Open source and commercially available language model 'MPT-7B' release, accepting sentences twice as long as GPT-4

MosaicML, a company that provides systems for machine learning training, has introduced a new standard for open source and commercially available large-scale language models (LLM) ' MPT (MosaicML Pretrained Transformer)-7B '. A basic model of MPT and three variations that can be built on this basic model have been published.
Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs

MPT-7B has the same quality as Meta's large-scale language model '
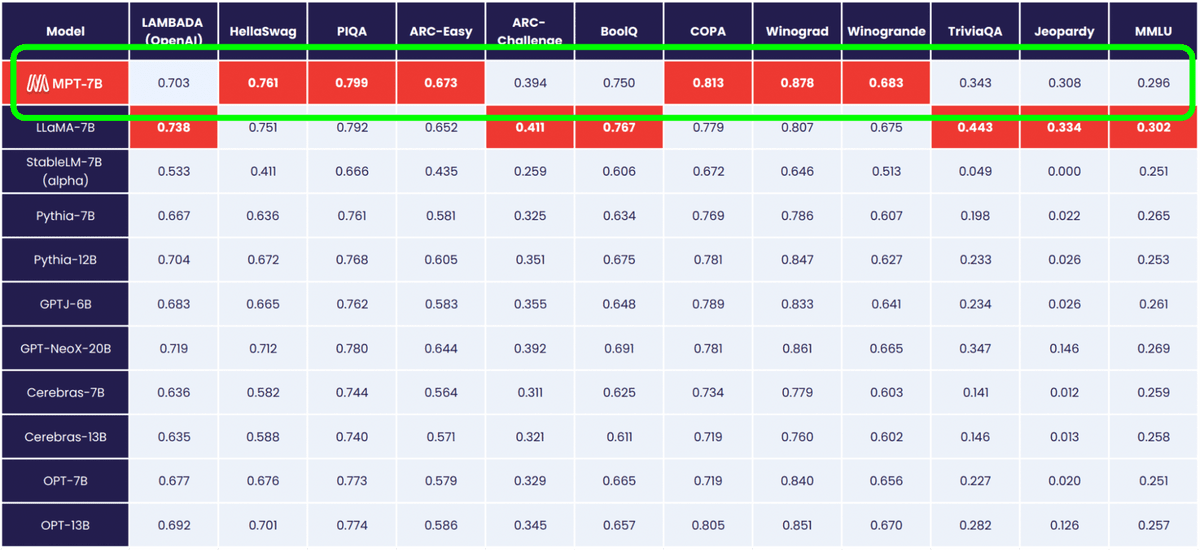
There are four variations of MPT-7B as follows.
MPT-7B Base is a decoder-style transformer with 67 billion parameters, trained on 1 trillion tokens of text and code managed by MosaicML's data team.
◆MPT-7B-StoryWriter-65k+
The MPT-7B-StoryWriter-65k+ is a model designed for reading and writing stories with very long context lengths. It is capable of inferring over 65,000 tokens and has demonstrated operation with 84,000 tokens on a single node with A100-80GB GPU.
◆MPT-7B-Instruct
MPT-7B-Instruct is a model for following short-form instructions.
◆MPT-7B-Chat
MPT-7B-Chat is a chatbot-like model for dialogue generation. Built by fine-tuning MPT-7B with the ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless and Evol-Instruct datasets.
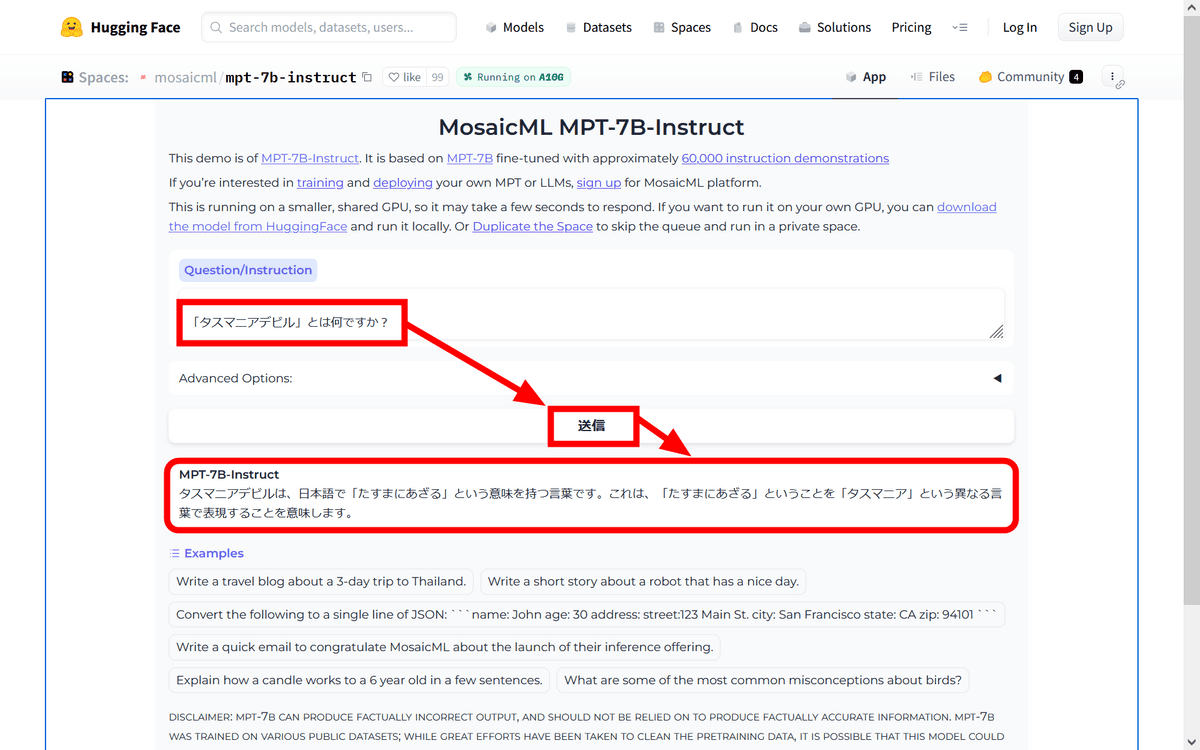
Since the demo page was actually published, I tried the demo of MPT-7B-Instruct . Referring to the example question 'What is a quoll? (What is a possum?)' written by MosaicLM, first enter 'What is a Tasmanian Devil?' in Japanese and click 'Send'. bottom. Then, MPT-7B-Instruct output the answer, 'Tasmanian Devil is a word that means'Tasuma no Azaru' in Japanese.'
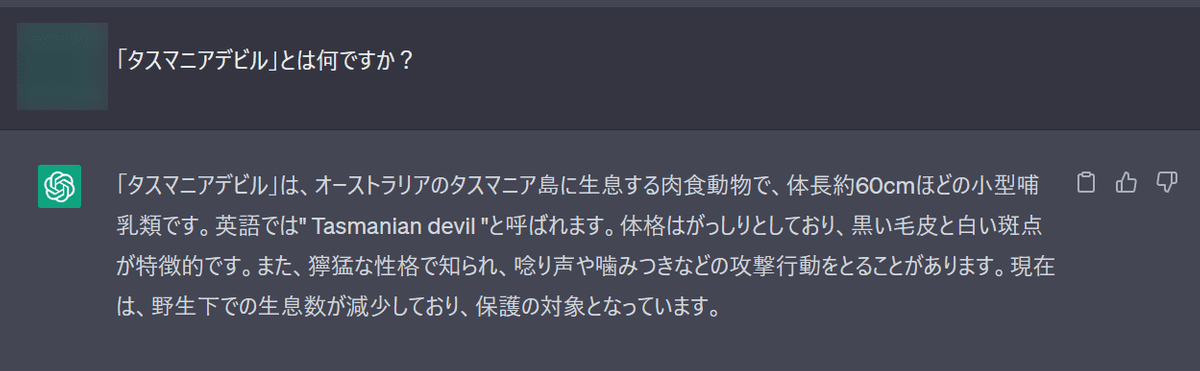
Enter in English this time. It seems to output a plausible answer, but it contains the wrong answer 'My alias is thylacine' and meaningless footnote numbers such as '[1]'. rice field. It doesn't seem to be copied directly from the English Wikipedia, so it's unclear where the footnote came from.

When I tried it with ChatGPT (GPT-3.5), the following sentence was generated.
This time I copied and entered the prompt exactly from the example question on the demo page. Then, I output '3 days Thailand travel blog' with about 900 characters. All proper nouns that appeared in the answers, such as
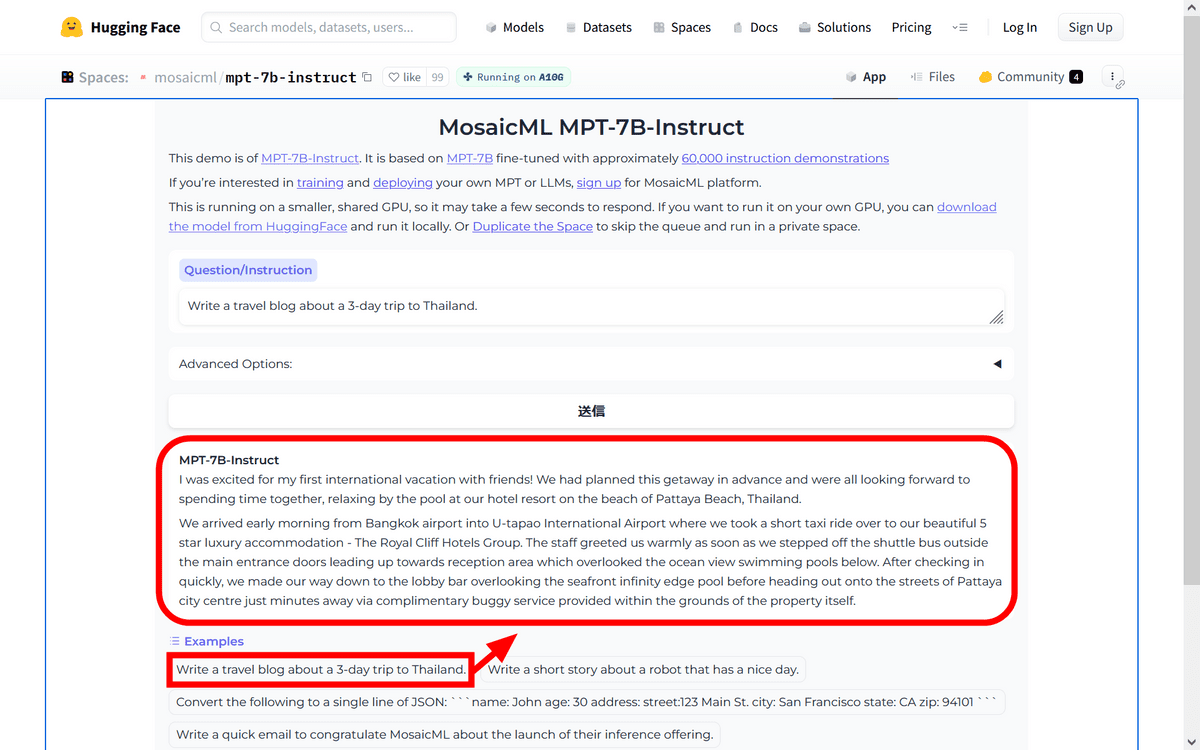
When I asked a similar question on ChatGPT, the answer was output in about 1900 characters.
Most open source language models can only handle sequences up to a few thousand tokens. However, with the MosaicML platform and a single 8xA100-40GB node, MPT-7B can be easily tweaked to handle up to 65,000 context lengths.
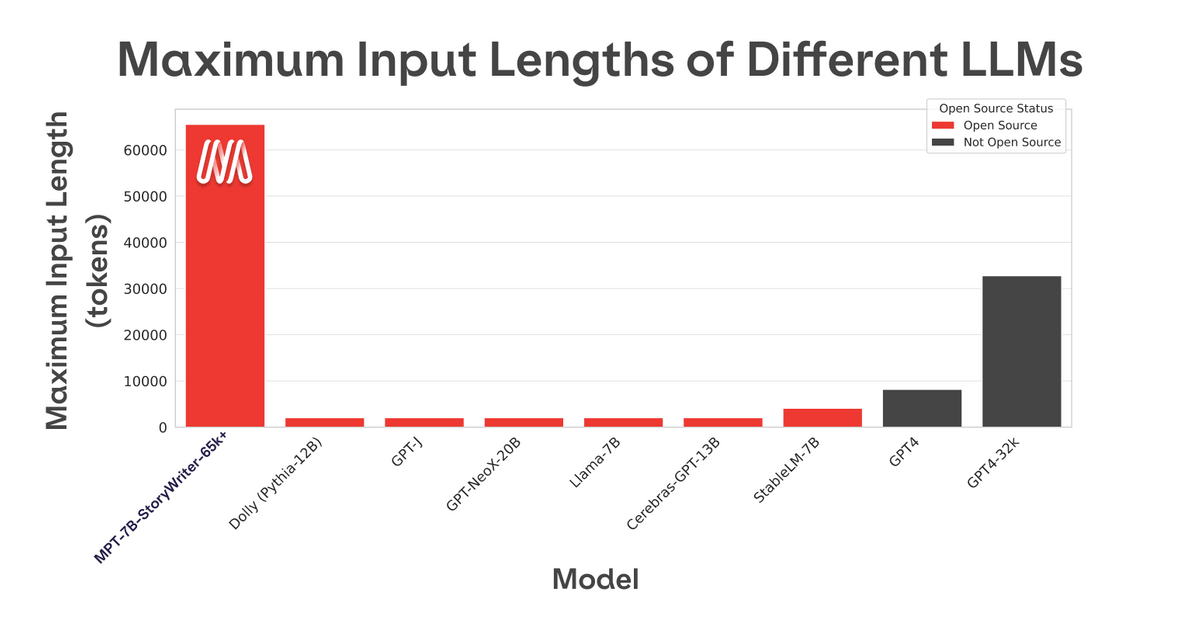
MPT-7B-StoryWriter-65k+ is a model that can process 65,000 tokens. This is double GPT-4, which can handle about 8,000 or about 32,000 tokens. When MPT-7B reads a novel '
It is said that the four models were successfully built in just a few weeks, and it is quite possible that similar models will be born one after another in the future. MosaicML says, “Think of MPT-7B as a demonstration. MPT-7B is just the beginning. We will continue to create quality basic models, and some models are already being trained. Please look forward to it.”

Related Posts:







in Software, Posted by log1p_kr