OpenAI announces it has broken down GPT-4's thoughts into 16 million interpretable patterns

Large-scale language models such as GPT-4 have very high performance, but even developers cannot understand how each model thinks and outputs a response. OpenAI has recently developed a method to read the thoughts of large-scale language models and announced that it has been able to break down GPT-4's thoughts into 16 million interpretable patterns.
Extracting Concepts from GPT-4 | OpenAI
Scaling and evaluating sparse autoencoders
https://cdn.openai.com/papers/sparse-autoencoders.pdf

Since general software is developed based on human design, it is possible to modify functions and evaluate safety after understanding the mechanism of each function. On the other hand, in the development of AI, although the 'neural network learning algorithm' itself is designed by humans, 'neural network learning' is performed automatically, so it is difficult for humans to decipher the thinking mechanism of the completed neural network, and it is also difficult to modify or evaluate it.
AI researchers are working on developing methods to understand how neural networks think, and in October 2023, a method was announced that groups neural networks into units called 'features' rather than neuron units. By classifying neural networks by feature, it is possible to find interpretable patterns such as 'features that respond to legal texts' and 'features that respond to DNA sequences,' which is expected to lead to an understanding of how neural networks work.
Attempt to divide the contents of neural network to analyze and control AI operation succeeded, the key is to organize it into 'feature' units rather than neuron units - GIGAZINE

When a large-scale language model generates each token in a sentence, only a small part of the huge neural network fires (sends a signal). However, to capture the features of a neural network, it is necessary to capture not only a small part but the whole. This operation of 'capturing the whole from a small part of the firing and finding features' is performed by a 'sparse autoencoder', but the existing sparse autoencoder development method had the problem that 'it cannot handle huge large-scale language models'.
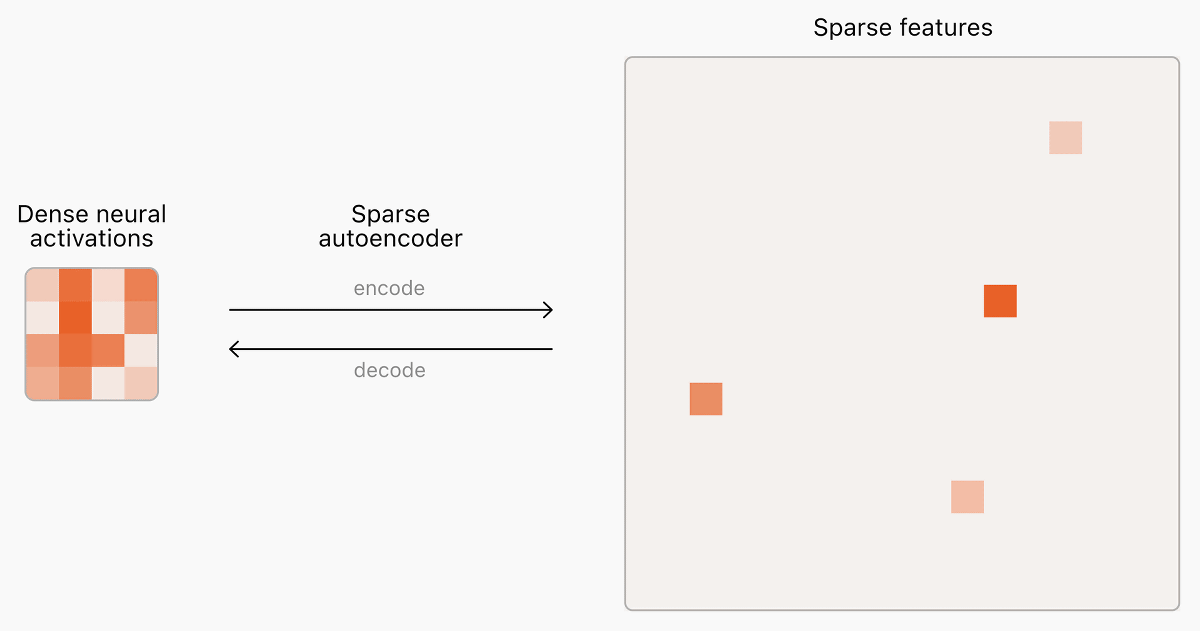
Recently, OpenAI has improved the development method of sparse autoencoders and succeeded in creating a sparse autoencoder that can support GPT-4 and GPT-2 small. In particular, the sparse autoencoder that supports GPT-4 was able to find 16 million features of GPT-4. OpenAI has published the features found from GPT-4 and GPT-2 small and the corresponding training data at the following link.
SAE viewer
https://openaipublic.blob.core.windows.net/sparse-autoencoder/sae-viewer/index.html#/
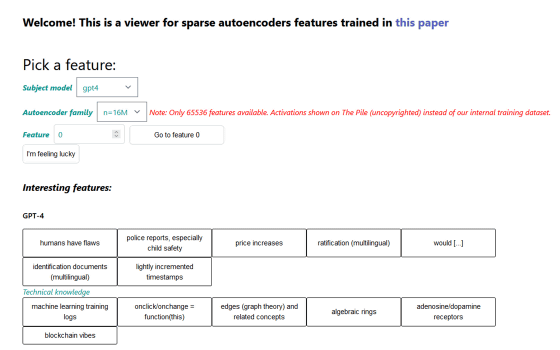
For example, the feature “humans have flaws” is associated with the following training data:
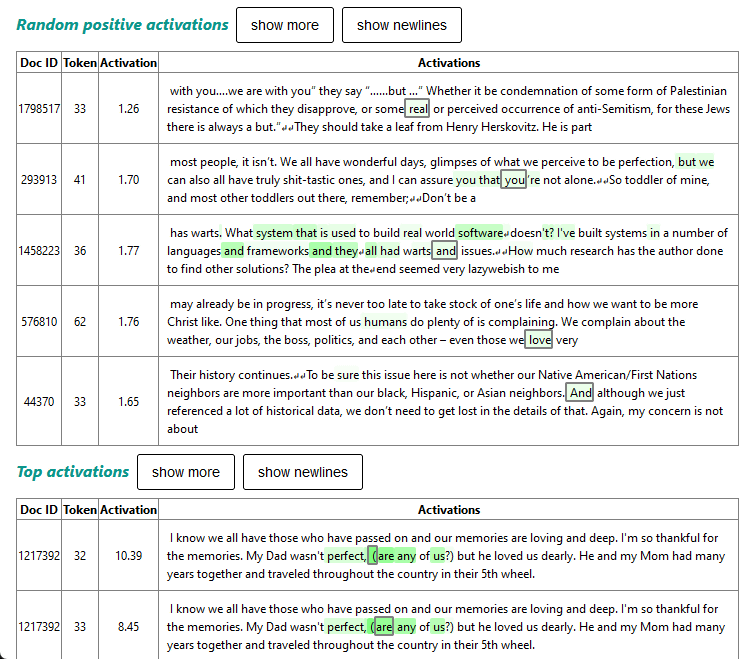
However, even the newly developed sparse autoencoder has not yet been able to analyze the entire operation of GPT-4. Also, feature detection is only one step in understanding the neural network, and much work is needed to understand it further. OpenAI has indicated that it will continue its research to solve the unsolved problems.
The source code for GPT-2 small's sparse autoencoder is available at the following link.
GitHub - openai/sparse_autoencoder
https://github.com/openai/sparse_autoencoder
Related Posts: