Google Translate supports 24 new languages
Google
Google Translate adds 24 languages
https://blog.google/products/translate/24-new-languages/
Google AI Blog: Unlocking Zero-Resource Machine Translation to Support New Languages in Google Translate
https://ai.googleblog.com/2022/05/24-new-languages-google-translate.html
Google Translate adds support for 24 new languages --9to5Google
https://9to5google.com/2022/05/11/google-translate-new-languages/
According to Google, there are more than 300 million speakers worldwide using the newly supported 24 languages. Languages supported this time include Mizo, which is used by about 800,000 people in northeastern India, and Lingala, which is used by more than 45 million people throughout Central Africa. In addition, this update will support Native Americans in Quechuan, Guarani, Aymara, and the English dialect Sierra Leone for the first time.
The 24 languages supported this time and the areas where the speakers live are as follows.
・ Assamese spoken by about 25 million people in northeastern India
・ Aymara spoken by about 2 million people in Bolivia, Chile and Peru
・ Bambara spoken by about 14 million people in Mali
・ Bhojpuri spoken by about 50 million people in northern India, Nepal and Fiji
・ Dhivehi spoken by about 300,000 people in Maldives
・ Dogri language spoken by about 3 million people in northern India
・ Ewe language spoken by about 7 million people in Ghana and Togo
・ Guarani spoken by about 7 million people in Paraguay, Bolivia, Argentina and Brazil
・ Ilocano spoken by about 10 million people in the northern part of the Philippines
・ Konkani spoken by about 2 million people in Central India
・ Krio spoken by about 4 million people in Sierra Leone
・ Kurdish spoken by about 8 million people, mainly in Iraq
・ Lingala spoken by about 45 million people in the Democratic Republic of the Congo, the Republic of the Congo, the Central African Republic, Angola, and the Republic of South Sudan.
・ Kinyarwanda spoken by about 20 million people in Uganda and Rwanda
・ Meitei spoken by about 34 million people in northern India
・ Mizo spoken by about 830,000 people in northeastern India
・ Oromo language spoken by about 37 million people in Ethiopia and Kenya
・ Quechua spoken by about 10 million people in Peru, Bolivia, Ecuador and neighboring countries
・ Sanskrit spoken by about 20,000 people in India
・ Sepedi spoken by about 14 million people in South Africa
・ Tigrinya spoken by about 8 million people in Eritrea and Ethiopia
Tsonga spoken by about 7 million people in Eswatini, Mozambique, South Africa and Zimbabwe
・ Tzuyu spoken by about 11 million people in Ghana
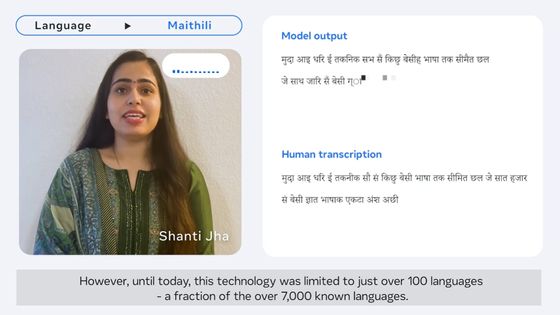
These 24 languages will be the first languages added to Google Translate using 'Zero Resource Translation', which translates phrases in two languages without explicit training or mapping. A simple explanation of zero-resource translation is 'a machine learning model that learns how to translate into another language without looking at an example.' However, Google explains, 'This technology is impressive but not perfect, so we will continue to improve the model.'

The reason Google Translate is now able to support 24 new languages is that machine translation technology has made great strides in recent years by integrating deep learning and natural language processing. The bottleneck in such machine translation technology is that 'digitized text data is limited' in minor languages. In addition, machine translation models usually require learning how to translate by using a large amount of translated parallel text. However, due to the 'data shortage' mentioned above, the machine translation model needs to learn how to translate from a limited amount of monolingual text.
Also, it seems that it is very difficult to automatically collect text data of minor languages that lack data. LangID, a library that identifies the language, works well in major languages, but often fails in minor languages. In addition, datasets collected on the Internet often contain more noise than available data, making it very difficult to build a model that can translate minor languages correctly. That's why.
Therefore, Google created a Lang ID model using semi-supervised learning. Google has successfully complemented this model with
Google's zero resource translation model makes full use of these. A single giant translation that collectively learns available data in more than 1000 languages by training translation tasks that include millions of parallel text data from major languages as well as monolingual text datasets. It is a model. Google's zero-resource translation model has a special token that indicates 'in which language to output' for the input that the model sees during training. Google uses the same tokens for both monolingual MASS and translation tasks, for example, for the token 'translate_to_french', 'translate English source into French' (translation task) and 'source'. You can perform both 'tasks that need to be translated into fluent French' (MASS tasks) in garbled French. Google states that 'this simple step alone has surprisingly improved translation accuracy.'
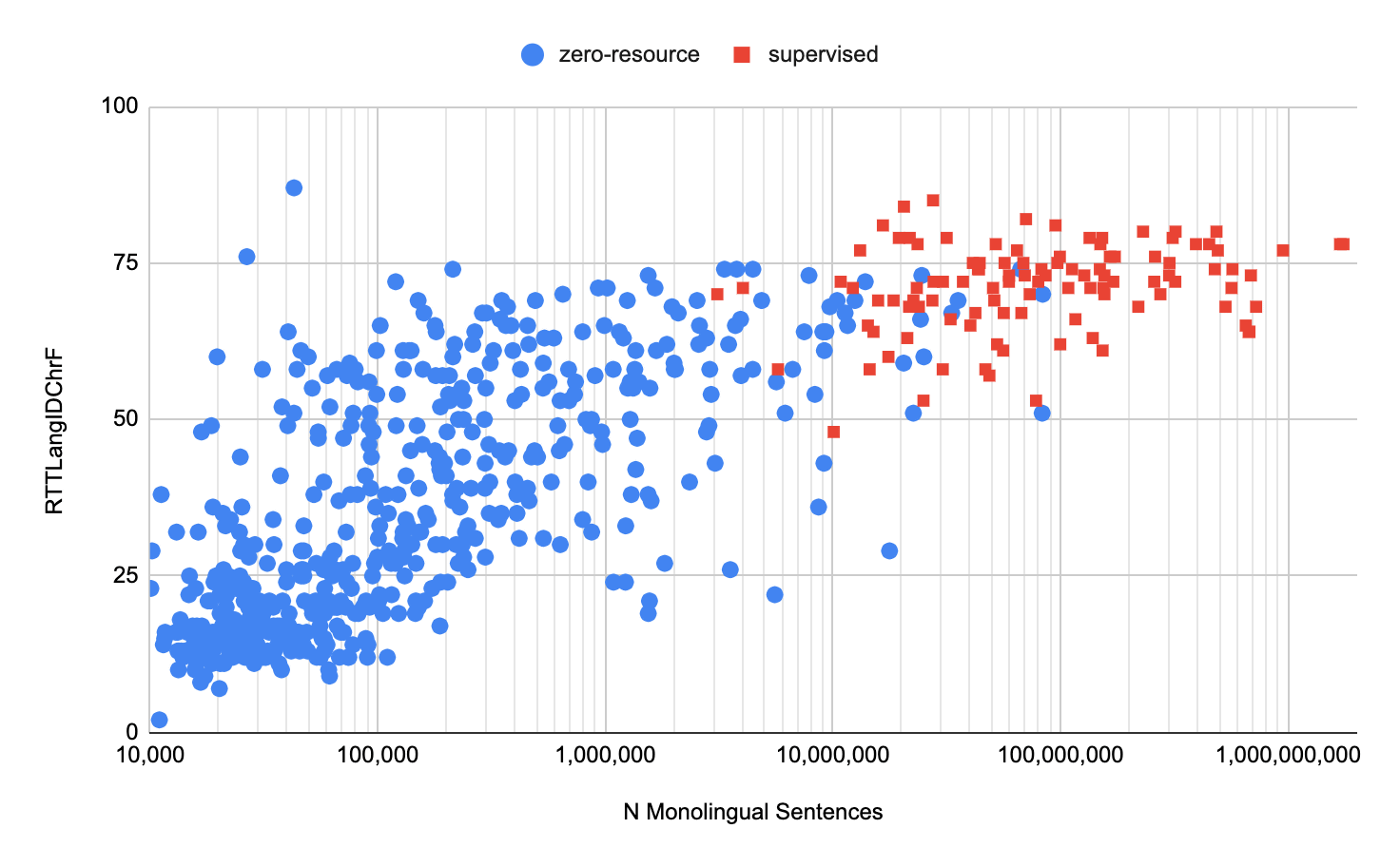
In the graph below, the horizontal axis shows the number of sentences (datasets) in a single language, and the vertical axis shows the translation accuracy score (the higher the value, the better the translation). ) And the scores when translating the major language (red dot) are summarized. With Google's zero-resource translation model, even in minor languages, the BLEU score, an algorithm for assessing the quality of machine-translated text from one natural language to another, has a medium quality (10-40), It turns out that another algorithm, ChrF , produced high quality (20-60) scores.
Related Posts:





in Web Service, Posted by logu_ii