name quizzes - GIGAZINE
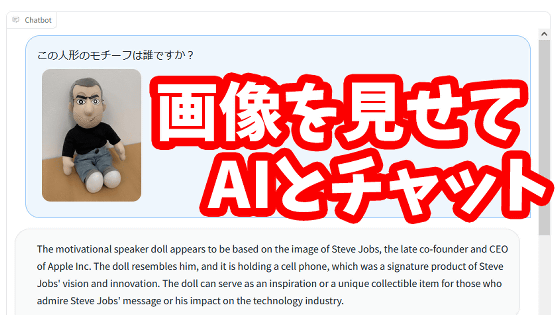
Before trying to run it on GCP, let's check the performance with a demo. Select 'llava-v1.5-13b' in the version selection field on the top left, send a sample image, and send the message 'Please briefly explain this photo', and LLaVA will explain the image in detail. I'll give it to you. In the previous version, responses were only in English, but it seems that LLaVA-1.5 will respond in Japanese.
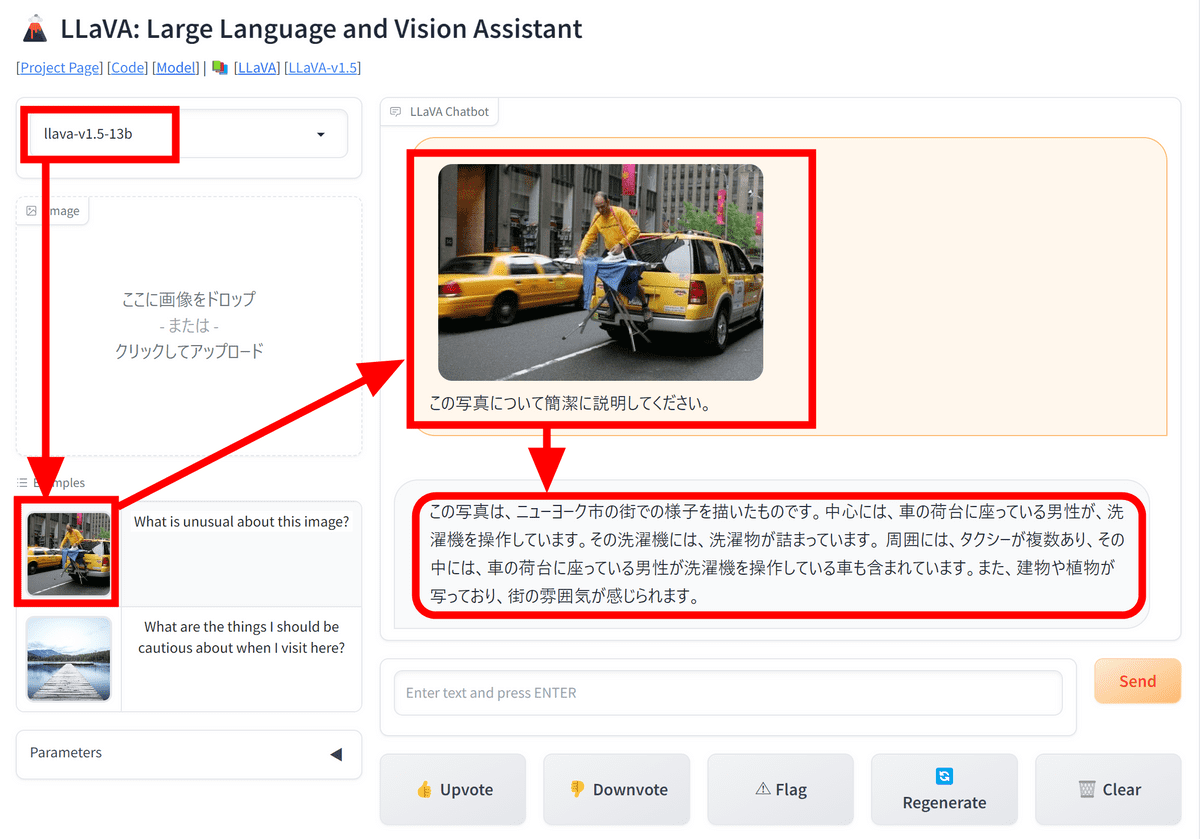
When I asked for ``within about 10 characters,'' it became much shorter, but even when I tried specifying the writing style and format, the response did not change. It seems that they cannot respond even if you place an order in too much detail.

Now that we have an idea of how it works, let's start building the environment. This time we will build on GCP, so access
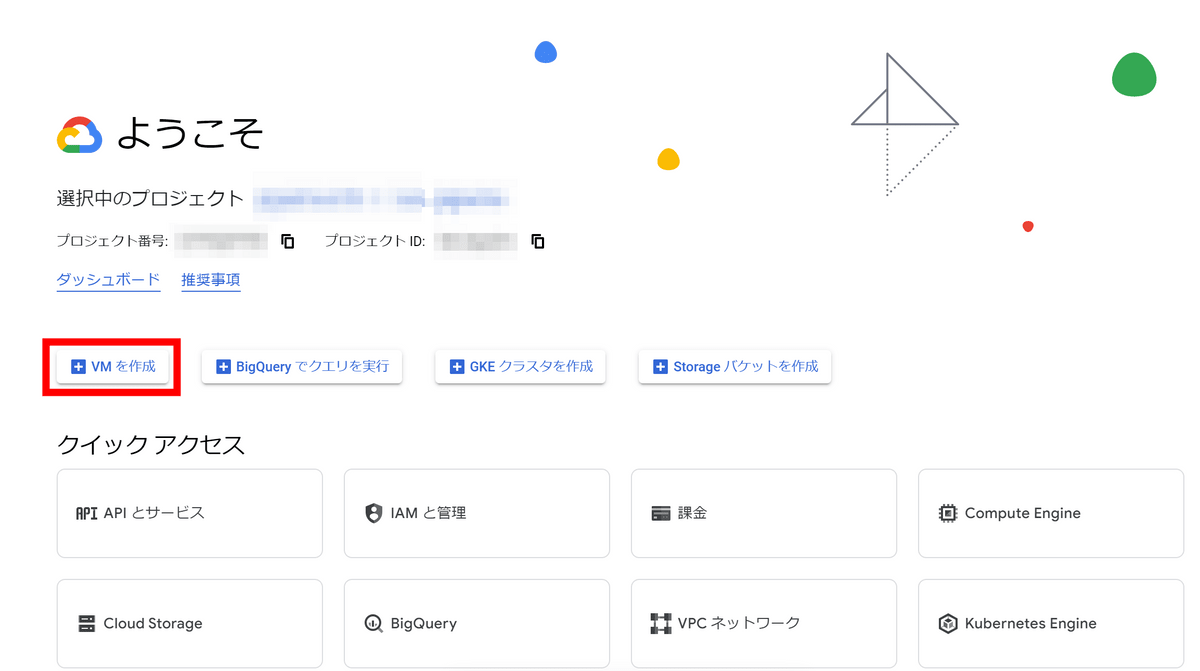
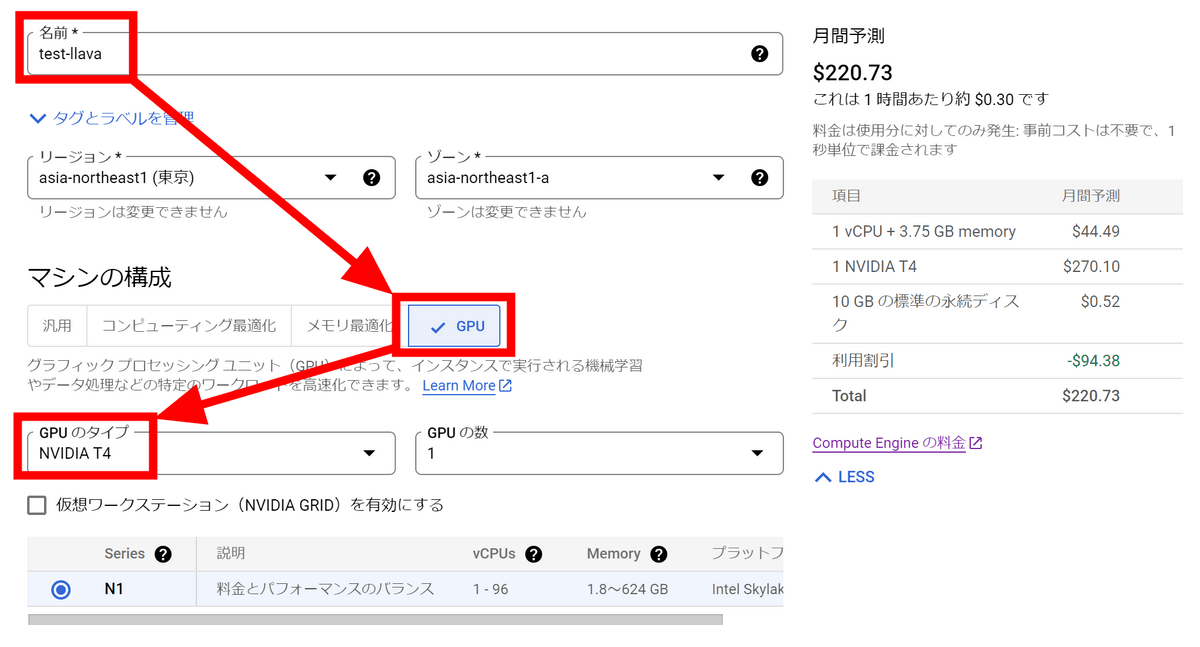
Enter 'test-llava' in the name field and select GPU in machine configuration. This time I decided to use NVIDIA T4, which has 16GB of VRAM.
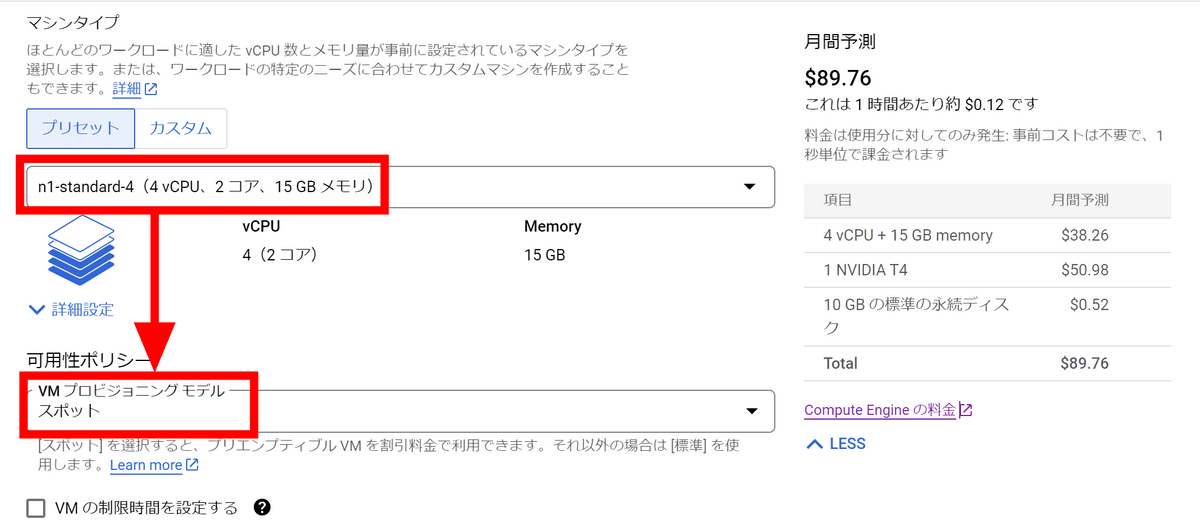
Select 'n1-standard-4' as the machine type. This time, since it was for testing, I set the VM provisioning model to 'Spot'. Although instances may suddenly stop due to GCP circumstances, you can keep the charges low.
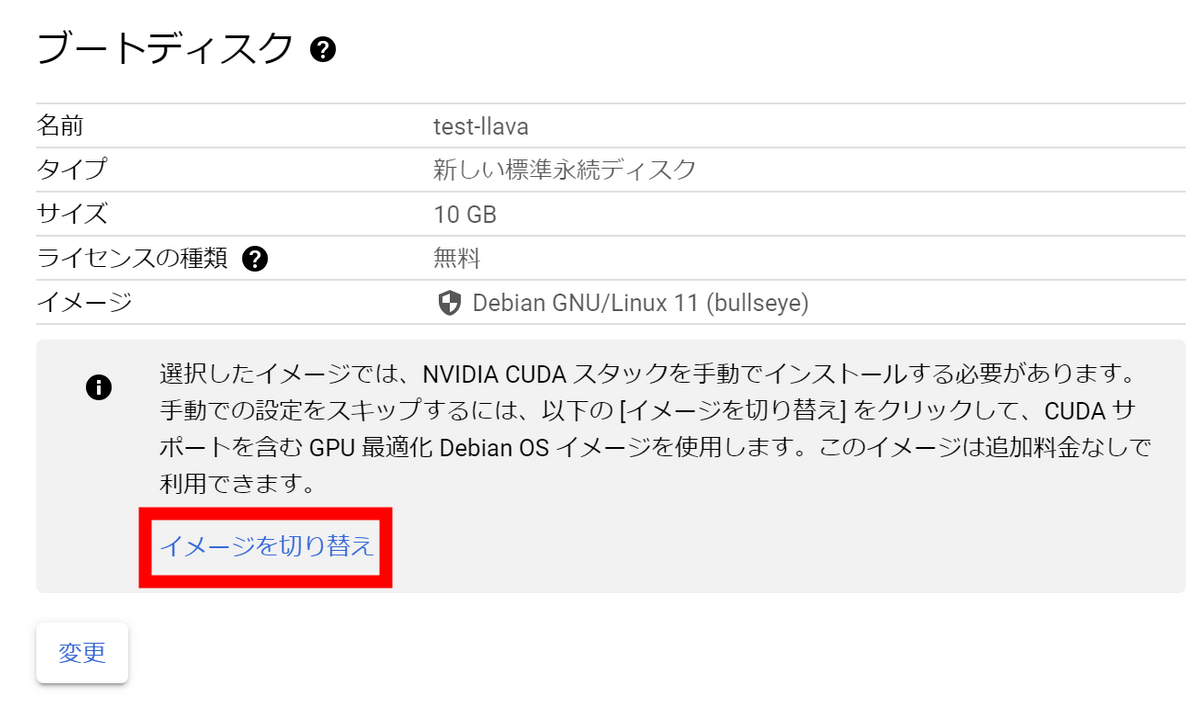
We want to boot the NVIDIA CUDA stack using the installed image instead of manually installing it, so click Switch Image.
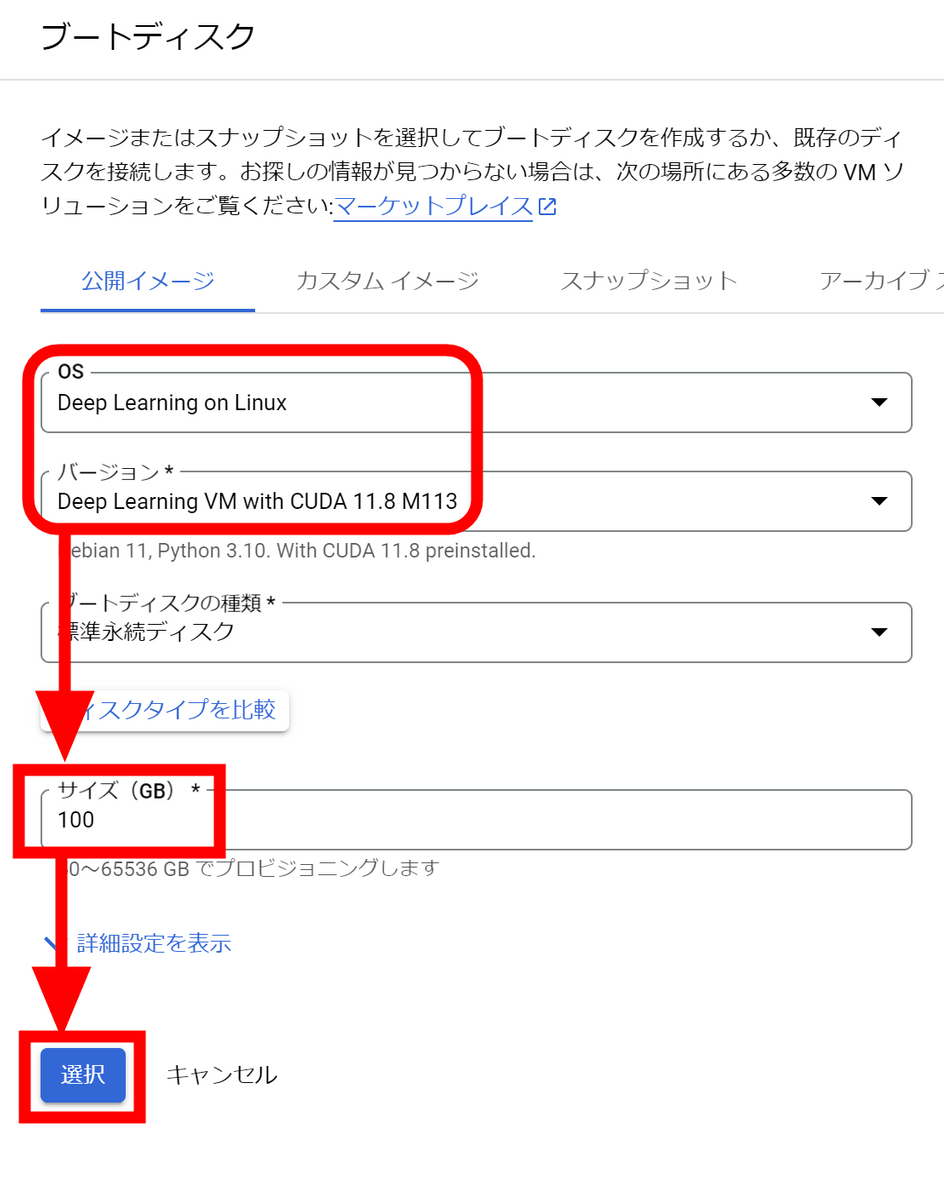
Since the image with CUDA preinstalled is selected, decide the disk size and click 'Select'.
Click the 'Create' button at the bottom of the screen to create an instance.

Once the instance has started, click the 'SSH' button.

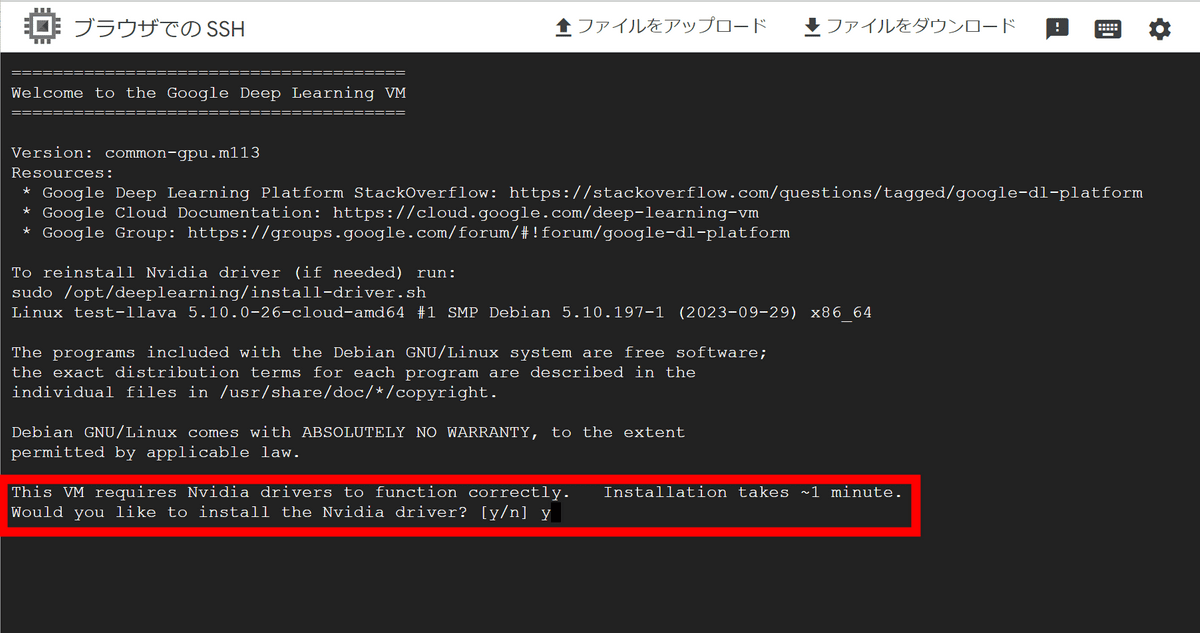
A separate window will open and you will be able to connect to the instance via SSH. First, you will be asked if you want to install the Nvidia driver, so type 'y' and press the enter key.
Next, install LLaVA. First, clone the repository from GitHub by running the command below.
[code]git clone https://github.com/haotian-liu/LLaVA.git
cd LLaVA[/code]
Next, install the required libraries using the command below.
[code]conda create -n llava python=3.10 -y
conda activate llava
pip install --upgrade pip # enable PEP 660 support
pip install -e .[/code]
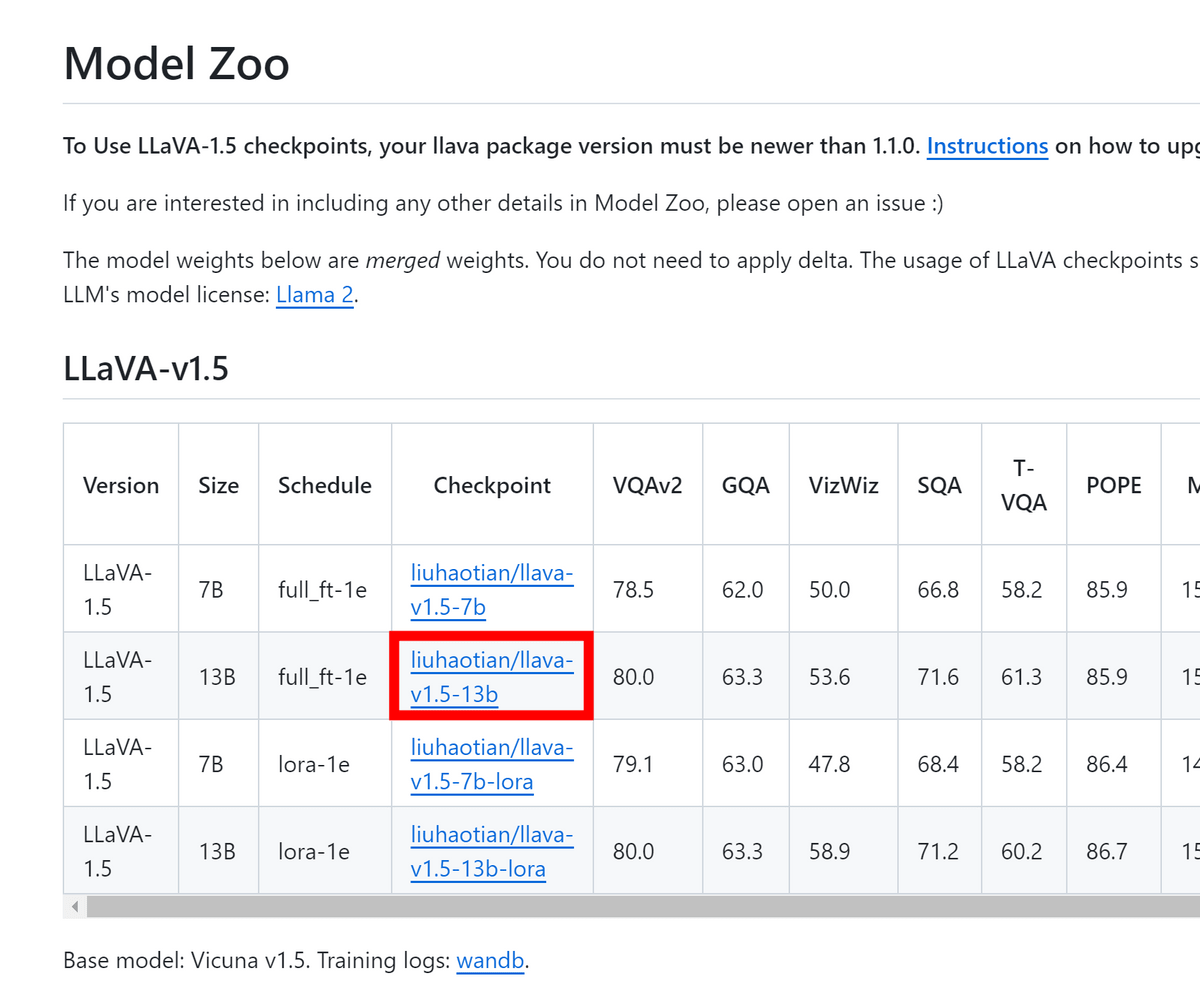
Check the Checkpoint path on
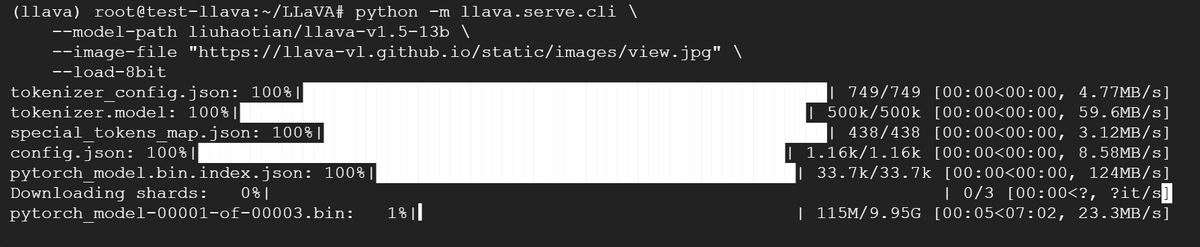
The command to run LLaVA is as follows. Specify the model in the format '--model-path ~' and the image you want to load in the format '--image-file ~'. You can specify the image by specifying a path on the Internet. Also, loading a full-sized model requires at least 24GB of VRAM, so add '--load-8bit' to reduce memory requirements.
[code]python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-13b \
--image-file 'https://llava-vl.github.io/static/images/view.jpg' \
--load-8bit[/code]
When I ran the code, the model download started automatically.
After about an hour, the model is ready and 'USER:' is displayed. Immediately enter the prompt, ``Please briefly describe the image in about 10 characters.''

However, an error 'CUDA out of memory' occurred and the operation stopped. Even with 8bit quantization, 15GB of VRAM seems not to be enough.

Next, add '--load-4bit' to perform 4-bit quantization and further reduce the amount of VRAM required.
[code]python -m llava.serve.cli \
--model-path liuhaotian/llava-v1.5-13b \
--image-file 'https://llava-vl.github.io/static/images/view.jpg' \
--load-4bit[/code]
After waiting for about 30 minutes, the model will be ready. Send the same prompt as before.

LLaVA's response was, 'A wooden pier over a lake with mountains in the background.' Perhaps because of 4-bit quantization, I was unable to get an answer in Japanese, but I was able to explain the image appropriately.

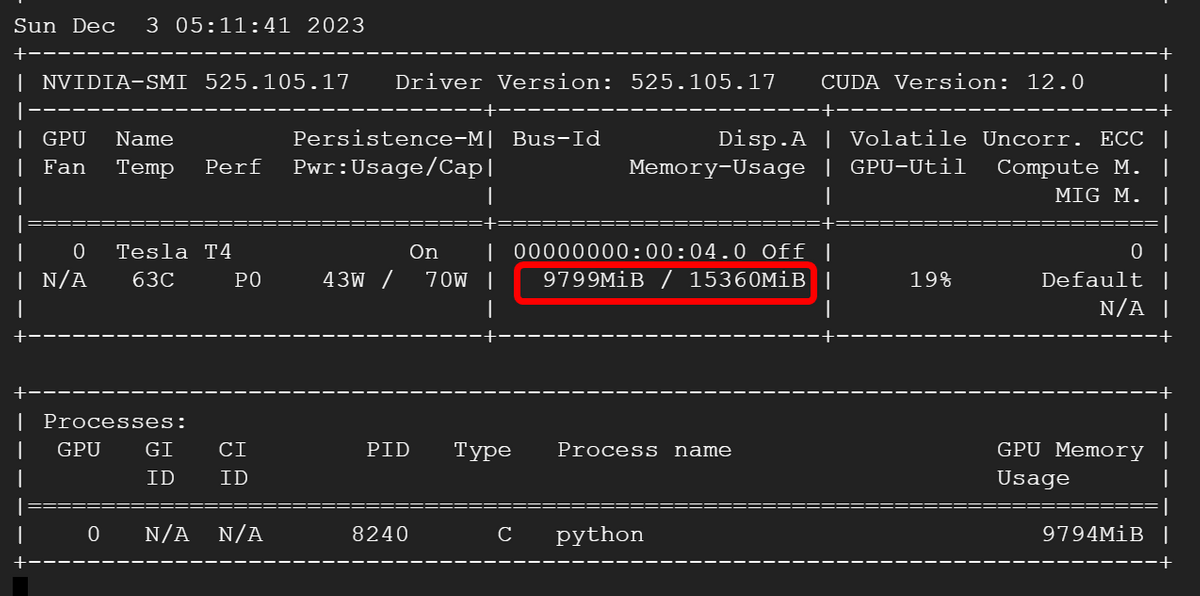
The VRAM consumption of the LLaVA-1.5-13B model when 4-bit quantization was performed was approximately 10 GB.
Related Posts: