What is the mechanism of image generation AI 'Stable Diffusion' that raises issues such as artist rights violations and pornography generation?

The image generation AI '
Stable Diffusion: Best Open Source Version of DALL E 2 | by Nir Barazida | Aug, 2022 | Towards Data Science
https://towardsdatascience.com/stable-diffusion-best-open-source-version-of-dall-e-2-ebcdf1cb64bc
Stable Diffusion is an image generation AI co-developed by London and California-based startup Stability AI and university researchers, trained on LAION Aesthetics , a dataset that emphasizes 'beauty'. The technology itself of 'generating an image based on the entered text' has existed for a long time, but Mr. Brazida said that Stable Diffusion is innovative in terms of the accuracy of the generated image, and it is also surprising that it is an open source project. said to be worthy of
According to Brazida, the model used for Stable Diffusion is the latent diffusion model , which is also used in the image generation AI ` ` DALL E2 '' developed by OpenAI. A basic diffusion model is trained to add and corrupt the training data with Gaussian noise until it is pure noise, then reverse the process to denoise and restore the image. AI after learning can generate data from pure noise by executing the reverse corruption process, and by adding conditions to it, it is possible to generate arbitrary images.
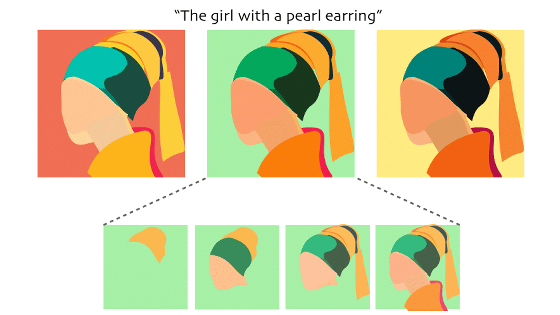
The following shows the data corruption process (right arrow) and the restoration process (left arrow) by the diffusion model.

The basic diffusion model requires a large number of iterative processes for noise reduction, which requires a large amount of computational resources. However, the latent diffusion model used in Stable Diffusion uses a lower dimensional
The architecture of Stable Diffusion consists of ``an autoencoder that reduces random noise to a lower dimensional latent space and converts it to the original dimensional latent space after processing'', ``a U-Net block that removes noise'', and ``a It consists of three main components: a text encoder for processing. Brazida explains that this mechanism allows Stable Diffusion to run on a GPU with a relatively lightweight 10GB VRAM.
In general, a metric called Fréchet starting distance (FID) is used to compare the quality of images generated by image generation AI, but Stable Diffusion publishes a benchmark score that allows comparison with other AIs. not. Therefore, Mr. Brazida used a mechanism of ``generating an image based on text'' and conducted a test of ``inputting the same sentence with multiple models and comparing the accuracy''.
Mr. Brazida actually wrote the sentence ' Boston Terrier with a mermaid tail, at the bottom of the ocean, dramatic, digital art.' , Stable Diffusion (left) and DALL E2 (right) are compared below. Although Stable Diffusion certainly depicts a dog that can be identified as a Boston Terrier, it is an image that is on a fish instead of having a mermaid's tail. On the other hand, you can see that DALL E2 generates images that are fairly faithful to the text.

Also, this is what was generated with the sentence 'A Boston Terrier jedi holding a dark green lightsaber, photorealistic'. For DALL E2, you can clearly see how you have a lightsaber, and the image clearly reflects the text.

However, Mr. Brazida compares not only with the non-open source DALL E2, but also with the same open source image generation AI called

Mr. Brazida acknowledged that Stable Diffusion is indeed an excellent image generation AI, but also pointed out that it has caused a lot of discussion in a short period of time after its appearance. “Unlike DALL E2, Stable Diffusion has very few restrictions on what content it can generate. When it was released, users tested its limits and did not consent to the use of images, pornographic images, or materials of people based on their names. 'Stable Diffusion is a major improvement in all aspects compared to the previous text-to-image generation model, and is state-of-the-art.' 'It's delivered results, and I can't wait to see what the future holds in this area, but the implications are worrying.'
AI that generates images that look like they were drawn by a human artist is criticized for ``infringing on the artist's rights''-GIGAZINE

Related Posts: