Microsoft develops ``LLMLingua'' technology that highly compresses input prompts for large-scale language models while preserving meaning

In recent years, various large-scale language models have emerged, and many methods have been created to obtain highly accurate answers by devising input prompts. However, if the input prompt is too long, there are disadvantages such as exceeding the chat window limit and increasing API costs. Therefore, a research team at Microsoft Research has developed a new technology, LLMLingua , that compresses input prompts while preserving their meaning.
LLMLingua | Designing a Language for LLMs via Prompt Compression
LLMLingua - Microsoft Research
https://www.microsoft.com/en-us/research/project/llmlingua/
LLMLingua: Innovating LLM efficiency with prompt compression - Microsoft Research
https://www.microsoft.com/en-us/research/blog/llmlingua-innovating-llm-efficiency-with-prompt-compression/
It is widely known that in order to obtain highly accurate answers with large-scale language models, input prompts must be devised. With the emergence of technologies such as chain-of-thought (CoT) and in-context learning (ICL) , we are increasingly writing long prompts to elicit high-quality answers. .
In some cases, prompts can reach tens of thousands of tokens, but if the prompts are too long, they may exceed the chat window limit, make it difficult to respond with context, or cause API response delays. Problems such as ``API usage fees required for input and output are high'' also occur.
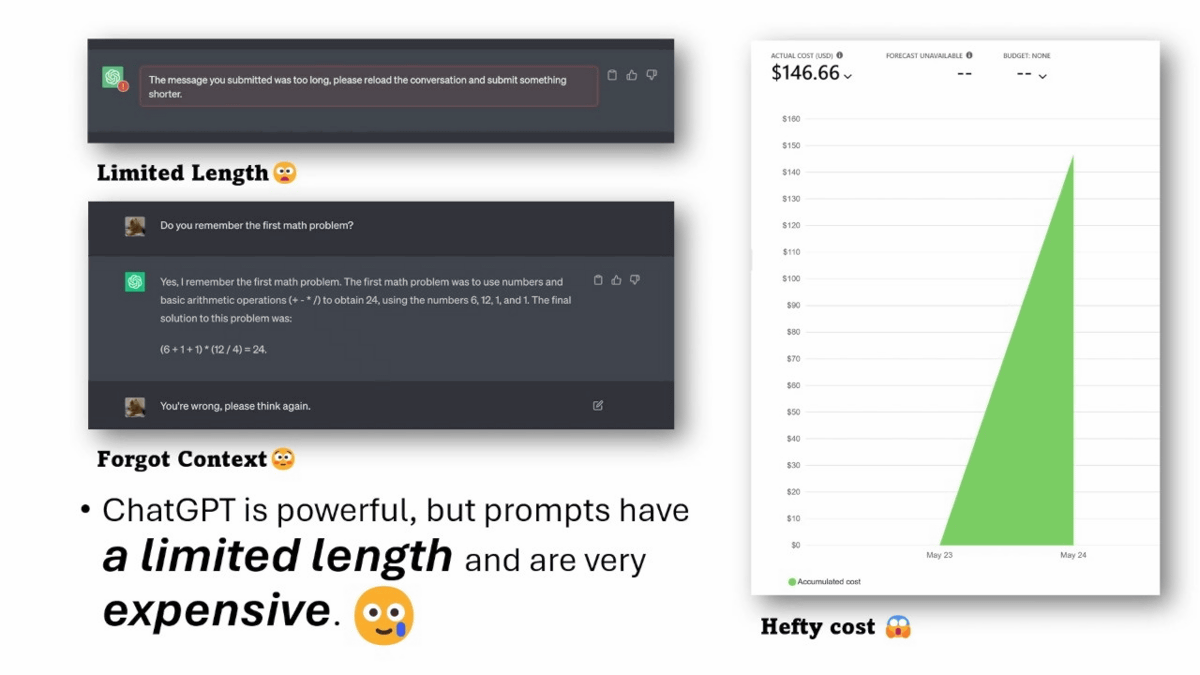
To address the problem of input prompts for large-scale language models becoming too long, a research team at Microsoft Research has developed a technology called LLMLingua that compresses prompts while preserving their meaning.
In developing LLMLingua, the research team adopted a mechanism called ``budget controller'' to balance language consistency and module sensitivity within prompts. This uses small, well-trained language models such as GPT2-small and LLaMA-7B to identify unimportant tokens and exclude them from the prompt. Furthermore, in addition to compressing the remaining tokens individually, the company uses an iterative token-level compression approach to further refine the relationships between individual tokens.
This allows us to compress input prompts by eliminating the redundancy that is common in the natural languages that humans normally use, while preserving the amount of information that large-scale language models can understand. For example, in the image below, the original prompt used 2366 tokens, while the LLMLingua-processed prompt has been compressed to just 117 tokens.
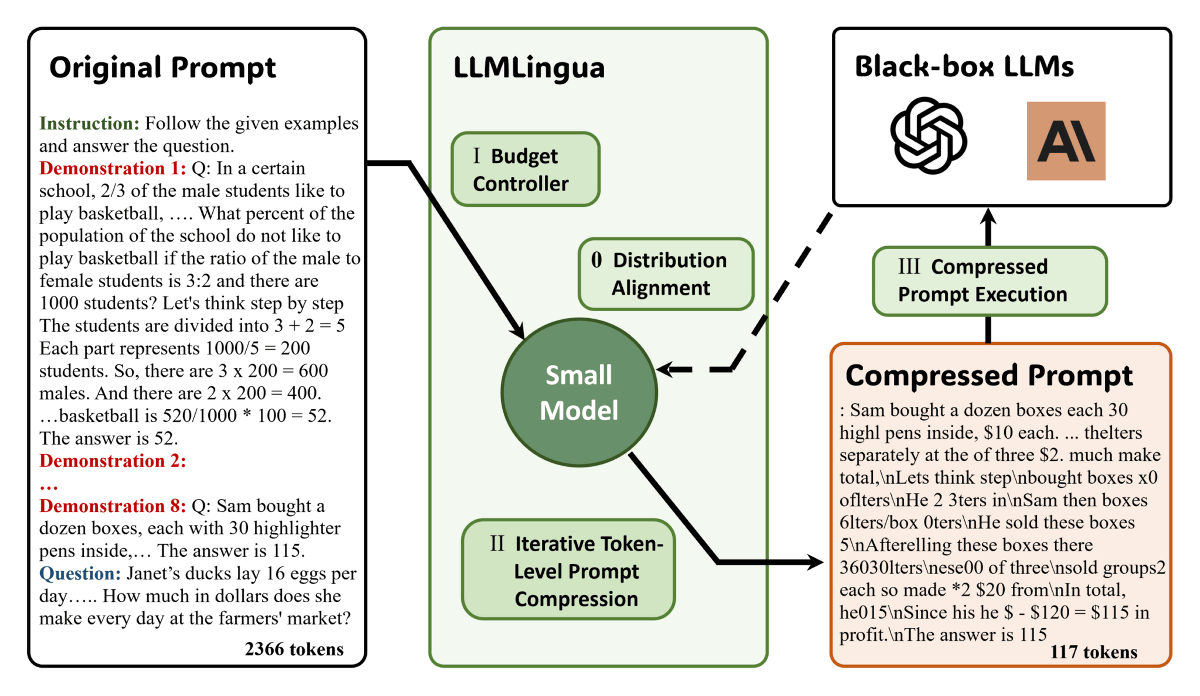
Although the processed prompt is difficult for humans to read, it retains enough information for the large-scale language model to output an answer. Social news site

To evaluate the performance of LLMLingua, the research team tested the compressed prompts generated by LLMLingua using four different datasets: GSM8K, BBH, ShareGPT, and Arxiv-March23. LLaMA-7B was used for the small language model used for the budget controller, and GPT-3.5-Turbo-0301 was used for the large-scale language model.
Testing has shown that LLMLingua achieved up to 20x compression while preserving the meaning of the original prompt, especially in ICL and inference, and was able to continue preserving prompt meaning in dialogue and summaries. It has also been reported that not only the input but also the number of answer tokens generated by the large-scale language model decreased as the input prompt was compressed.

Furthermore, when the input prompts compressed with LLMLingua were decompressed using GPT-4, all important inference information could be recovered from the entire 9-stage CoT prompt.
The source code of LLMLingua is available on GitHub.
GitHub - microsoft/LLMLingua: To speed up LLMs' inference and enhance LLM's perceive of key information, compress the prompt and KV-Cache, which achieves up to 20x compression with minimal performance loss.
https://github.com/microsoft/LLMLingua
Related Posts:







in Software, Web Service, Posted by log1h_ik