``LLaMA-Tokenizer'' that allows you to check what kind of tokens the sentences input to Meta's large-scale language model ``LLaMa'' are recognized as
In recent years, various AIs such as OpenAI's ChatGPT and Google's Bard have become able to have conversations close to the human level. AI basically recognizes sentences in units called '
GitHub - belladoreai/llama-tokenizer-js: JS tokenizer for LLaMA based LLMs
https://github.com/belladoreai/llama-tokenizer-js
Natural language processing (NLP) is required to input prompts to image generation AI, interactive AI, etc. Natural language processing is a technology that extracts content by processing natural language used by humans on a computer. In order to perform natural language processing, it is necessary to first decompose a sentence into words called ' tokens ', perform ' tokenize ' by assigning an ID to each token, and convert it into an input format that can be processed by a computer. The program that visualizes it is 'Tokenizer'.
'LLaMA-Tokenizer' can be executed by using the JavaScript execution environment 'Node.js', and a free web demo is available on the following site, so you can actually try it.
llama-tokenizer-js playground
https://belladoreai.github.io/llama-tokenizer-js/example-demo/build/
The screen of LLaMA-Tokenizer looks like this.
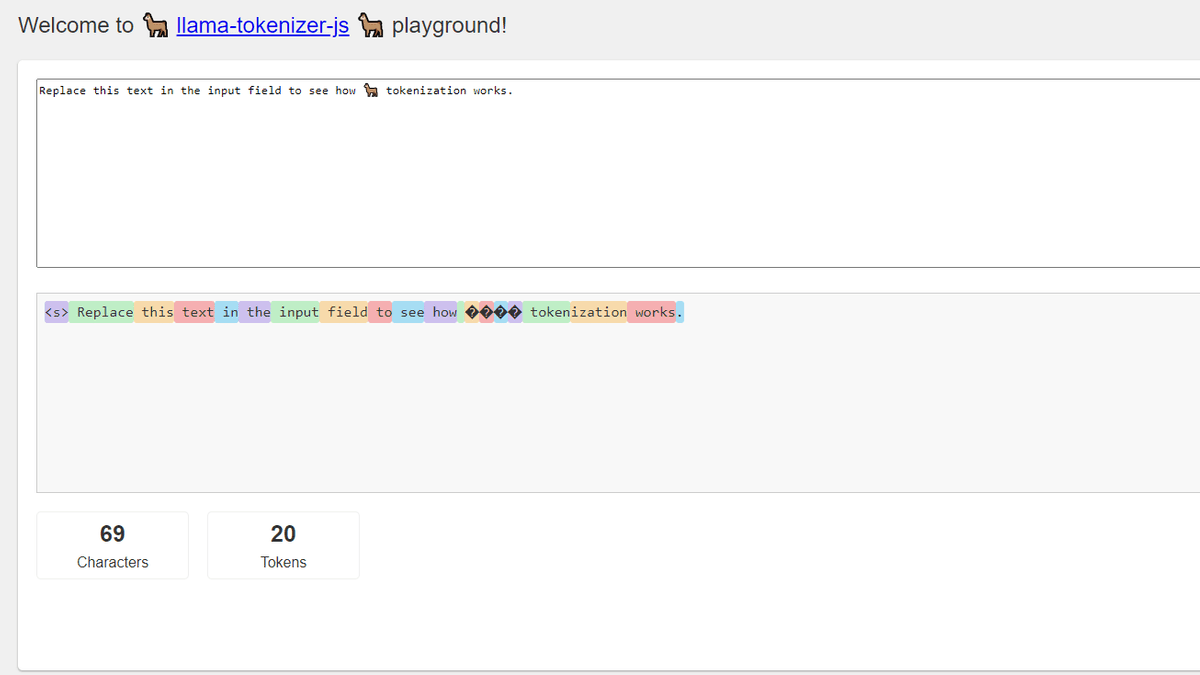
In the case of the 69-character English sentence 'Replace this text in the input field to see how ???? tokenization works.' displayed from the beginning, it seems that it will be 20 tokens. A color-coded 'Replace this text in the input field to see how ???? tokenization works.' will be output at the bottom.
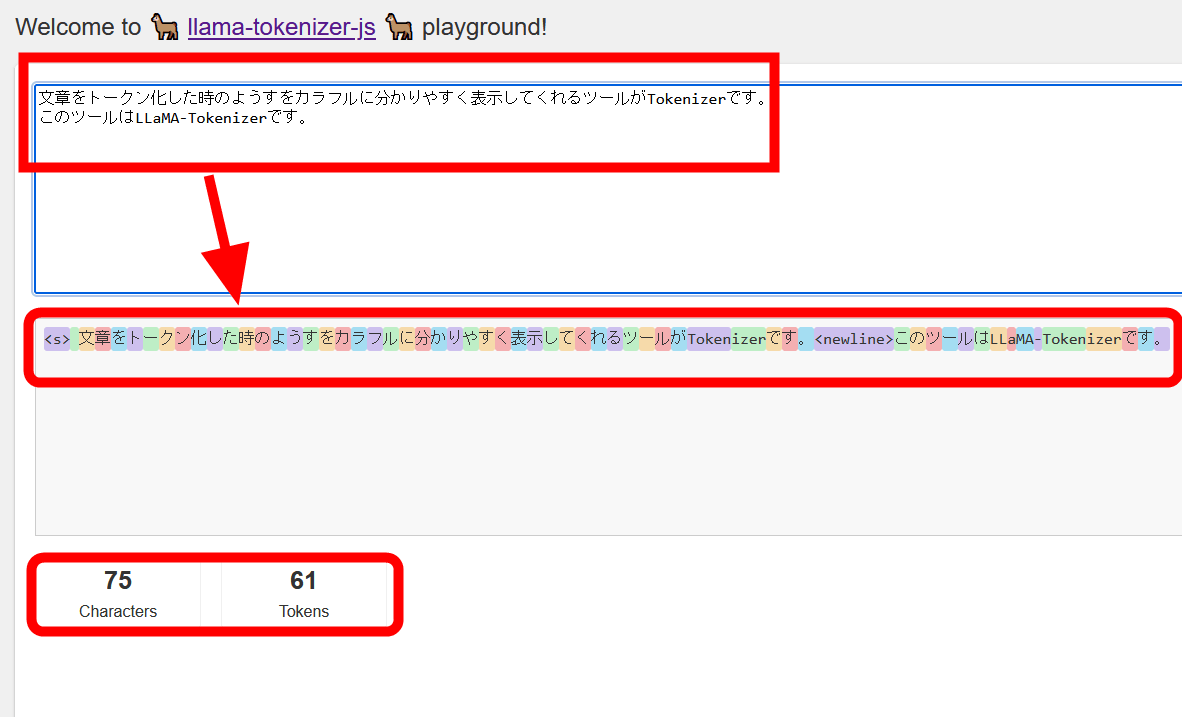
The result of entering Japanese is like this. A sentence of 75 characters resulted in 61 tokens. In Japanese, words are separated one by one when tokenizing, so the number of tokens increases compared to English.
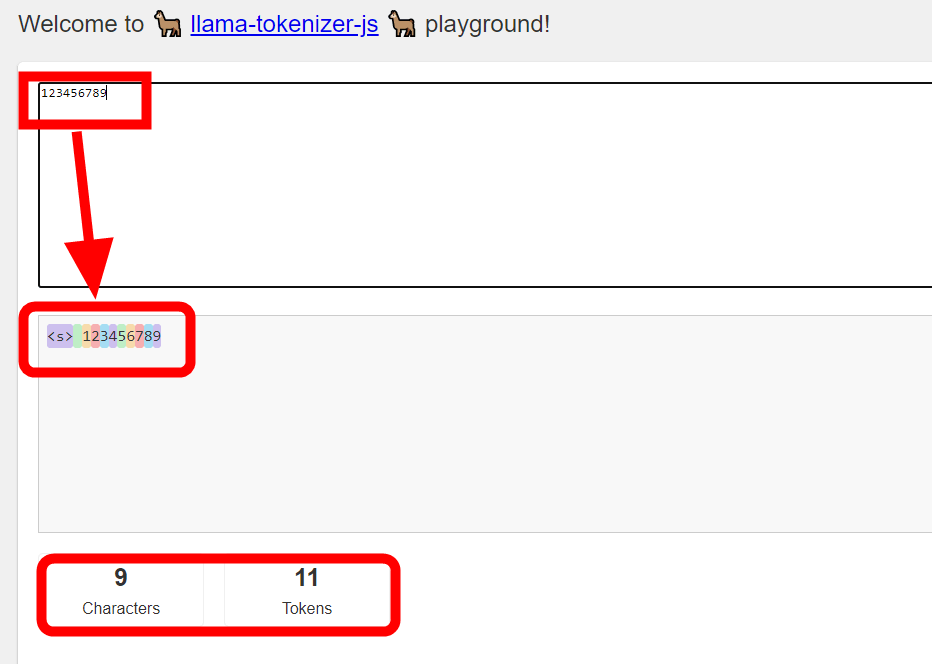
I tried entering a series of numbers. When I entered '123456789', after inserting '[s]' indicating the start of the token and a space, it was separated into tokens one by one, making a total of 11 tokens.
Belladore , the developer of LLaMA-Tokenizer, said, ``One of the most popular tokenizer applications today is the one published by OpenAI. I don't understand why you're trying to count tokens with OpenAI's tokenizer.'
'Tokenizer' that you can see at a glance how chat AI such as ChatGPT recognizes sentences as tokens - GIGAZINE

According to Belladore, the results of his own tests revealed that the number of tokens differed by an average of 20% when comparing OpenAI's tokenizer and LLaMA-Tokenizer. ``If you use OpenAI's tokenizer to measure the number of prompts to enter into LLaMA, you can only get a rough figure,'' he points out.
In addition, LLaMA-Tokenizer has a wide range of models such as 'wizard-vicuna-13b-uncensored-gptq' and 'manticore-7b-ggml' for OpenAI's tokenizer, which was only compatible with GPT-3 and Codex. It is said to be compatible with On the other hand, LLaMA-Tokenizer is not compatible with models learned from scratch like OpenLLaMA .
The source code of LLaMA-Tokenizer is published at the following link.
GitHub - belladoreai/llama-tokenizer-js: JS tokenizer for LLaMA based LLMs
https://github.com/belladoreai/llama-tokenizer-js
Related Posts:


in Software, Posted by darkhorse_log