Googleの新たな自然言語処理モデル「ALBERT」はどのように進化したのか?

By halfpoint
Googleから発表された自然言語処理モデル「Bidirectional Encoder Representations from Transformers(BERT)」は、膨大な既存のテキストデータから文脈理解や感情分析を事前学習するため、自然言語処理モデルをゼロから学習させる必要がなく、あらかじめ言語の知識を備えた状態で使用できます。2019年9月に、BERTを軽量化し高速化を行った「ALBERT」がGoogleによって公開されました。
Google AI Blog: ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations
https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html
Googleは、International Conference on Learning Representations(ICLR)2020でBERTのアップグレードとなるALBERTを発表しました。Googleの研究者であるラドゥ・ソリカット氏は、ALBERTはStanford Question Answering DatasetとRACEベンチマークを含む12の自然言語処理タスクにおいて優れた性能を持っていると述べています。
BERTとALBERTは、単語ひとつに対して、前後の文脈に依存しない表現と、文脈に依存した表現の両方を学習します。たとえば「bank」という単語であれば、単語そのものの意味と、金融取引の文脈における「銀行」を意味する表現、および河川に関する文脈における「堤防」を意味する表現など、文脈によって異なる表現を分類することで学習精度を向上させています。
学習精度の向上は、モデル自体の容量増加につながります。ソリカット氏と同じくGoogleの研究者であるジェンジョン・ラン氏は「モデルの容量が増加するほどパフォーマンスは向上するが、事前学習に掛かる時間が長くなったり、モデル容量が大きくなることで予期せぬバグが発生し、モデル容量を増やせなくなったりする可能性が高くなる」と述べています。
ALBERTはパラメーター化された学習データに、モデル容量が適切に割り当てられるよう設計することで、パフォーマンスの最適化を行っています。文脈に依存しない単語のパラメーターは低次元、文脈理解のパラメーターにはBERTと同様の高次元の入力レベルを使用することで、ALBERTはBERTからのわずかな性能低下を犠牲に80%ものデータ容量削減に成功しています。

By f9photos
ソリカット氏によると、ALBERTにはもう1つの重要な設計が追加されています。BERT・XLNet・RoBERTaなどの自然言語処理モデルは、スタック構造の独立した複数のレイヤーに依存していますが、異なるレイヤーで同じ処理を実行することで冗長性を持たせています。ALBERTでは、異なるレイヤー間でパラメーターを共有することで処理の最適化を行っています。この設計を採用したことにより、言語処理の精度はわずかに低下しましたが、よりモデル容量を縮小し、処理の高速化が可能になりました。
2つの設計変更を実装することで、ALBERTはBERTと比較して89%のパラメーター低減と学習速度の向上を達成しています。パラメーターサイズの削減によりメモリサイズに余裕が生まれたことから、より多くの事前学習が可能になり、結果的にパフォーマンスの大幅な向上にもつながりました。
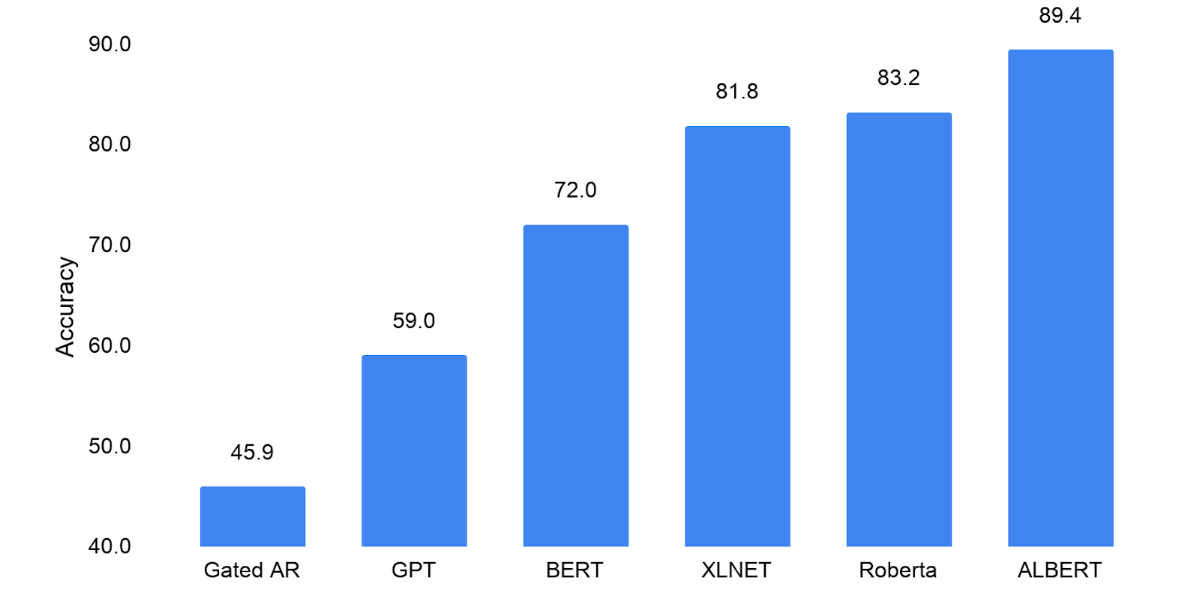
ソリカット氏らの研究チームは、ALBERTの言語理解能力を、RACE datasetを使用した読解テストで評価を行っています。各自然言語モデルの読解テストのスコアは以下の通りで、文脈に依存しない単語表現のみを事前学習したモデルであるGated ARは「45.9」、文脈に依存した言語学習を行ったBERTは「72.0」、BERT以降に開発されたXLNetとRoBERTaはそれぞれ「81.8」と「83.2」、そしてALBERTは「89.4」でした。なお、スコアが高いほどモデルが優れた答えを出したということになります。
ソリカット氏は「ALBERTが読解テストで高いスコアを出したことは、より説得力のある文脈表現を生み出す自然言語処理モデルの重要性を示しています。設計の改善に集中することにより、広範囲の自然言語処理タスクに関するモデル効率および性能の両方を、大きく改善することが可能です」と語っています。
・関連記事
Googleの自然言語処理モデル「BERT」はインターネット上から偏見を吸収してしまうという指摘 - GIGAZINE
Googleが自然言語処理の弱点「言い換え」を克服するデータセットを公開 - GIGAZINE
「難解な論文をわかりやすく要約してくれるAI」が開発される - GIGAZINE
自然言語処理などに利用されるAIモデルは言葉の「言い換え」に脆弱であると研究者らが指摘 - GIGAZINE
Facebookが90言語以上の機械翻訳を加速させるためのツールキット「LASER」を公開中 - GIGAZINE
・関連コンテンツ