When a large-scale language model is pitted against a chess AI, most large-scale language models lose to pieces, but for some reason only 'gpt-3.5-turbo-instruct' wins overwhelmingly.

In recent years, with the rise of AI, various companies have released their own large-scale language models. When these large-scale language models were pitted against a standard chess AI, it was reported that while many of the large-scale language models were defeated, only '
Something weird is happening with LLMs and chess
https://dynomight.substack.com/p/chess
The science media Dynomight Internet Website sent the following prompt to a variety of large-scale language models:
[code]You are a chess grandmaster.
Please choose your next move.
Use standard algebraic notation, eg 'e4' or 'Rdf8' or 'R1a3'.
NEVER give a turn number.
NEVER explain your choice.
Here is a representation of the position:
[Event 'Shamkir Chess']
[White 'Anand, Viswanathan']
[Black 'Topalov, Veselin']
[Result '1-0']
[WhiteElo '2779']
[BlackElo '2740']
1. e4 e6 2. d3 c5 3. Nf3 Nc6 4. g3 Nf6 5.[/code]
The large-scale language model was then played against Stockfish , a standard chess AI, with the difficulty set to 'lowest.'
A total of 50 games were played, and a score of +1500 was assigned if the large-scale language model won, 0 if it was a draw, and -1500 if Stockfish won. In addition, a chess engine was used to score the position and moves of the large-scale language model in each game.
◆Llama-3.2-3B
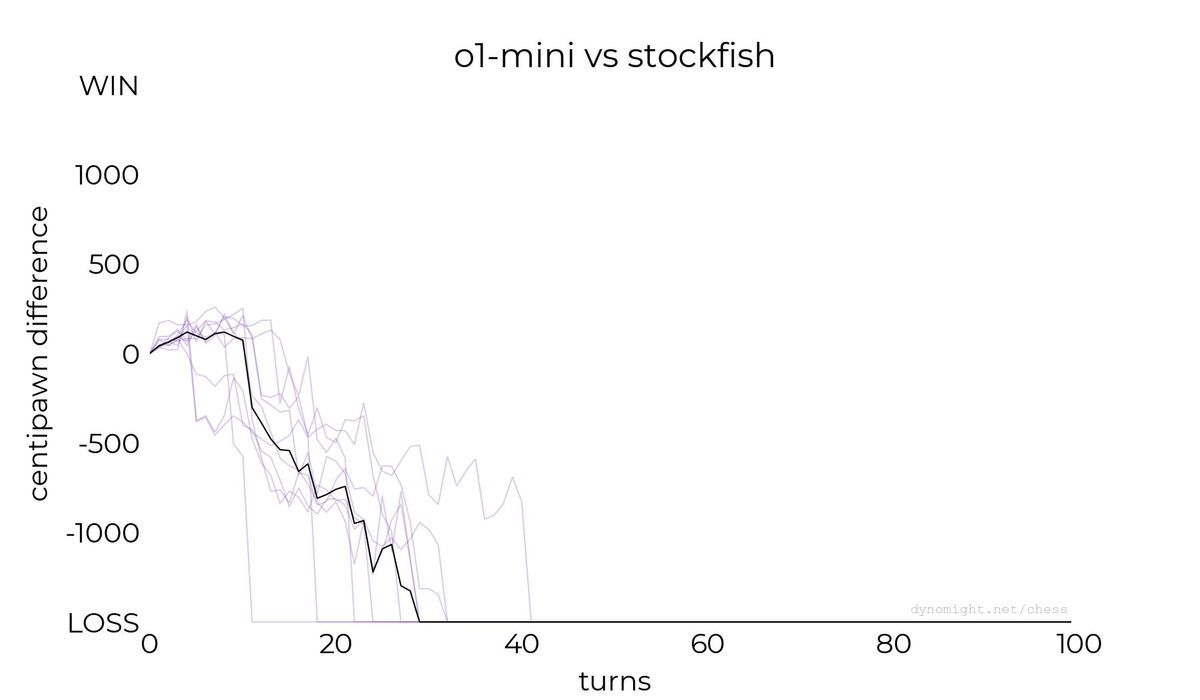
Below is a graph of the scores for a game between Llama-3.2-3B and Stockfish. The vertical axis is the evaluation value indicating the state of play, with anything above the center being a win (a victory) and anything below the center being a loss (a defeat). The horizontal axis is the number of turns, and the black line shows the median evaluation value for each turn.
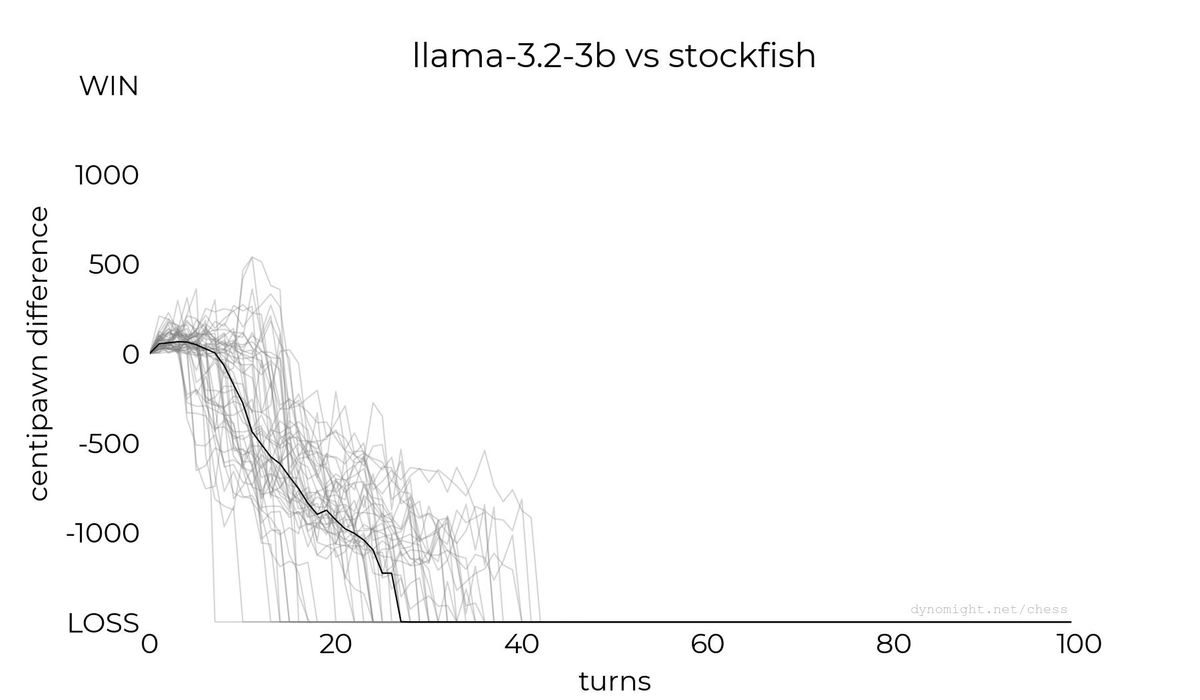
According to the Dynomight Internet Website, Llama-3.2-3B showed some standard moves, but in most cases it showed moves that resulted in pieces being captured. In the end, it was reported that it lost all of its matches.
◆llama-3.1-70b
Next, Dynomight Internet Website played llama-3.1-70b. The results are shown in the graph below.
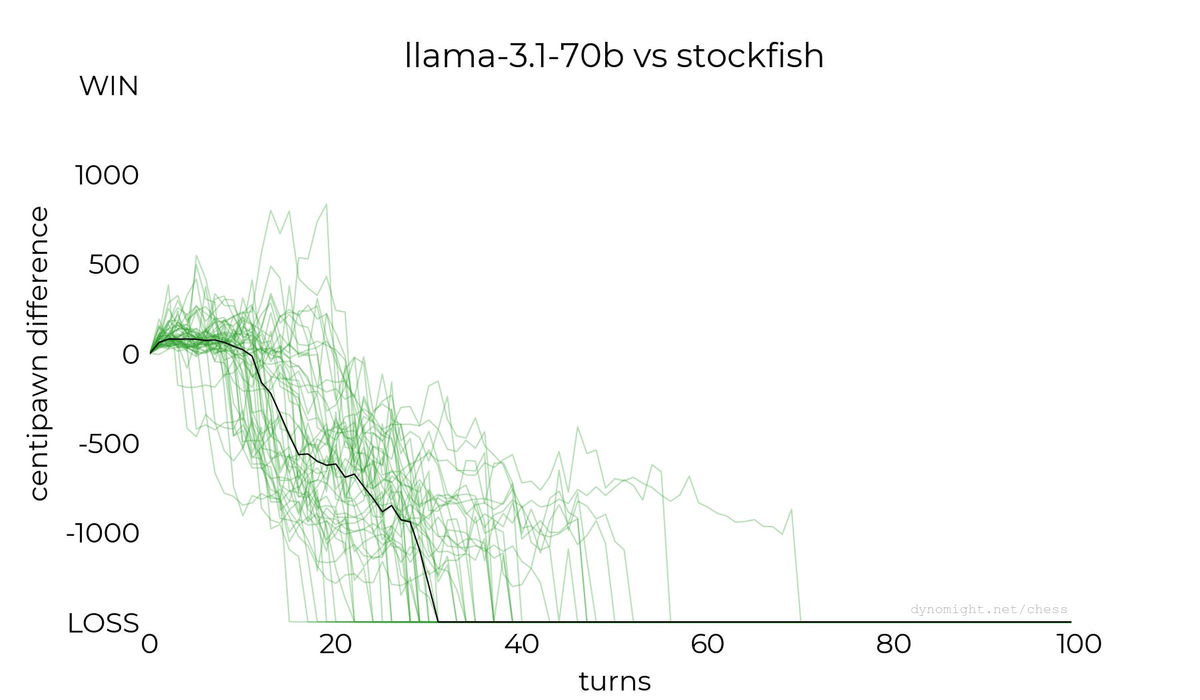
Although the score was higher than Llama-3.2-3B, it still did not win.
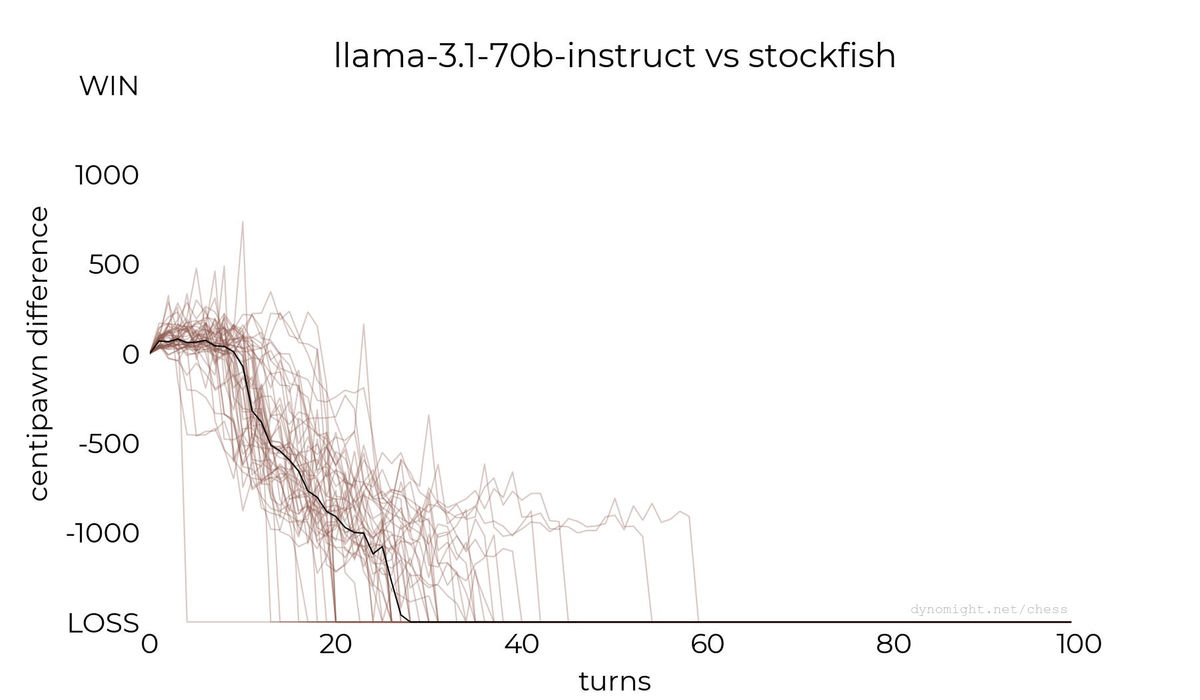
◆llama-3.1-70b-instruct
Below is a graph of a game played on llama-3.1-70b-instruct. There is no significant difference compared to the two previous large-scale language models.
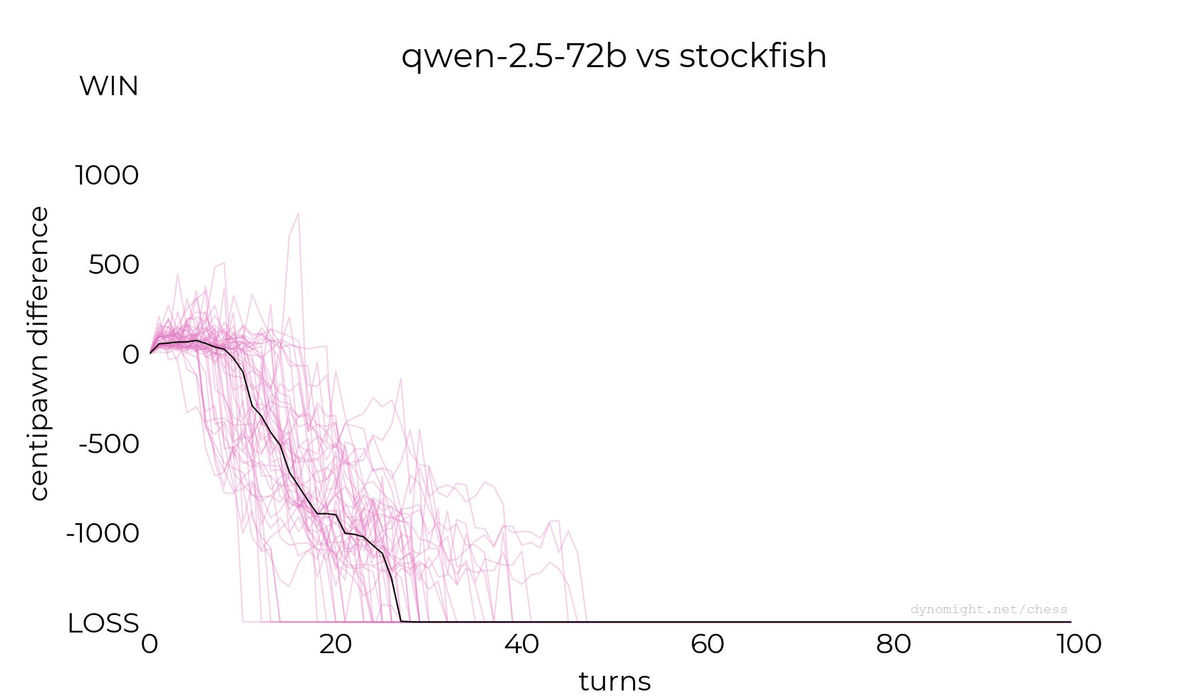
◆Qwen-2.5-72b
Suspecting that Llama's model and dataset may have problems, Dynomight Internet Website conducted an experiment with
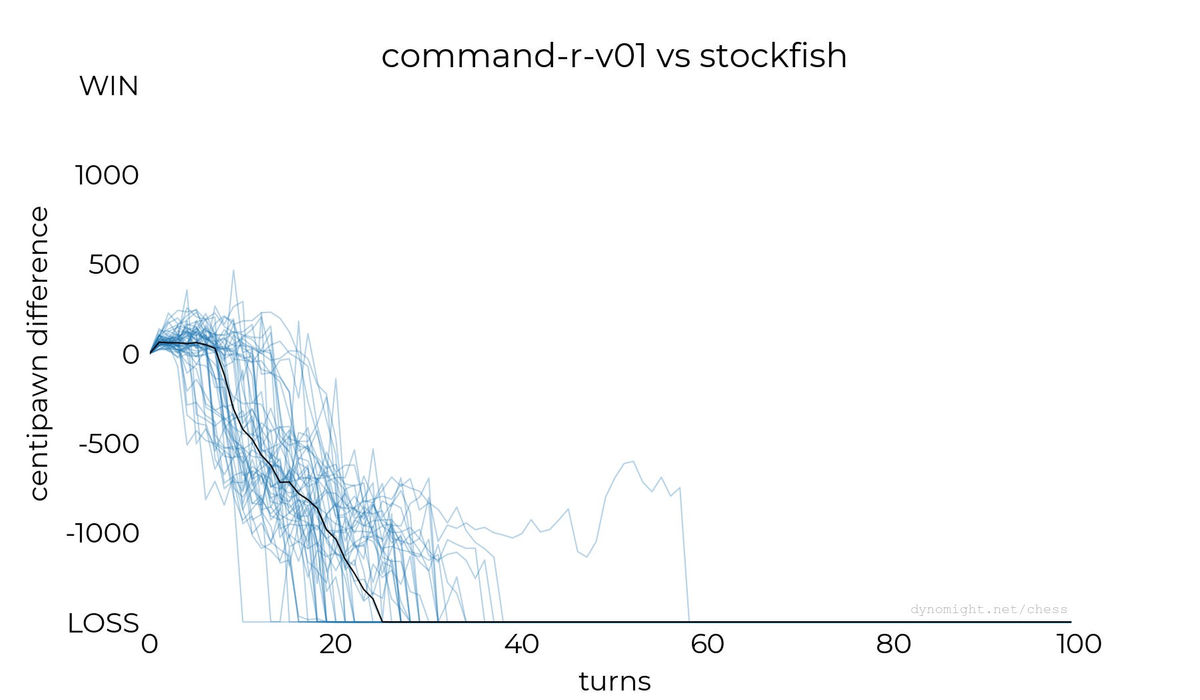
◆command-r-v01
Dynomight Internet Website, which speculates that Qwen may also have flaws, also played against c4ai-command-r-v01 . The results are as follows, and there is little difference from previous large-scale language models.
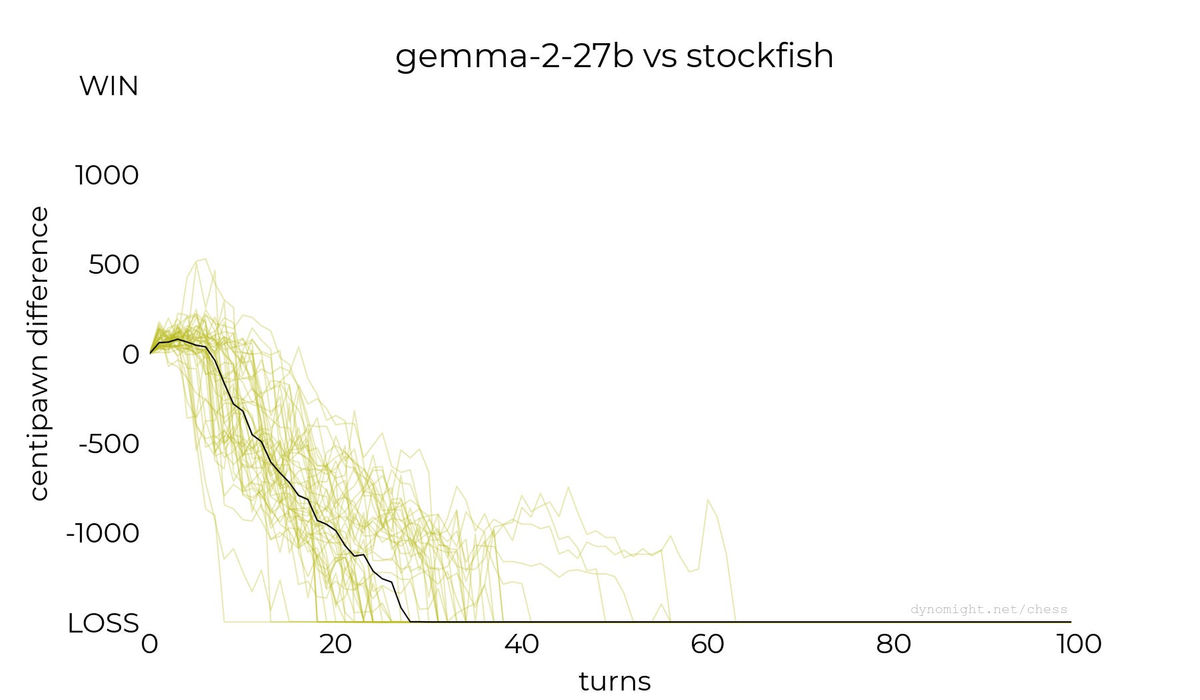
◆gemma-2-27b
Below is a graph showing the scores when playing against Google's large-scale language model
◆gpt-3.5-turbo-instruct
Next, Dynomight Internet Website played a game with gpt-3.5-turbo-instruct. The graph below shows the score of the game. It seems that they could not obtain a free API key and could only play 10 times, but gpt-3.5-turbo-instruct won all the games.
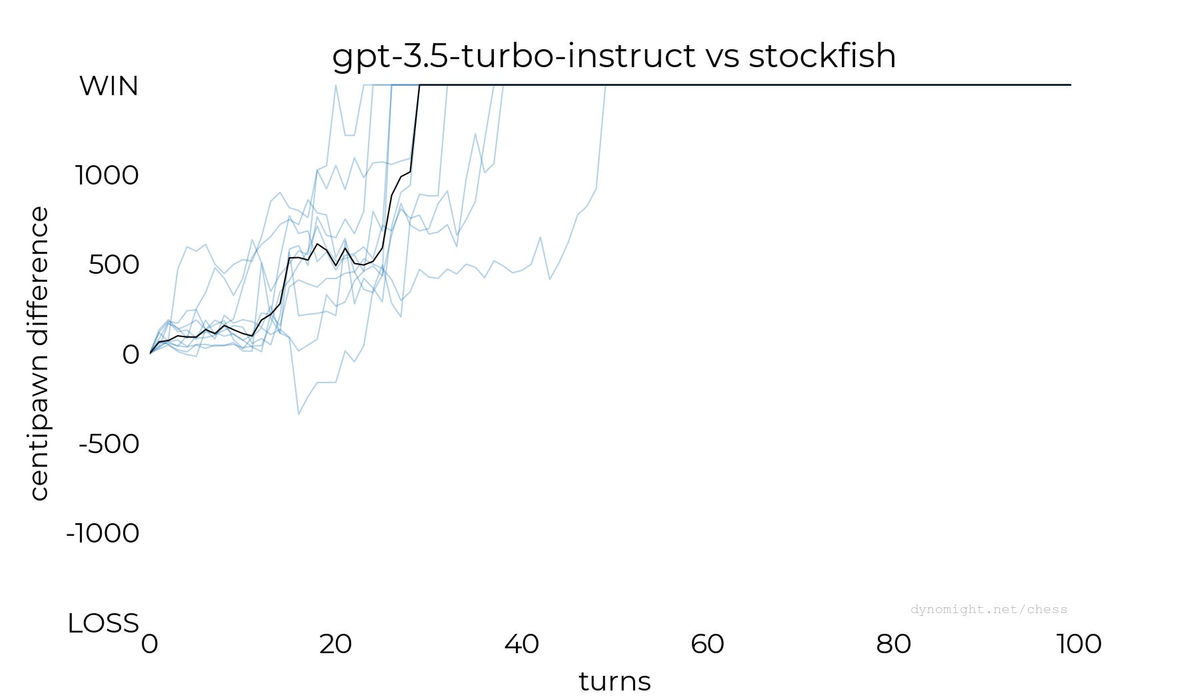
It has also been reported that players have been able to win even when using a high-level Stockfish.
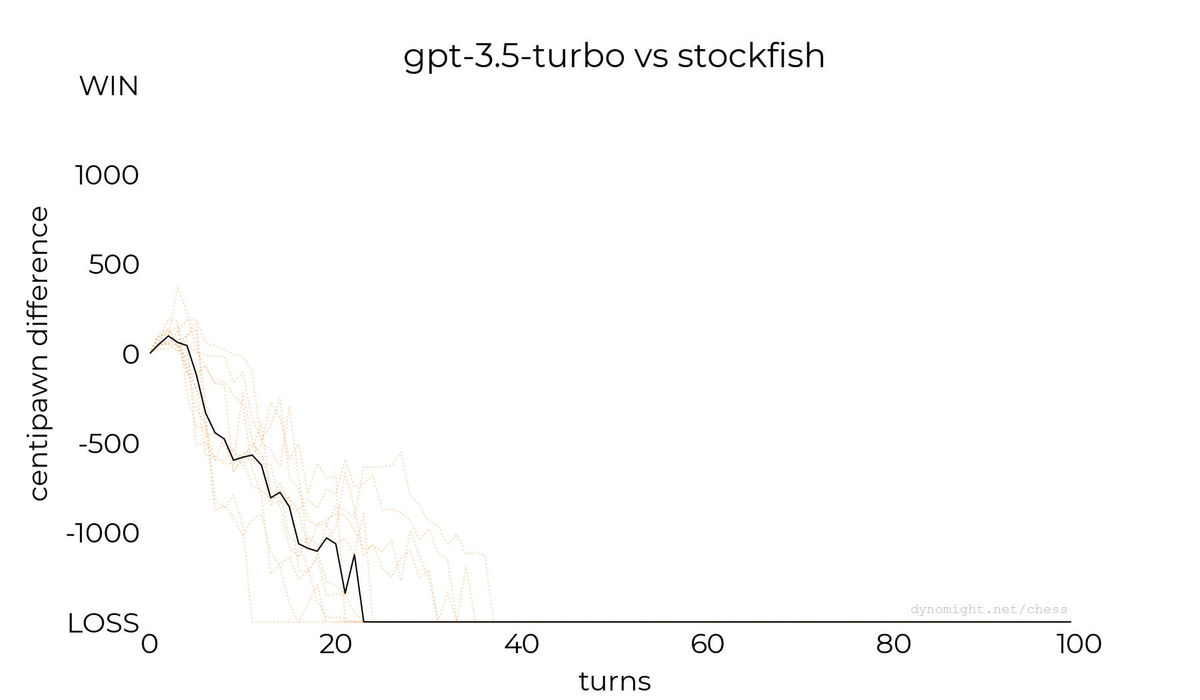
◆gpt-3.5-turbo
Below are the results of the game with gpt-3.5-turbo, which has better interactive performance than gpt-3.5-turbo-instruct. Unlike gpt-3.5-turbo-instruct, it was not able to win against Stockfish.
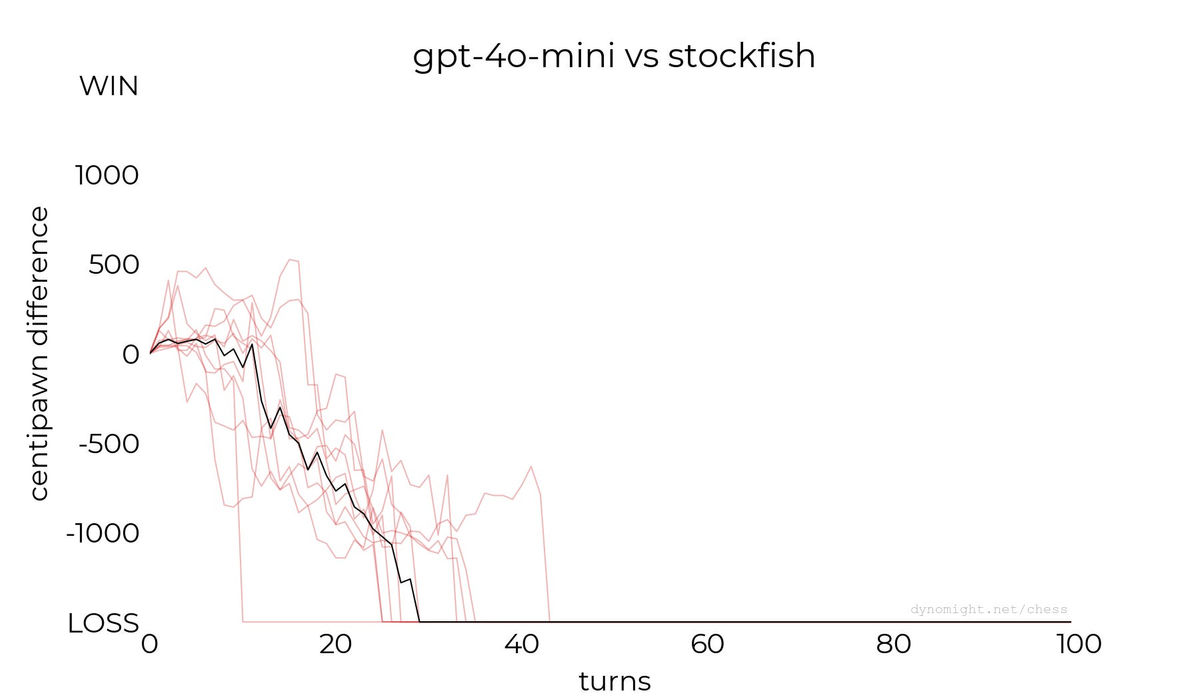
◆gpt-4o-mini
Below is a graph of a game between the multimodal AI gpt-4o-mini and Stockfish, released in July 2024. The Dynomight Internet Website gives this result a rating of 'Terrible.'
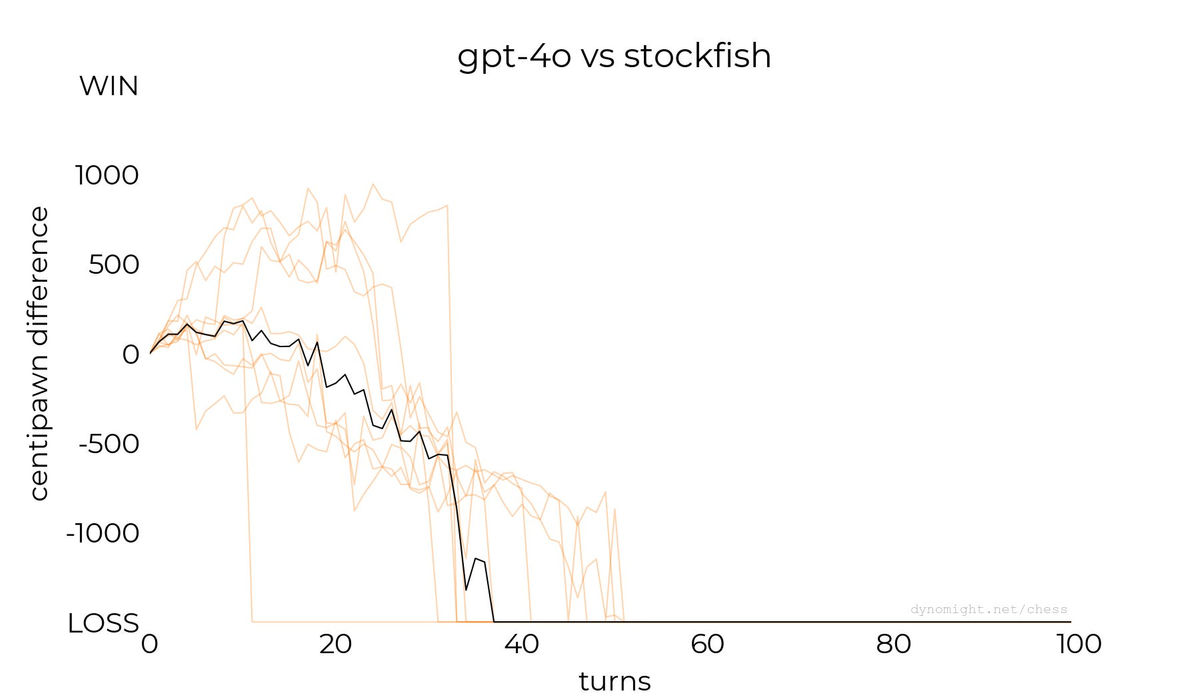
◆gpt-4o
Below are the results for the gpt
◆o1-mini
The results of the OpenAI AI model '
Below is a graph that combines the median values of the above 11 models into one. It shows that only gpt-3.5-turbo-instruct has a good performance.
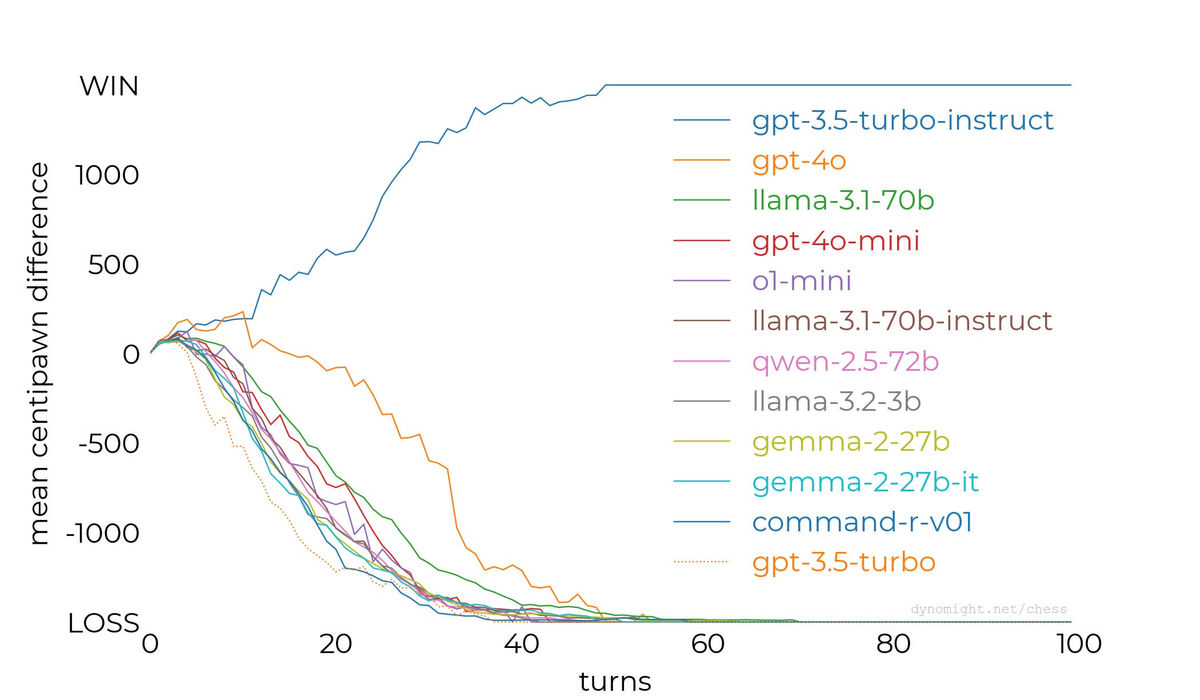
Regarding these results, the Dynomight Internet Website speculated that 'A language model of sufficient scale can certainly play chess, but extensive tuning makes it impossible to win at chess,' 'gpt-3.5-turbo-instruct was trained using many more chess games than other large-scale language models,' and ' Transformer models vary from one AI development company to another.'
Related Posts: