Meta announces `` Massively Multilingual Speech (MMS) '', a speech recognition model that can transcribe from speech and read sentences in more than 1100 languages
Meta, which is focusing on AI development, has announced a speech recognition model ` ` Massively Multilingual Speech (MMS) '' that can transcribe from speech and read sentences in over 1100 languages. MMS supports languages that greatly exceed conventional large-scale multilingual speech recognition models, and is expected to make it easier to access various information even in languages with few speakers.
Today we're sharing new progress on our AI speech work. Our Massively Multilingual Speech (MMS) project has now scaled speech-to-text & text-to-speech to support over 1,100 languages — a 10x increase from previous work.
— MetaAI (@MetaAI) May 22, 2023
Details + access to new pretrained models ⬇️
Introducing speech-to-text, text-to-speech, and more for 1,100+ languages
https://ai.facebook.com/blog/multilingual-model-speech-recognition/

fairseq/examples/mms at main facebookresearch/fairseq GitHub
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Meta has been focusing on the development of speech recognition and translation AI, such as announcing the development of AI ' Babelfish' that translates languages around the world in real time. In a blog post announcing MMS, Meta said, ``By giving machines the ability to recognize and generate speech, more people can access information, including those who access information by voice alone. I will be able to do it,” he said.
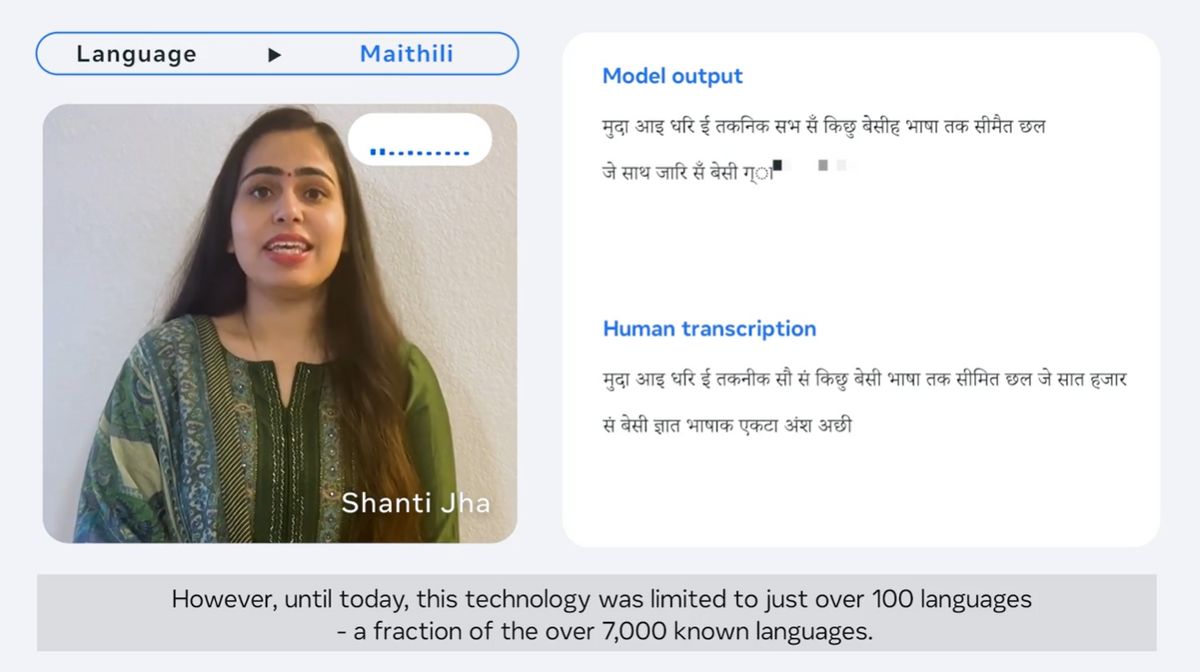
Generating quality machine learning models requires large amounts of labeled data, and in the case of speech recognition models, thousands of hours of speech and its transcription data. However, most of the more than 7,000 languages spoken on earth do not have such high-quality data, and existing speech recognition models only cover about 100 languages. is.
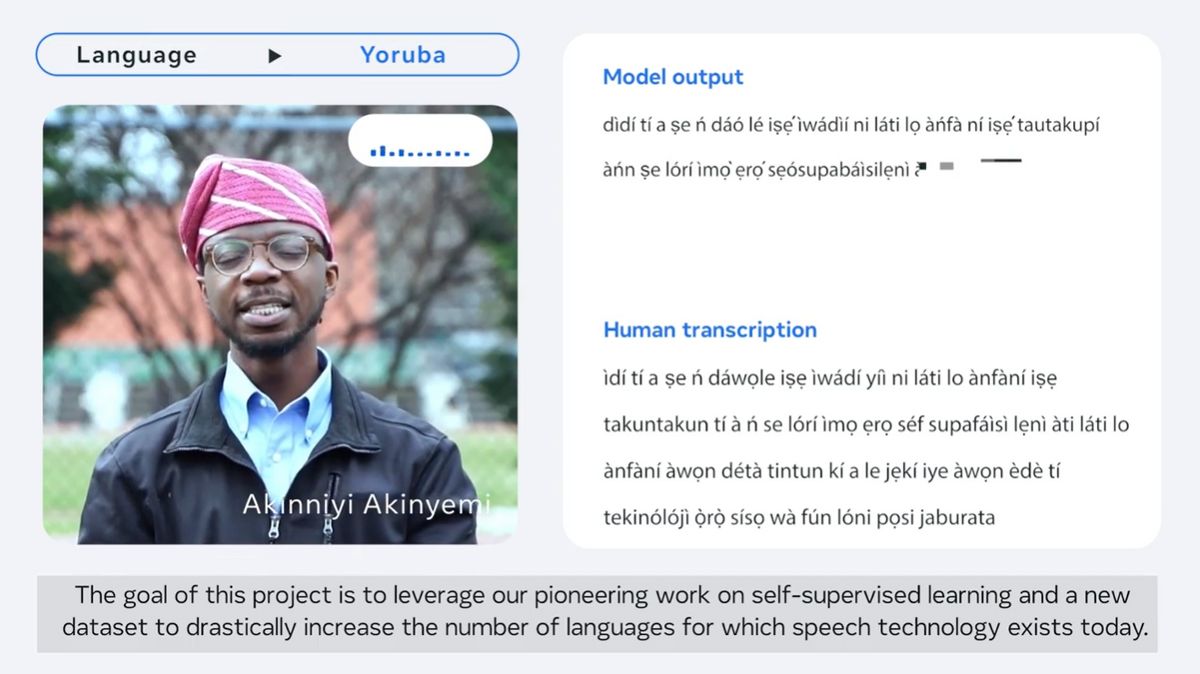
Therefore, Meta uses the speech recognition framework ` ` Wav2vec 2.0 '', which adopts self-supervised learning that can be learned from unlabeled data, to overcome the lack of labeled data in languages with few speakers in the MMS project. said he did. Also, as part of the project, Meta has created a ' New Bible Reading Dataset' in over 1100 languages to train MMS. Religious literature, including the New Bible, has been translated into various languages and is widely studied for text-based language translation research, so it is also useful in developing speech recognition models.
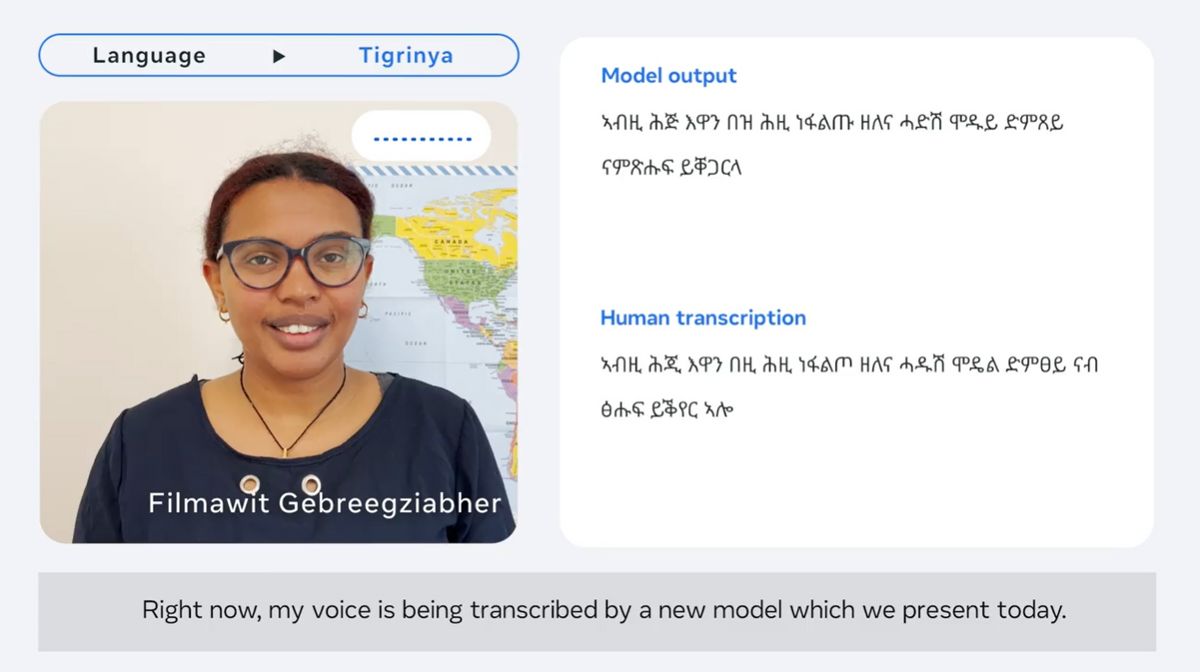
In a video published by Meta, you can see MMS transcribing various languages in real time. The Tigrinya language spoken in Eritrea and Ethiopia looks like this.

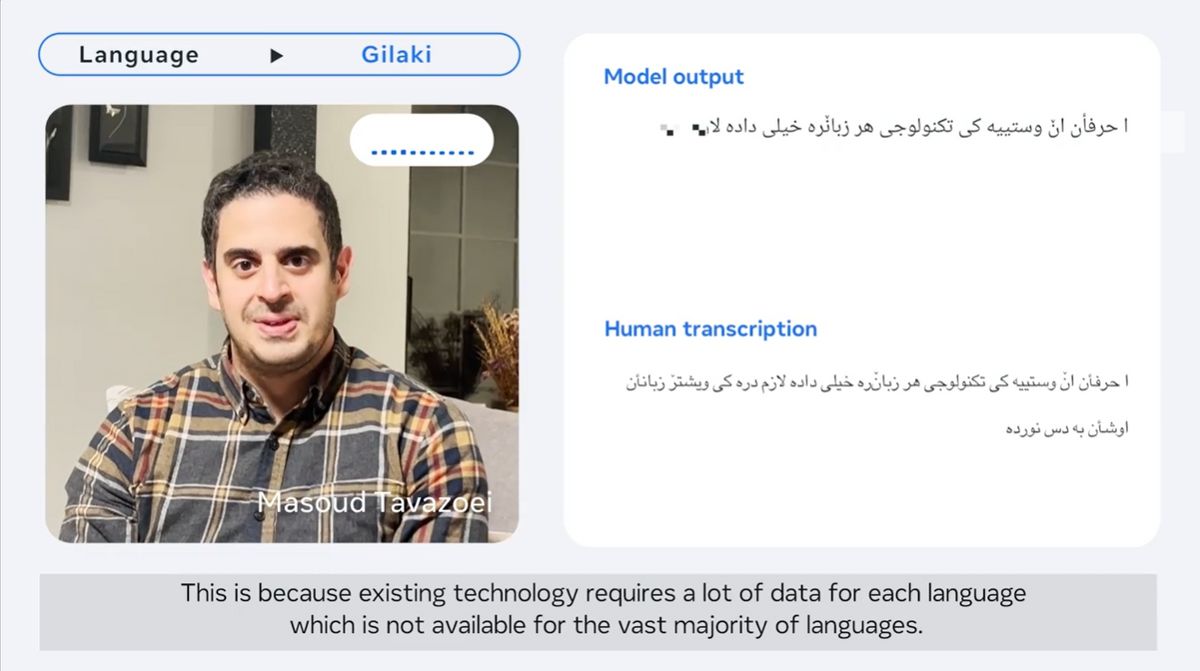
A Gilaki language spoken in northern and western Iran.
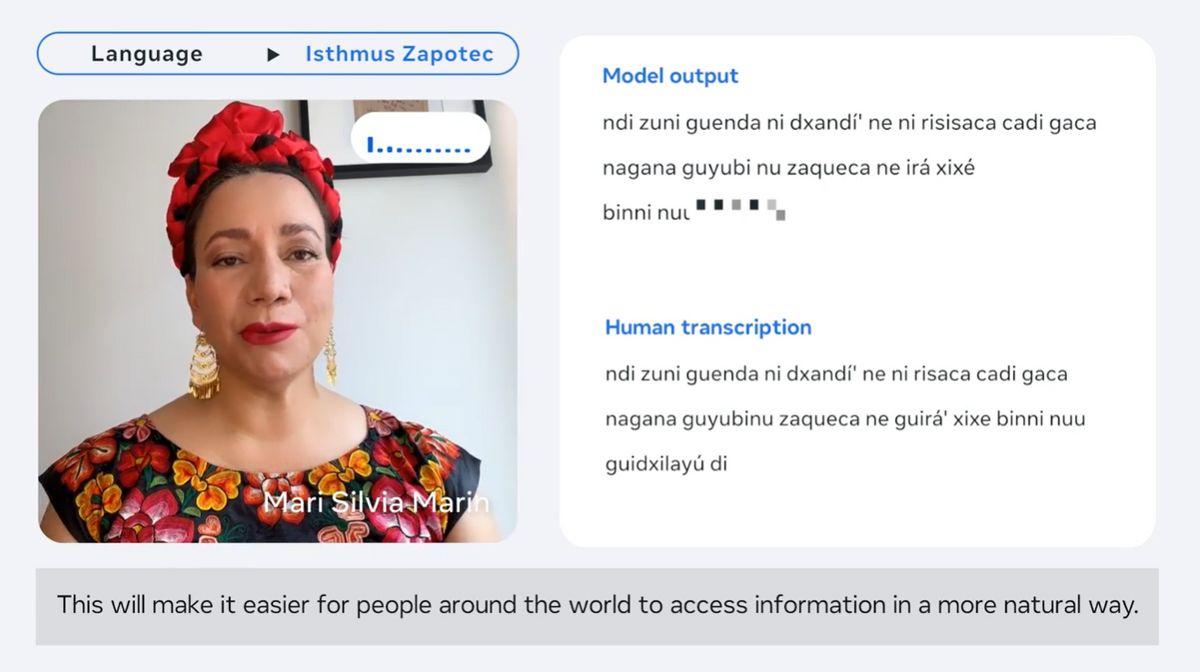
About 85,000 people of the Zapotec tribe, an indigenous people of Mexico, speak
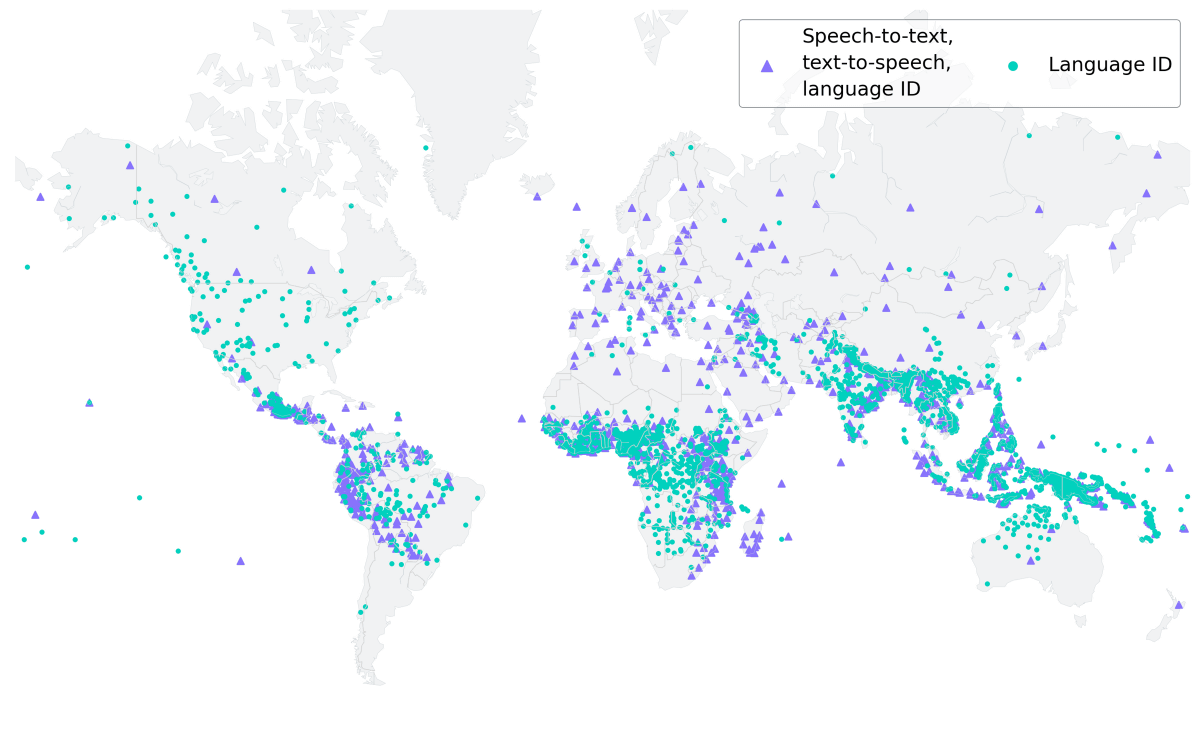
MMS supports transcription and reading in 1107 languages indicated by purple triangles on the world map below, and can identify more than 4000 languages indicated by green circles. matter.
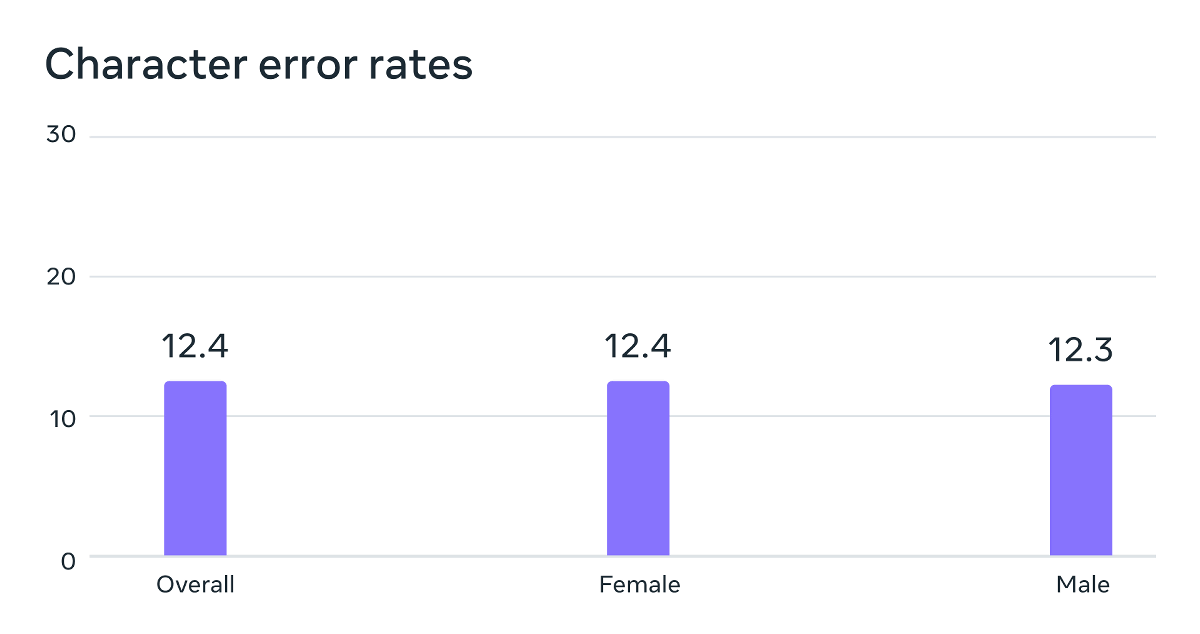
It seems that many of the speech data used for training were read by male speakers, but according to Meta's analysis, MMS has been shown to work almost equally well for male and female voices. increase. Looking at the graph below, which examines the error rate of speech recognition, the male (Male) error rate is 12.3 and the female (Female) error rate is 12.4.
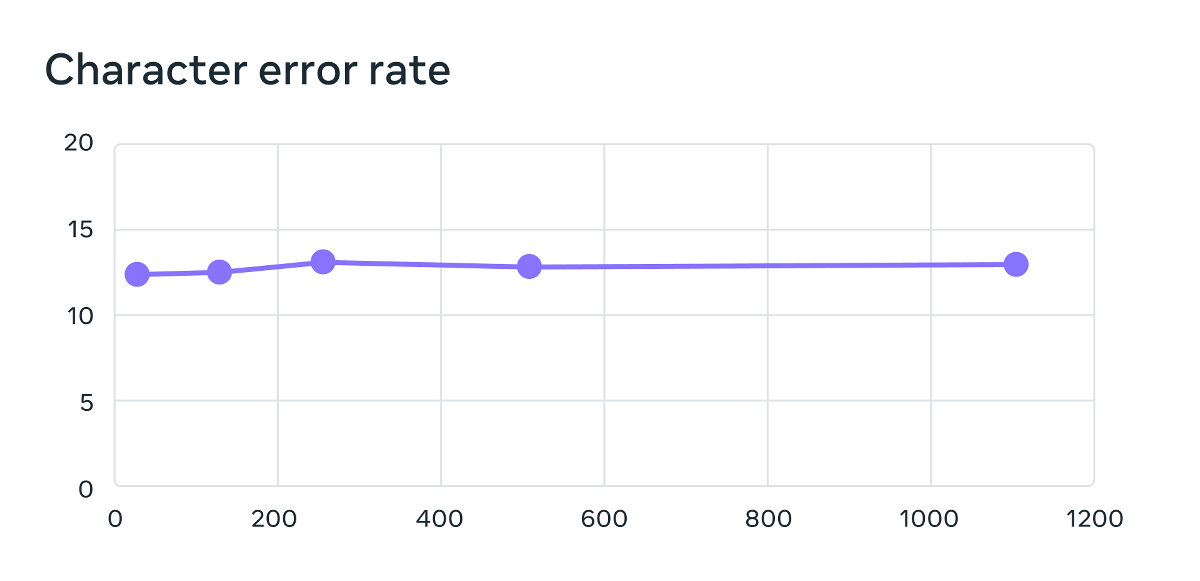
Meta also said that MMS trained using Wav2vec 2.0, which adopted self-supervised learning, increased the error rate by only 0.4% even when the number of languages increased from 61 to 1107.
Meta said, ``Many languages around the world are in danger of disappearing, and the limitations of speech recognition and speech generation technology will accelerate this trend. We envision a world where language is preserved by enabling people to access information and use technology in the language of their choice. MMS is a big step in this direction.' rice field.
Meta publishes the model and code on GitHub so that the research community can pursue further research based on MMS.
fairseq/examples/mms at main facebookresearch/fairseq GitHub
https://github.com/facebookresearch/fairseq/tree/main/examples/mms
Many Twitter users have praised MMS, and one user highly appreciated that MMS is open source.
They're open and available for everyone ???? Meta is the greatest most generous tech company ever https://t.co/U0cOEevCGH pic.twitter.com/46CEL4m2U4
— Bryan Cheong (@bryancsk) May 22, 2023
Related Posts: