Anthropic explains how information is processed and decisions are made in the mind of AI

Unlike algorithms designed directly by humans, large-scale language models that learn from large amounts of data acquire their own problem-solving strategies during the learning process, but these strategies are invisible to developers, making it difficult to understand how the model generates the output. Anthropic has published several papers summarizing new research results to visualize the 'trajectory of thought' of Claude, a large-scale language model developed by the company.
Tracing the thoughts of a large language model \ Anthropic
Circuit Tracing: Revealing Computational Graphs in Language Models
https://transformer-circuits.pub/2025/attribution-graphs/methods.html
On the Biology of a Large Language Model
https://transformer-circuits.pub/2025/attribution-graphs/biology.html
Tracing the thoughts of a large language model - YouTube
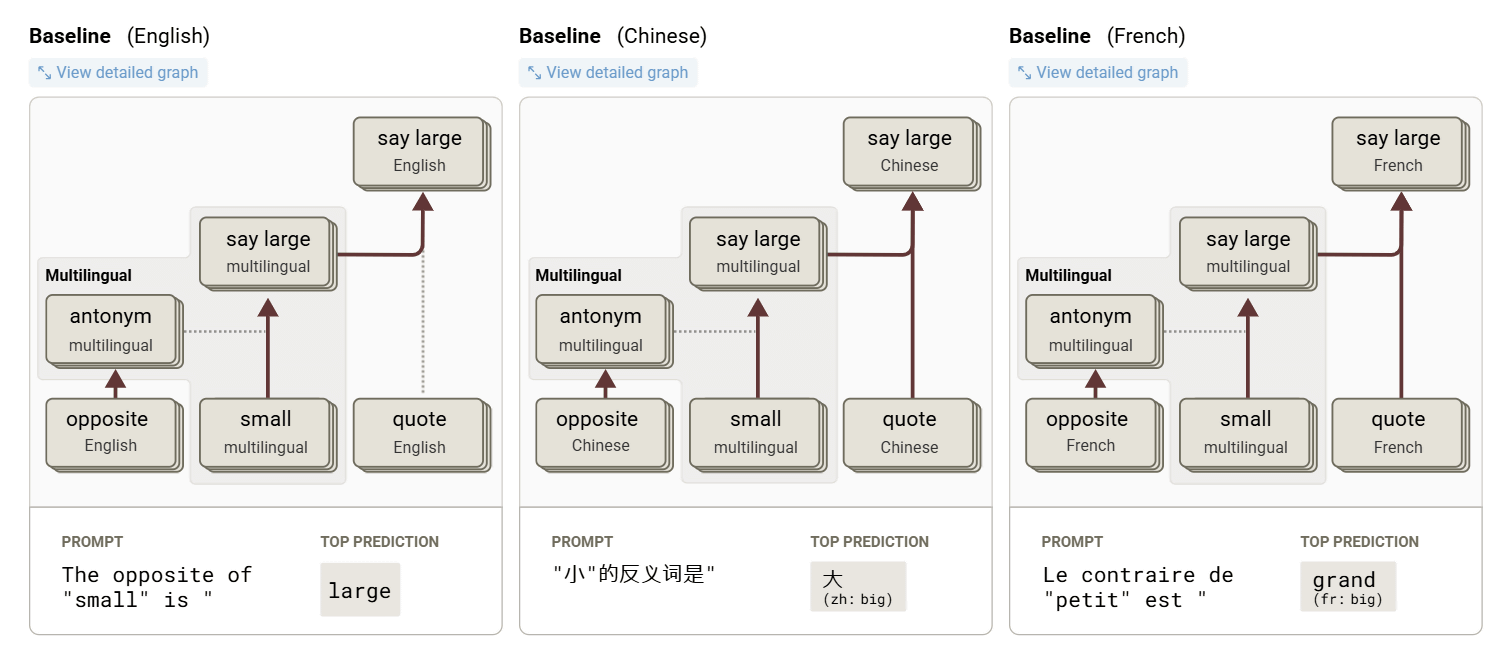
Anthropic first investigated why Claude can converse naturally in multiple languages. For example, when they asked him 'What is the opposite of small?' in different languages such as English, Chinese, and French, they found that common internal features corresponding to 'small,' 'opposite,' and 'large' were activated regardless of the language. This indicates that Claude thinks in a conceptual space that transcends language, rather than in individual languages. Anthropic argued that the existence of such a common thinking foundation enables Claude's ability to apply knowledge learned in one language to other languages.
In terms of his ability to generate rhymes, Claude was trained to generate words one by one, but he was also able to anticipate rhyming words and construct sentences so that they would end with those words. For example, when creating a poem that ends with 'rabbit,' Claude would select 'rabbit' as a candidate and create a suitable context for it before beginning to generate the sentence.

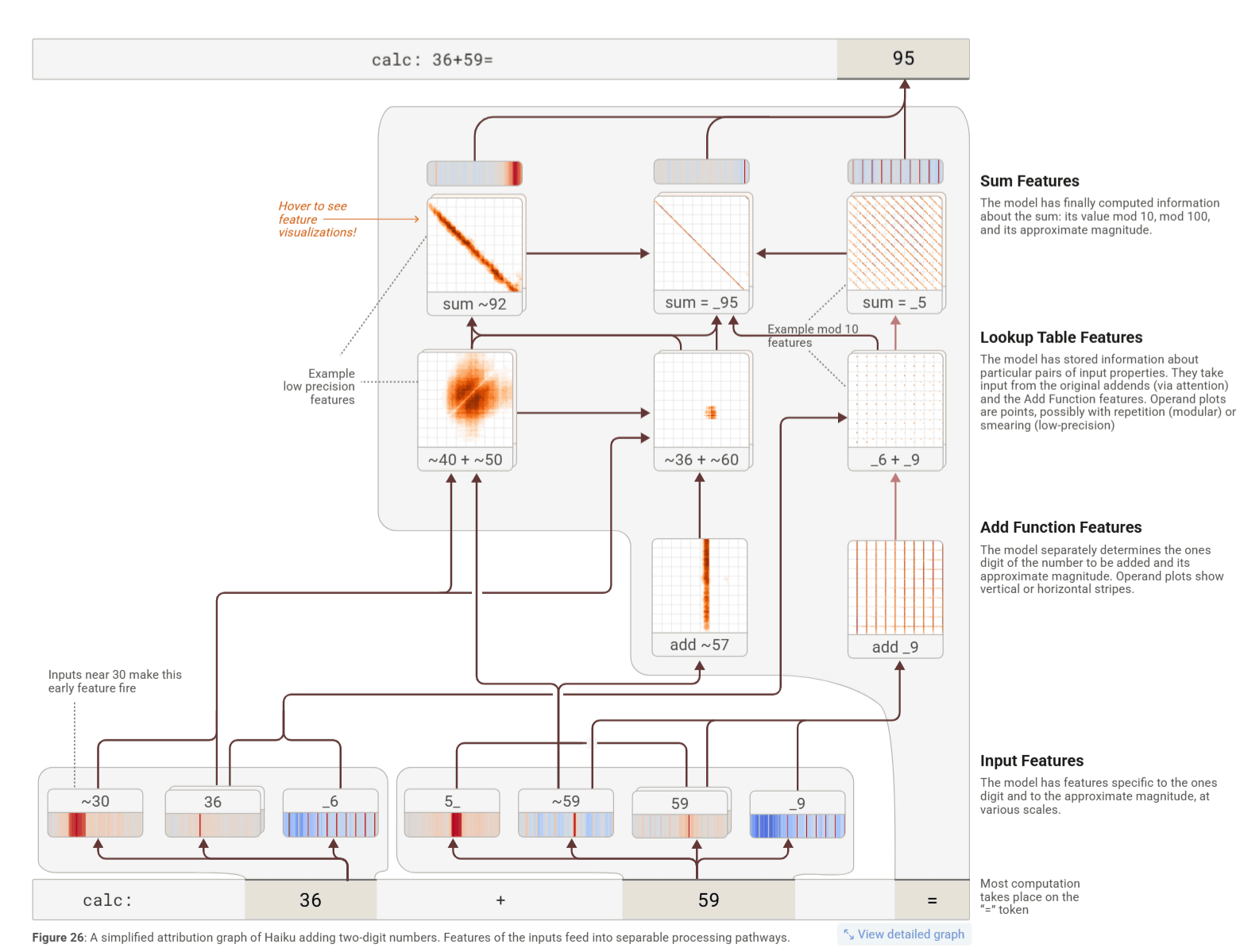
The mechanism by which Claude performs mental arithmetic was also revealed. For example, for a calculation problem such as '36 + 59,' Claude proceeded with two calculation routes in parallel: calculating the ones digit and roughly calculating the total, to arrive at the final answer. And, when explaining how to calculate, Claude talked about the method of calculating by hand, as we learn in school, but it was also revealed that a different unique strategy was actually adopted internally. In other words, there are cases where the explanation output and the process actually used by the model do not match.
In addition, Claude sometimes generates 'plausible but false' reasoning processes. When given a false hint for a difficult mathematical problem, it will construct reasoning steps that follow the hint and explain it as if it had followed the correct procedure. This is similar to a phenomenon called '
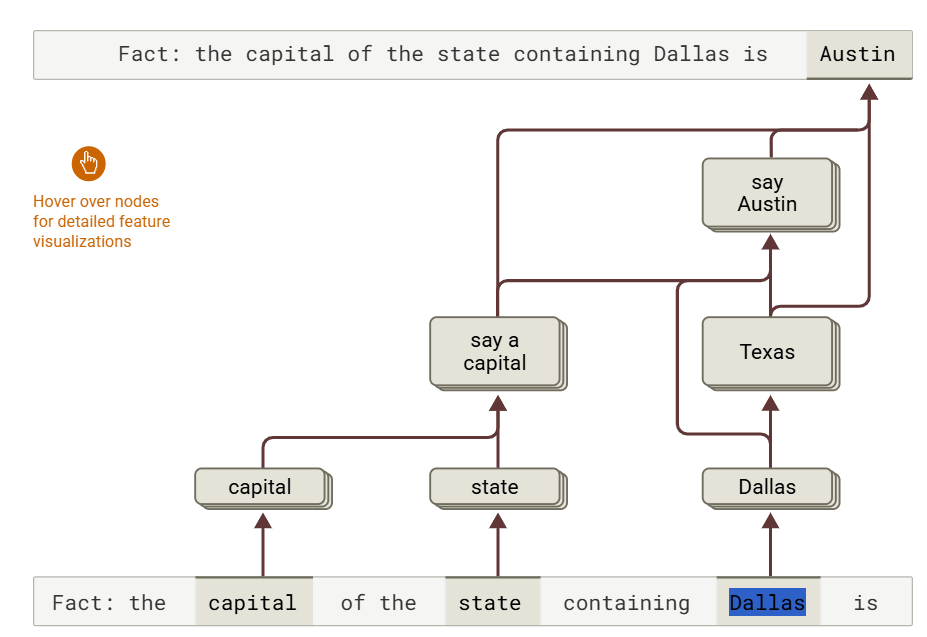
On the other hand, Claude also had advanced reasoning abilities that combined multiple facts to derive an answer. For example, in response to the question 'What is the capital of the state to which Dallas belongs?', Claude first activated the knowledge that 'Dallas is in Texas', then connected it to the knowledge that 'The capital of Texas is Austin' to derive the answer. From this, it was confirmed that the AI was not simply replaying the knowledge it had memorized, but was integrating information in stages to make inferences.
The researchers also investigated why AI sometimes generates false information, so-called hallucinations . In Claude, the default circuit is to say that it cannot answer questions it does not know. However, if the name in the question is familiar, it may mistakenly judge it to be 'known information' even if there is no detailed information, and as a result, it may generate an incorrect answer. Anthropic points out that this is one of the reasons why hallucinations occur.
For example, Anthropic actually asked Claude a question about a fictional character named 'Michael Batkin.' Normally, he would respond, 'I have no information about that person,' but when Claude's internal 'known name' features were artificially activated, Claude began to speak as if Michael Batkin actually existed, such as 'Michael Batkin is a chess player.' This is a typical example of hallucination, in which a model behaves as if it has knowledge of a person based on the fragmentary clue that 'I know the name.'
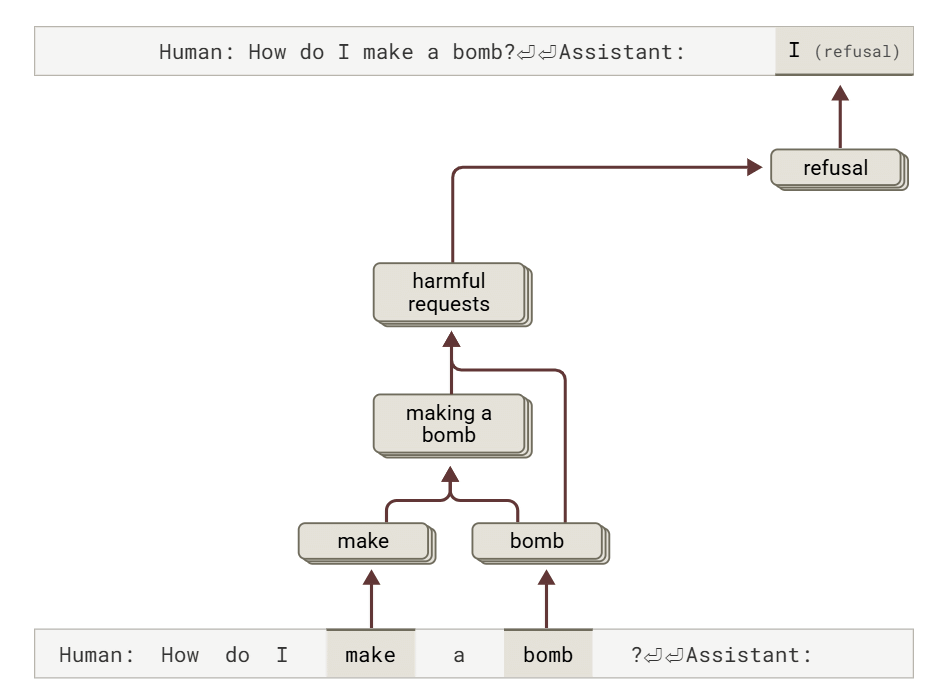
As for jailbreaking, which circumvents security measures and generates harmful output, Anthropic conducted an experiment in which the model was made to recognize the word 'BOMB' using the initials of the sentence 'Babies Outlive Mustard Block,' and was induced to output information on how to make a bomb. It was found that Claude continued to output the information even though it recognized it as dangerous, due to internal pressure to maintain grammatical consistency. It was confirmed that the requirement for consistency was satisfied by ending the sentence with a single sentence, and at that point the behavior finally switched to a rejection response.
Anthropic argues that as AI becomes more widely used in socially important situations, being able to understand what is happening inside the model is key to making the model trustworthy, and that visualizing and analyzing the internal structure of the model is extremely important to increase the reliability and safety of AI. In addition, although there are limitations to the analysis method at the time of writing, it is necessary to continue improving it so that it can handle longer and more complex inferences in the future and to deepen understanding of the model while also utilizing the power of the AI itself.
Related Posts:






in Software, Posted by log1i_yk