Detailed illustration of how the image generation AI 'Stable Diffusion' generates images from text

'
The Illustrated Stable Diffusion – Jay Alammar – Visualizing machine learning one concept at a time.
https://jalammar.github.io/illustrated-stable-diffusion/
Alamar argues that the advent of AI, which generates striking images from text, will change the way humans create art. With the release of Stable Diffusion, he said that anyone can use high-performance models with relatively cheap resources, and explained how Stable Diffusion generates images using illustrations.
◆ Stable Diffusion components
Simplified Stable Diffusion from the user's point of view is as follows. If you enter the text 'paradise cosmic beach', a similar image will be generated.

In addition, it is also possible to change the image further by matching the text 'Pirate ship' to the image generated above.

Stable Diffusion is a system composed of multiple components and models, and can be roughly divided into a 'text encoder' that understands text and an 'image generator' that generates images based on it.

Furthermore, the image generator is divided into two, 'image information creator' and 'image decoder'.

The main components are the ``text encoder (ClipText)'' that outputs the input text to 77 token embedding vectors of 768 dimensions, and the ``image information creator ( UNet + Scheduler)”, and an “autoencoder/decoder” that outputs the input image information tensor to an image consisting of color, width, and height.

◆ Diffusion model
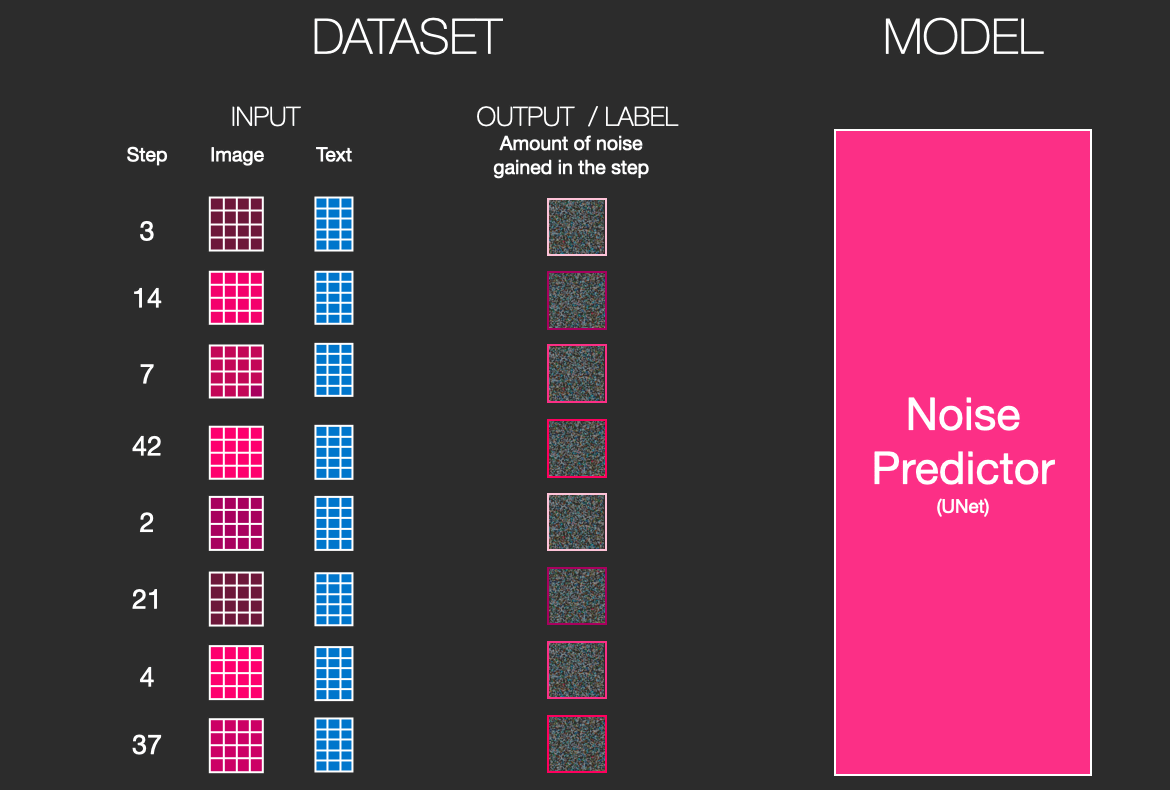
Diffusion in Stable Diffusion is a process that takes place inside the Image Information Creator. Diffusion models consider the problem of repeatedly adding noise to an image to generate a noise-only image, and predicting at a given point in time how much noise was added in the previous step.
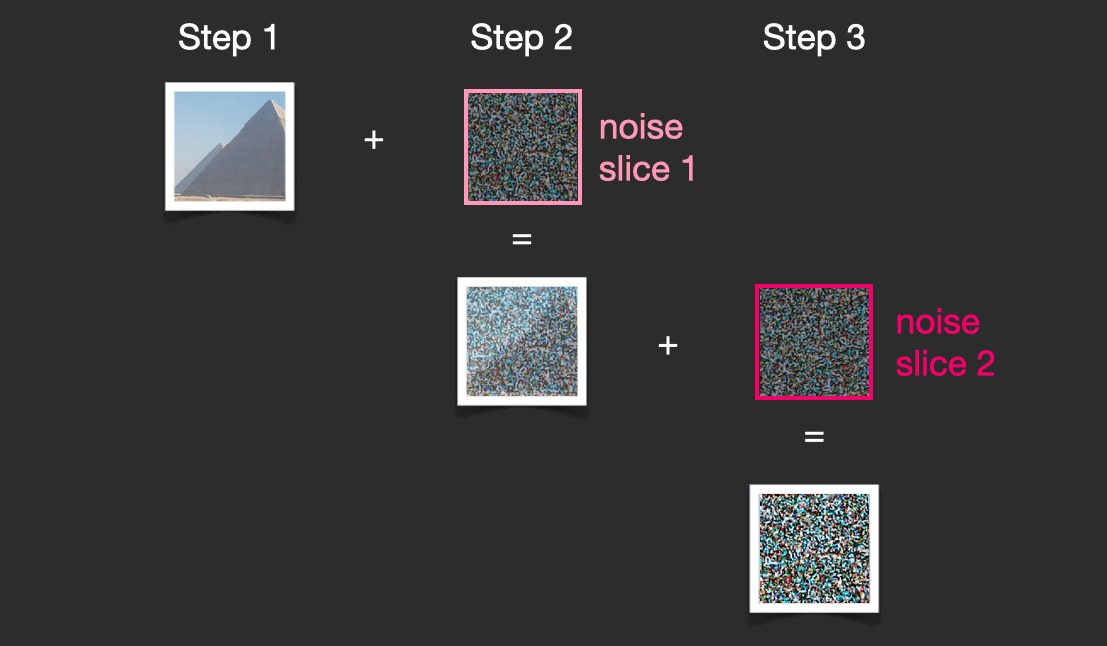
Diffusion model training can generate dozens of training samples for every image in the dataset by adjusting the amount of noise added to the images. This is a process called 'diffusion'.
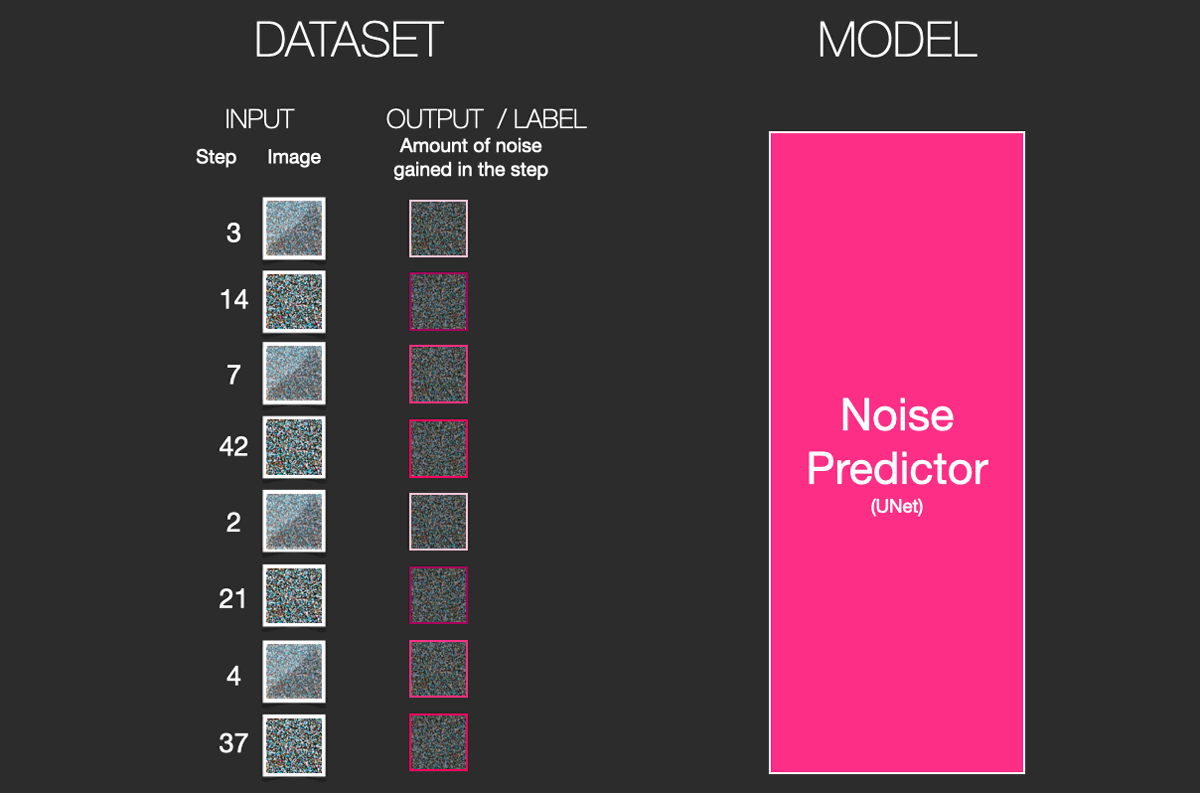
A diffusion model trained on enough training samples can reverse the diffusion process. In other words, by repeatedly predicting and removing the noise added to the image in the previous step, it will eventually be possible to obtain a clean image.

Stable diffusion uses a lower-dimensional
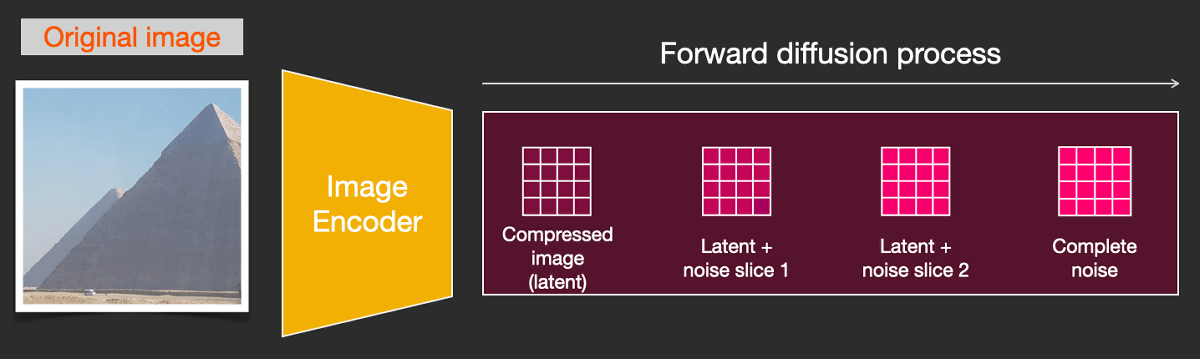
Even in this case it is possible to reverse the diffusion process and produce a clean latent space version of the image. Finally, through an image decoder, we generate an image in pixel space from the latent space information.
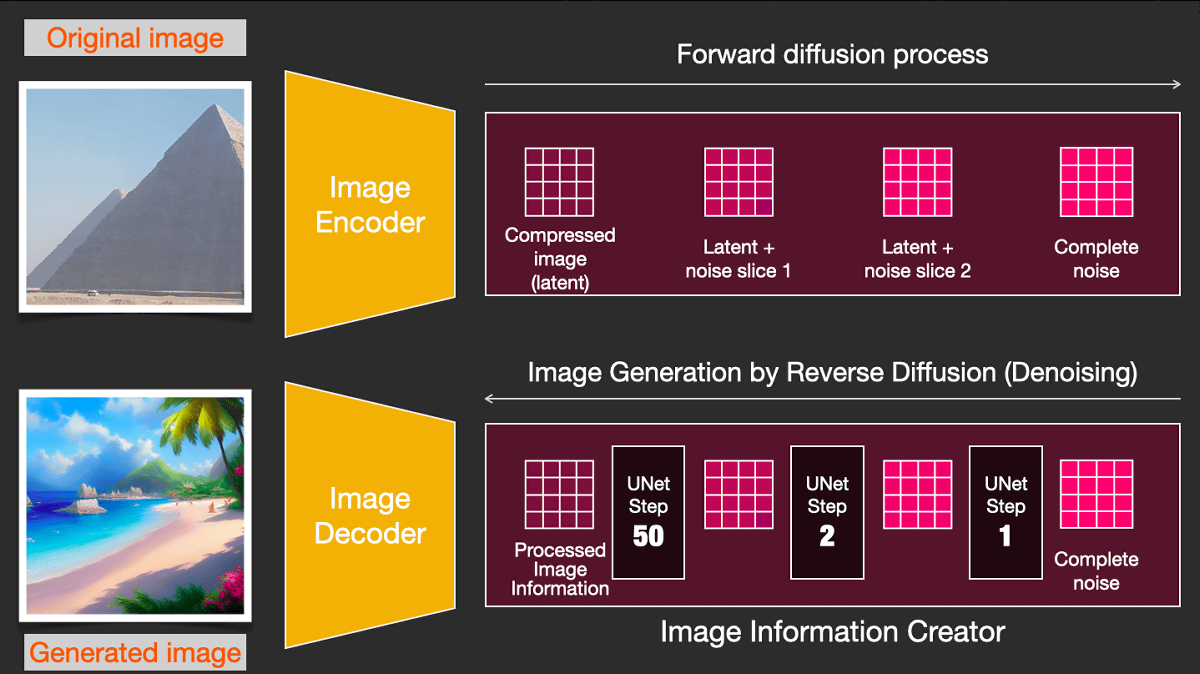
◆Text Encoder
Stable Diffusion does not just generate an image, it generates an image based on the input text, so a diffusion model using the latent space is not enough. Stable Diffusion at the time of writing the article uses a pre-trained model called

CLIP is a combination of an image encoder and a text encoder that learns training data, compares the results, and feeds them into the model to improve accuracy. By repeating this throughout the dataset, it will be possible to associate the text 'dog' with the image of the dog.
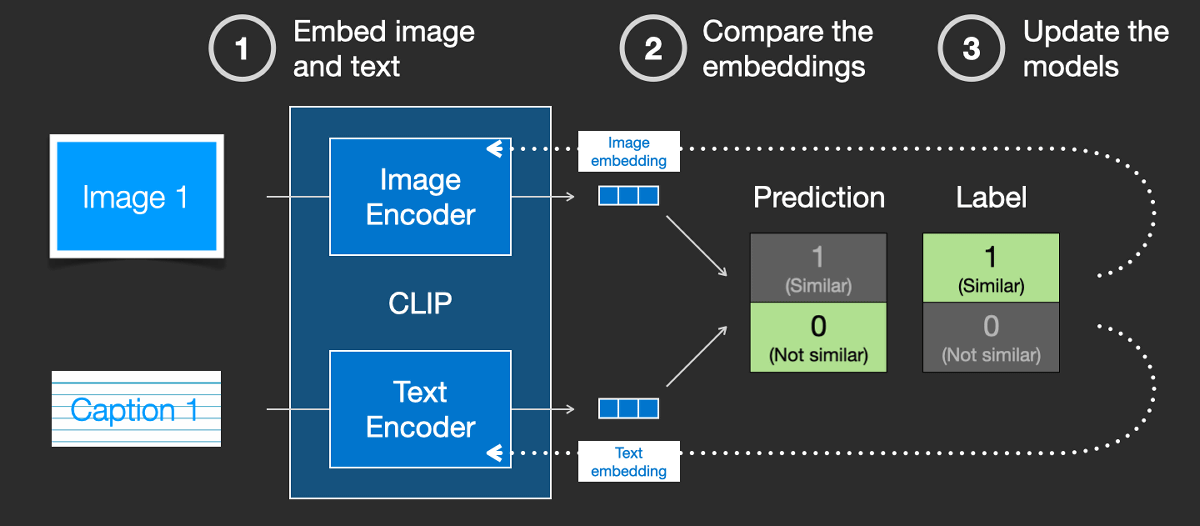
In order to combine the text data into the image generation process of the diffusion model, Stable Diffusion is trained by inputting text encoded in the latent space along with noise. By doing this, it is possible to consider the text data when removing noise and generate an image along the text.
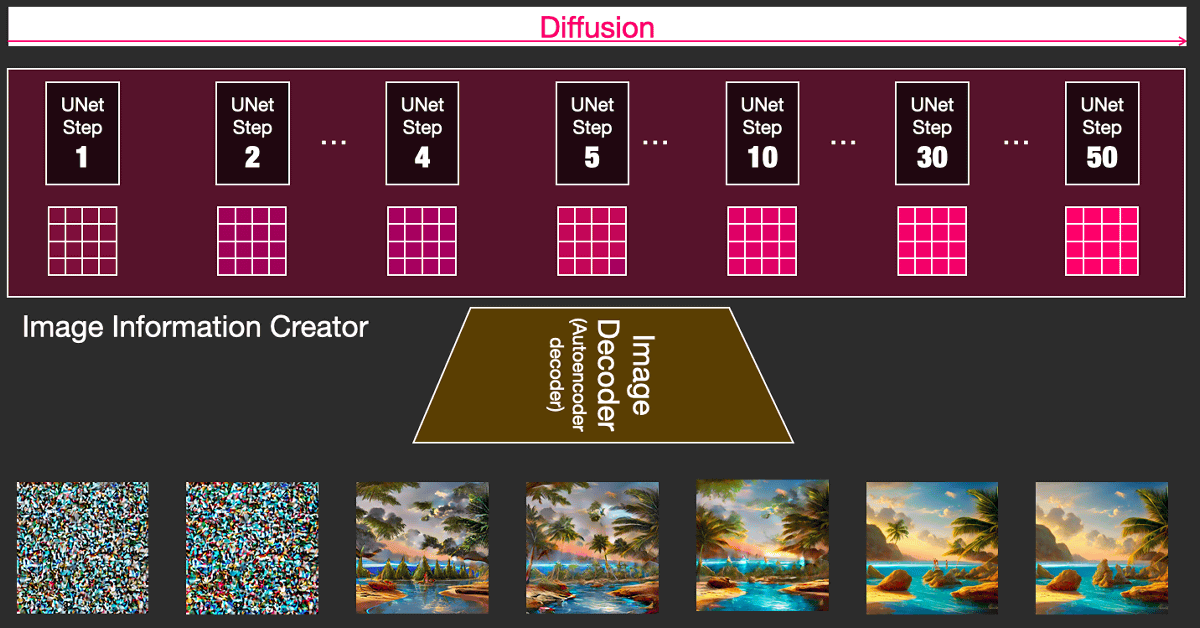
◆ Stable Diffusion image generation
This is a diagram showing image generation in Stable Diffusion.

If each step processed in the latent space is output as an image by the decoder one by one, it looks like this. You can see that the image suddenly looks like it between step 2 and step 4.
Related Posts:








in Software, Web Service, Science, Posted by log1h_ik