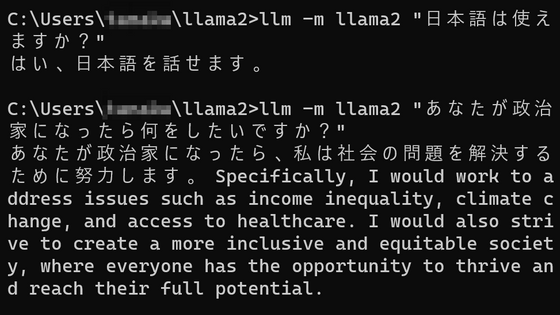
Official Docker image of 'Ollama', an application that allows you to easily run various chat AIs in the local environment, is now available

The official Docker image of 'Ollama', an application that allows you to easily run open source large-scale language models such as '
Ollama is now available as an official Docker image · Ollama Blog
https://ollama.ai/blog/ollama-is-now-available-as-an-official-docker-image
Representative examples of large-scale language models that can be run on Ollama are shown below. You can check the entire list on Ollama's official website .
| model | parameter | size | Download |
|---|---|---|---|
| Mistral | 7B | 4.1GB | ollama run mistral |
| Llama 2 | 7B | 3.8GB | ollama run llama2 |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b |
| Orca Mini | 3B | 1.9GB | ollama run orca-mini |
| Vicuna | 7B | 3.8GB | ollama run vicuna |
A model with 3B (3 billion) parameters requires at least 8GB of memory, a 7B (7 billion) model requires 16GB, and a 13B (13 billion) model requires 32GB of memory.
So, let's start setting up the environment to run Ollama. This time we will be using Docker, so install Docker using the method that suits your environment from the link below.
Install Docker Engine | Docker Documentation
https://docs.docker.com/engine/install/
This time, to use Debian, I entered the following command.
[code]sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo \
'deb [arch='$(dpkg --print-architecture)' signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/debian \
'$(. /etc/os-release && echo '$VERSION_CODENAME')' stable' | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin[/code]
Once Docker is installed, start Ollama. There is a mode that operates using only the CPU, and a mode that uses NVIDIA's GPU to speed up the operation, but this time we will start in CPU only mode, so execute the command below.
[code]docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama[/code]
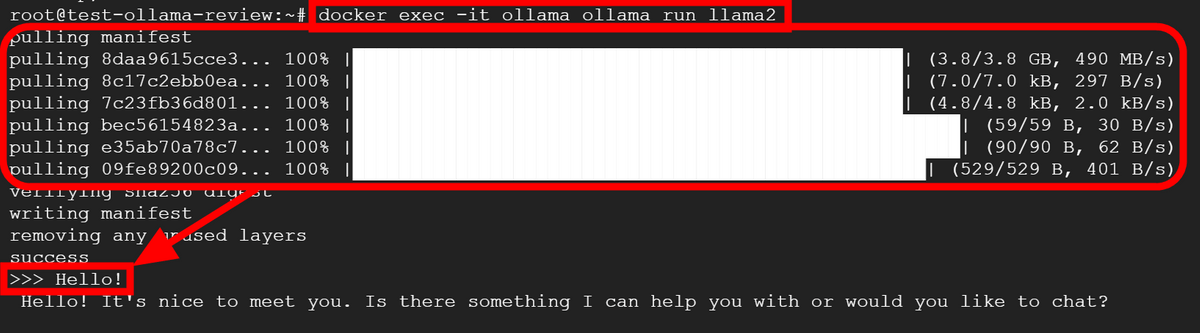
After starting the Ollama container, you can operate Ollama using the command below.
[code]docker exec -it ollama [command you want to execute][/code]
This time we will be using the 7B model of Llama 2, so refer to the 'Download' column in the table above and run the command 'docker exec -it ollama ollama run llama2', and the model will be automatically downloaded and executed. Ta. When it becomes possible to input, '>>>' will be displayed, so just enter the chat here. First of all, I greeted them with 'Hello!'.
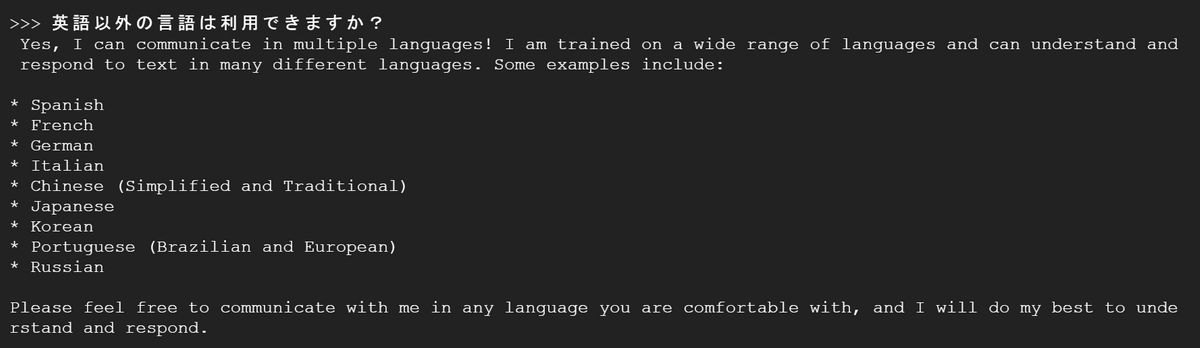
When I tried Japanese, he said, 'I can communicate in multiple languages!' Regardless of the performance of Llama 2, I found that I could use Japanese without any problems even when interacting with models on Ollama.
In addition, GIGAZINE has written an article about the models that can be used with Ollama as follows. Please check it out if you want to know more about the model.
◆Mistral
A large-scale language model 'Mistral 7B' that can be used and verified with a truly open source license has appeared, making it possible to develop AI with performance exceeding 'Llama 2 13B' and 'Llama 1 34B' - GIGAZINE


◆Llama 2 Uncensored
What are the benefits of creating an uncensored model that removes the 'censorship' of large-scale language models? -GIGAZINE


Related Posts: