A person who made a translation program from 0 by deep learning will explain the mechanism in diagrams rather than complicated formulas

As technology develops, it becomes possible to create a translation program using a neural network even if it is not an expert. However, it is difficult for people who have no knowledge to understand the mechanism. Writer Samuel Lynn - Evans creates a translation program from 0 while looking up information by himself, and explains the mechanism understood at that time without using mathematical expressions.
Found in translation: Building a language translator from scratch with deep learning
https://blog.floydhub.com/language-translator/
The language is very complex, and until now machine translation has required many experts. However, with the development of artificial intelligence (AI), machine translation can now be performed even if it is no longer an expert. This is because the neural network automatically learns the rules of the language which experts were dealing with so far.
Then, what does it become when a person who is not actually an expert hands out machine translation? As a result, writer Lynn - Evans constructed and completed a language translation program using AI from 0. Lynn-Evans has worked as a teacher of science and linguistics over the past decade, and started to learn about AI in Paris at the age of 42.
Lynn - Evans created English - French translation program. Lynn-Evans needs to first "learn" a large amount of data to create a machine translation program, but Lynn-Evans learns a database containing 2 million sentences over 3 days on a machine with 8 GB of GPU He said that he did. From a person familiar with Neural Machine Translation (NMT), this amount of learning is small. In the database, the parallel corpus of the minutes of the European Parliament between 1996 and 2011 was used. It contains more than 2 million sentences and over 50 million words.
Tested 3000 sentences translated by Lynn - Evans' translation program with the evaluation algorithm " BLEU " which measures translation accuracy, the score was 0.39. This is not bad figure, as the English-French translator score is 0.42.
According to Lynn - Evans, as a result of the test, it seems that some texts could be translated with higher accuracy than Google translation. However, since the neural network can only grasp the meaning of words included in machine learning data, it can not deal with words unknown to him. Therefore, even if translating Google Translate 100% correctly, Lynn - Evans' translation program said it showed confusion in the form of 'Repeating unknown words repeatedly'.
For example, when you write sentences with proper nouns & rare noun on parade that two Philistines from Ty Dupree and Rosie Macyntyre were in looting beautiful Ruffian, you could write sentences (top) from input Translation (lower row) translates properly, but Lynn - Evans' translation program (middle row) clearly finds that the sentence is missing.

Lynn-Evans says that the translation result was "incredibly good" as a whole, although there is a weak point in nouns. Actually, the code of the translation program created by Lynn-Evans can be seen from the following.
GitHub - SamLynnEvans / Transformer: Transformer seq 2 seq model, program that can build a language translator from parallel corpus
https://github.com/SamLynnEvans/Transformer
So how does the translation program work? On that point, Lynn - Evans explains in a form not using mathematical formulas.
First of all, Lynn - Evans thinks of using a sentence generation model "Seq 2 Seq (sequence to sequence)" using a recursive neural network (RNN). Seq 2 Seq encodes (encrypts) the sequence entered by one network and then decodes (decrypts) another network to output translation results.
In the following figure, the encoded sentence is described as "State", but this State state is like its own sentence itself. Translation of English to French is not directly translated, but it is translated once into machine language .

RNN is used to construct an encoder / decoder when processing input whose length changes like sentences. Below is a visualization of the process of encode by RNN called Vanilla RNN. As you go through the first word, the second word, and the process you will see that "State" has been updated.
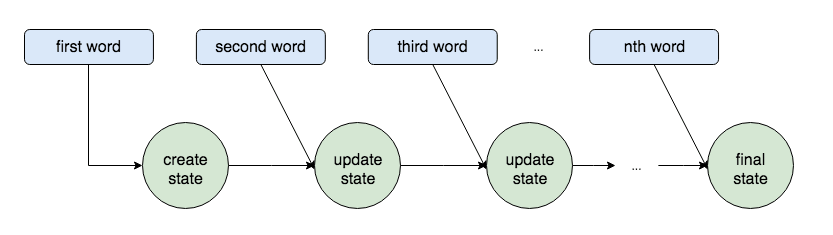
It is said that this work makes data input variable, and enables processing in the correct order. There is a convolution neural network (CNN) besides RNN in the neural network, CNN does not have the concept of time series, the fact that it is "correct order" becomes the key "translation of sentences" includes RNN It is suitable. However, RNN has a problem that it becomes impossible to remember the beginning of the sentence when the sentence becomes long, and models to "LSTM (Long short-term memory)" and "GRU (Gated Recurrent Unit)" are created It was.
At this time, each process of the encoder not only produces the final "State", but also creates "output" for each of the processing of the first word and the second word. For many years, researchers have not noticed that these "outputs" are passed to the decoder to boost the translation result.
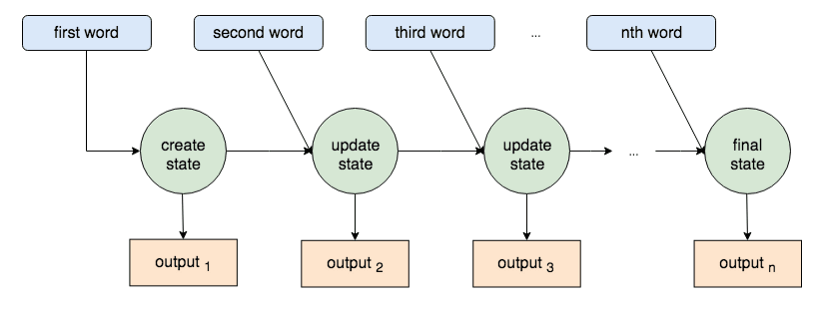
"Attention model" using these outputs was announced by Dzmitry Bahdanau and Minh-Thang Luong in 2015 - 2016.
While Lynn - Evans was investigating the LSTM model and attention model, I heard that "RNN is considerably slow". Since RNN uses iterative loops to process the data, it works well for small experiments, but it takes a month if you have one 8 GB GPU to do large machine learning.
Lynn - Evans discovered that "there is no such time or money" was a neural machine translation " Transformer " using only Attention without using RNN or CNN.
Google's "Transformer" to achieve higher quality translations to a level beyond RNN and CNN - GIGAZINE

Transformer is a model announced by Ashish Vaswani of Google Brain and others who thought "It is" output "generated from each input word rather than" State "which is important. The Transformer model does not perform an iterative loop and uses an optimized linear algebra library. RNN has been mentioned as a problem with slow speed, but Transformer is now able to obtain quicker and more accurate results.
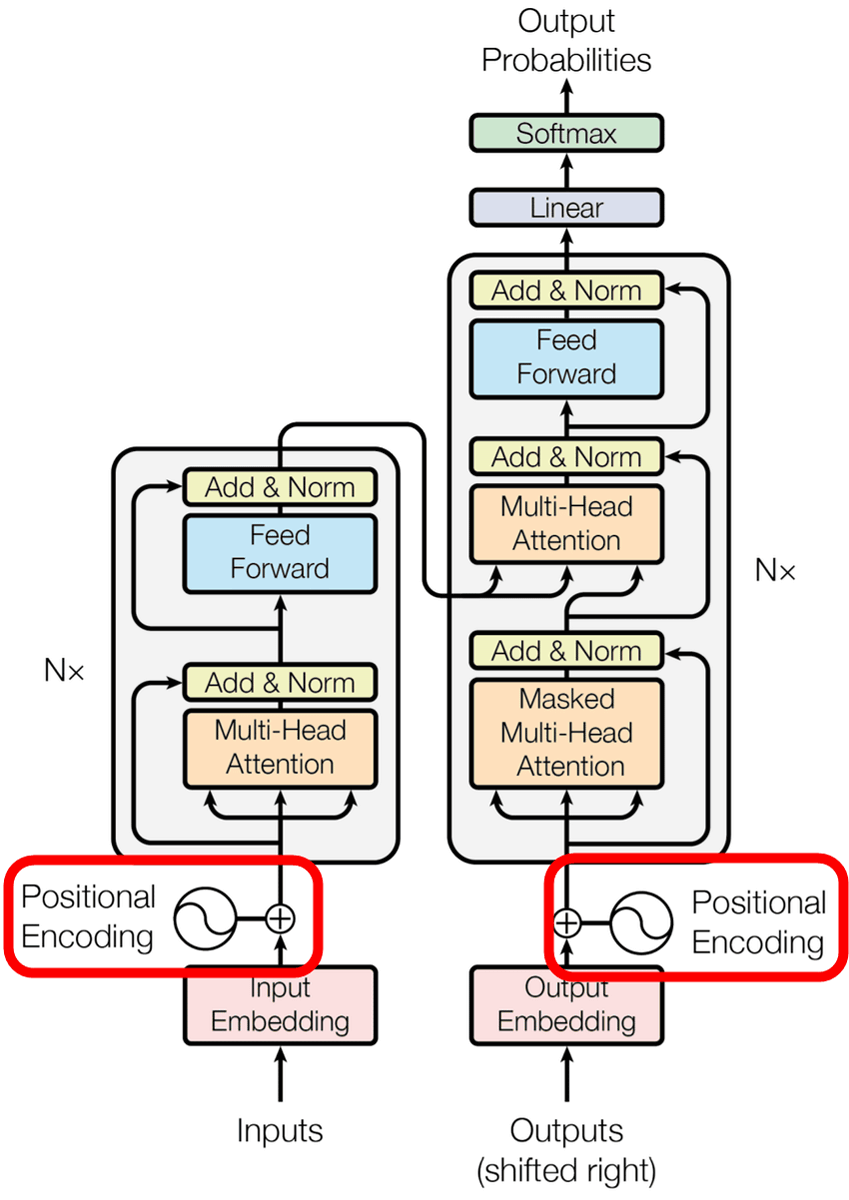
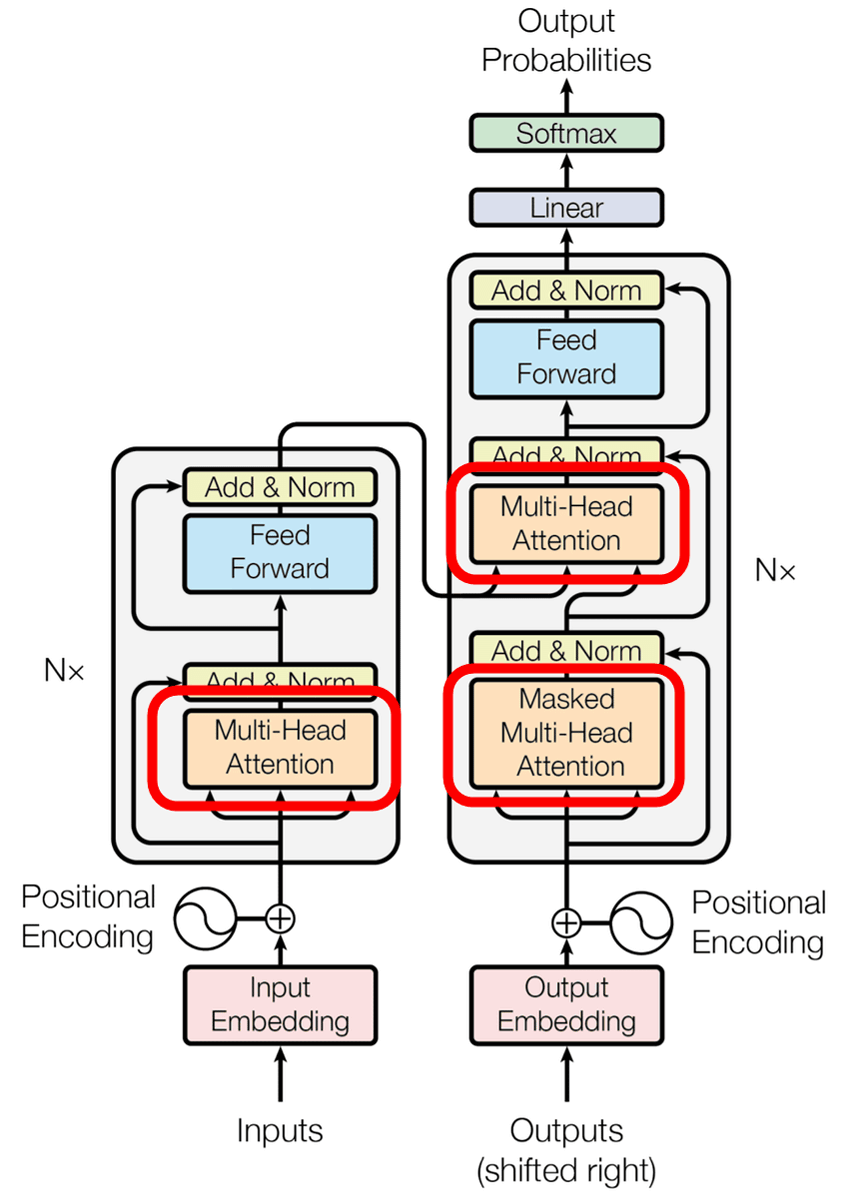
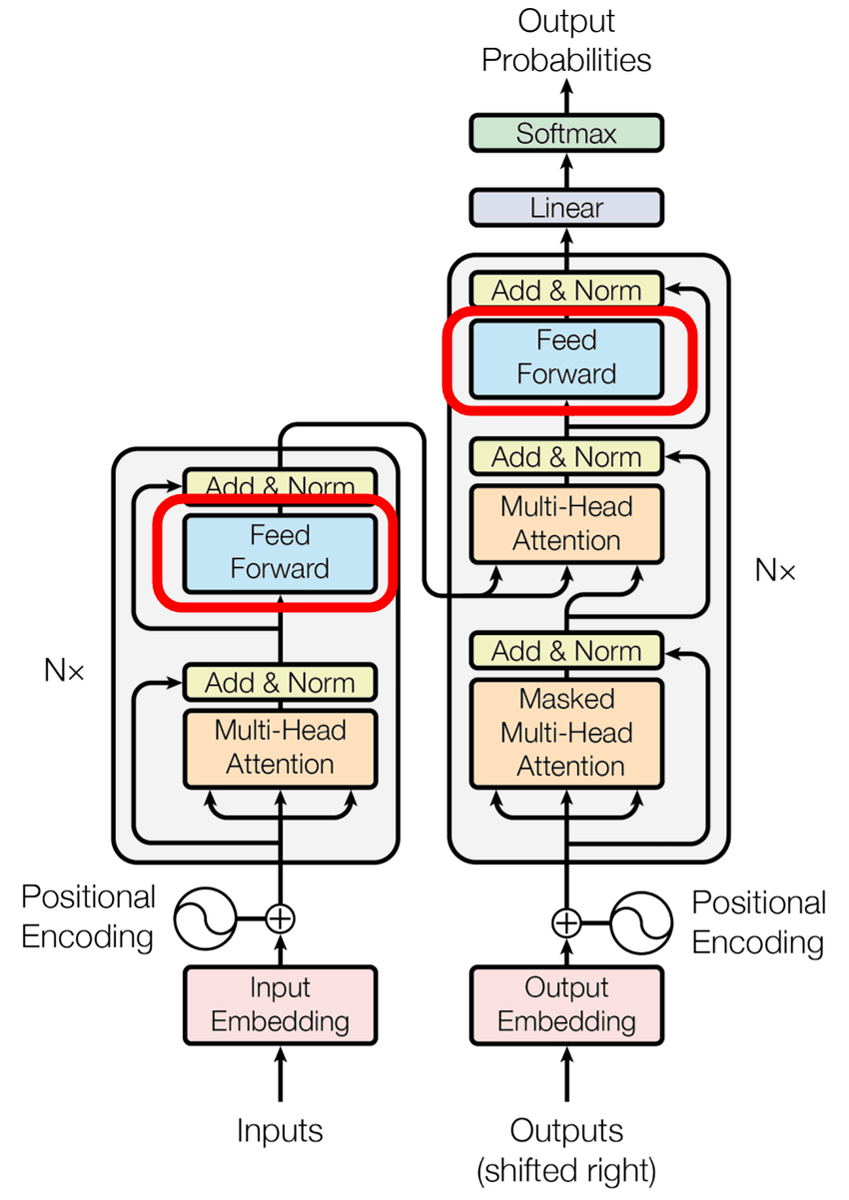
The following is an overview of the Transformer model. The left is the encoder and the right is the decoder. The Transformer model is characterized in that the encoder outputs each word, and at the decoder the "prediction" of the words coming from each output is done.
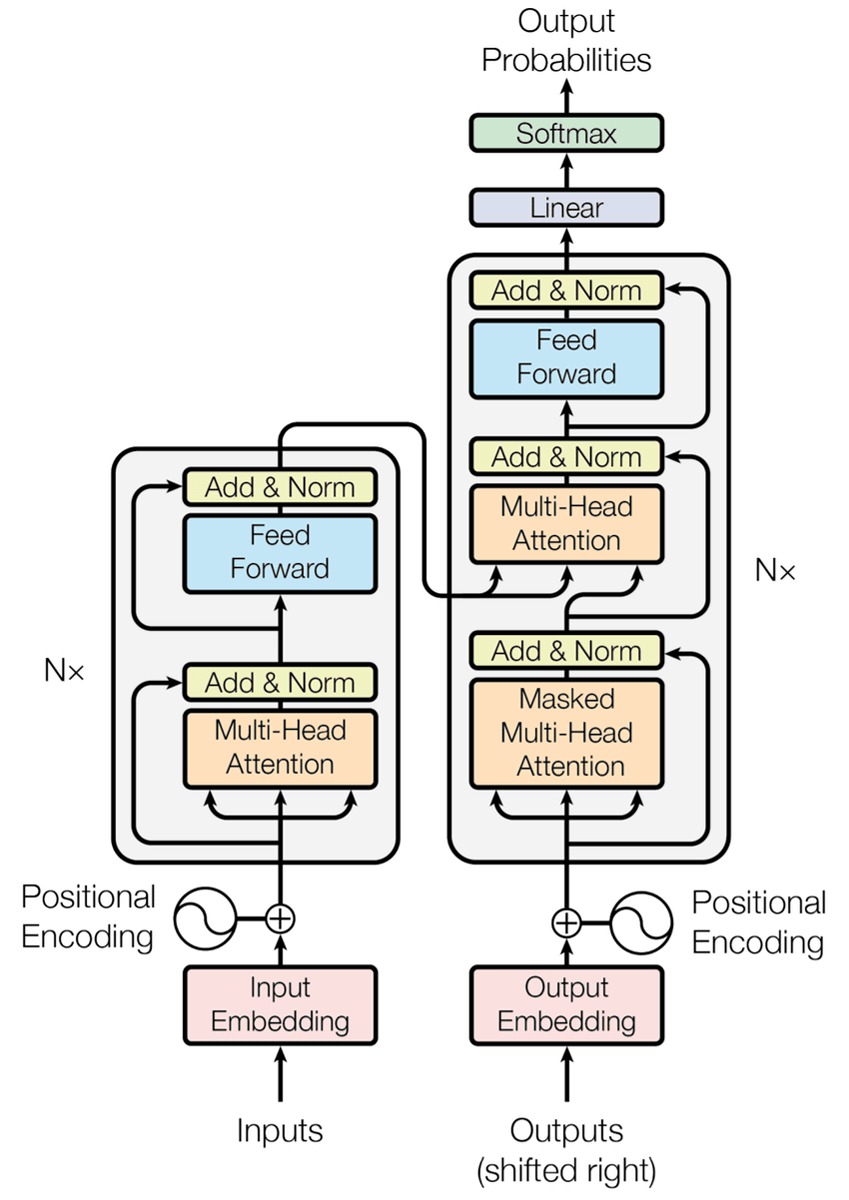
The Transformer process can be broadly divided into the following four.
1: Embedding
2: position encoding
3: Attention layer
4: Feedforard network
1: Embedding
The key to neural language programming (NLP) is "embedding". Originally in NLP, there was one-hot encoding to replace the word with 0 and 1.

Embedding is here in the figure.
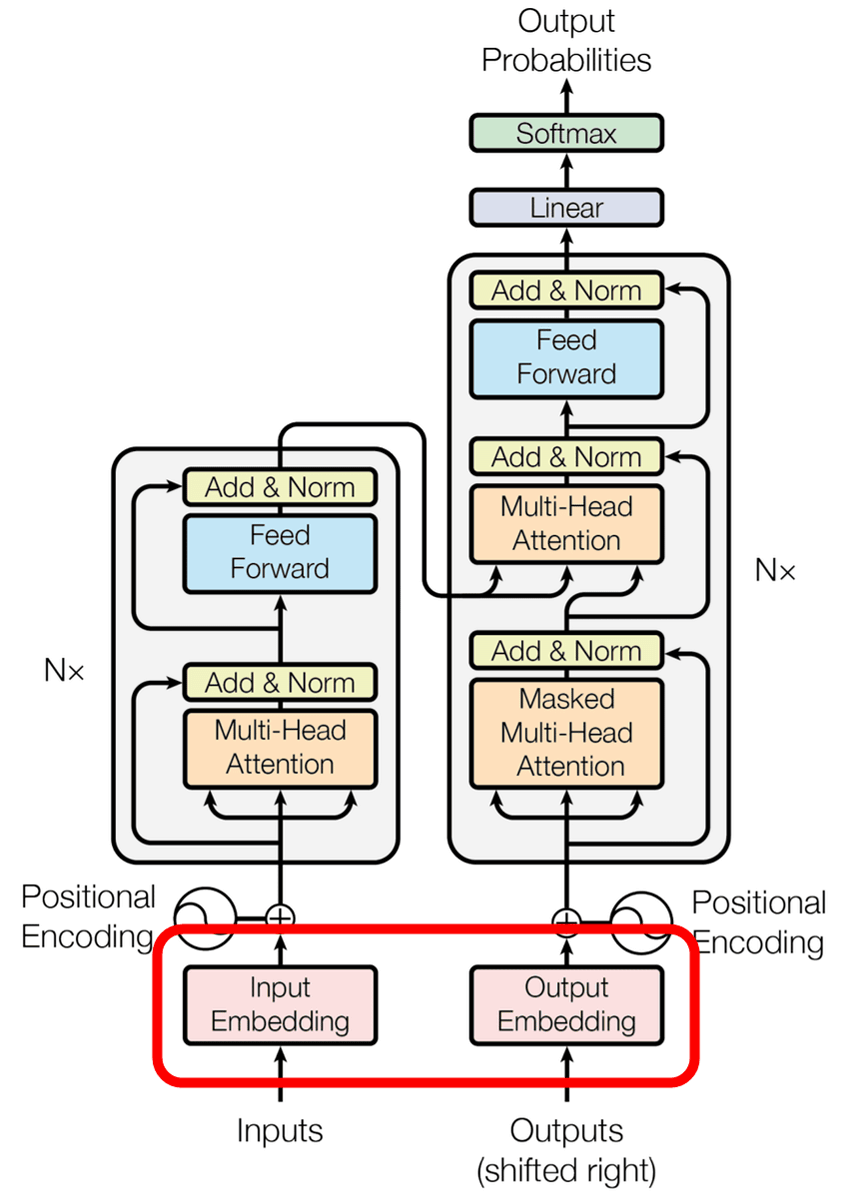
However, "one-hot encoding" is now "embedding" by making vectors huge, inefficient, and reducing the amount of information of things with multiple meanings of word context. Embedding is the storage of the characteristics of each word inside a vector of several hundred dimensions, giving the model an adjustable value.

2: Position Encoding <br> I could digitize the meaning of a word by embedding, but not only the meaning of words but also the phrase "where a word is in a sentence" It is important. What we are doing is the algorithm of position encoding. By adding a specific value to the value of embedding by position encoding, words are arranged in a specific order in sentences.
Location encoding is here.
3: Attention layer - The position-encoded embedded value will then pass through the Attention layer. The general Attention layer is as follows. There are three inputs query, key, and value, the product of the matrix of query and key is evaluated by attention score, and the product of that value and value is the attention output.
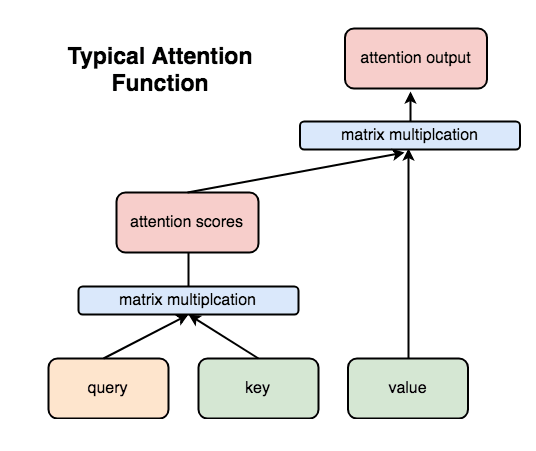
From the product of these series of matrices, the model will be able to judge "which word's importance is high" when predicting the next word.
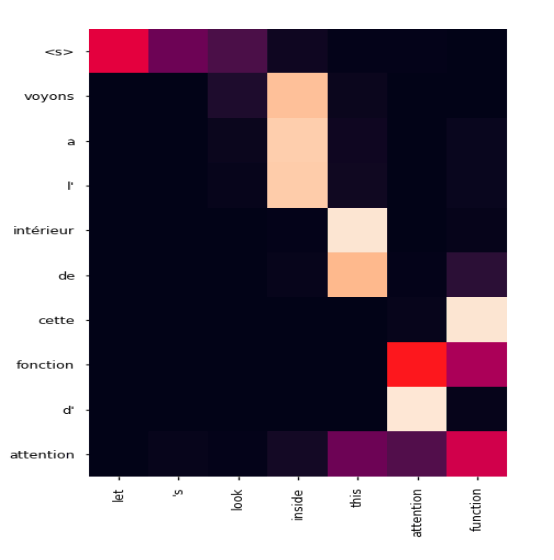
For example, when translating the word "let's look inside the attention function" into French, the following shows the "next word" predicted by the translation program. The vertical axis is French, the horizontal axis is English, and when the token of the first word of French [S] appears, "let", "s" "look" are raised as possible words. Since Let's corresponds to French "voyons", you can see that the neural network can predict the next word of the translation result just by entering [S].
4: Feedforard network - The feedforard network is simply structured to pass inputs in the order of all coupling, ReLU, and all coupling.
According to Lynn - Evans, when I learned on my PC with 8 GB of GPU for 3 days, it finally converged with the loss function of 1.3. As a reflection point is to increase the "deep learning is a field that changes rapidly, spend more time should be was to study," "data set of the European Parliament would lack the day-to-day conversation," "of the translation result precision beam You should use search . "
Related Posts:






in Software, Posted by darkhorse_log