What is the mechanism by which the machine learning model 'Transformer', which is also used for ChatGPT, generates natural sentences?

The large-scale language model, which is the basis of chat AI that enables natural conversation such as ChatGPT, uses the machine learning architecture ``
What Are Transformer Models and How Do They Work?
https://txt.cohere.com/what-are-transformer-models/
Simply put, Transformer is a technology that generates continuations according to the context of the text. 'Technology for generating the continuation of sentences' has been researched for a long time, and mobile phones are equipped with predictive input functions. Candidates that you ignore are often elected. As an example, to check the predictive input performance of a mobile phone, manually enter 'this' and then tap only the beginning of the predictive input candidate.
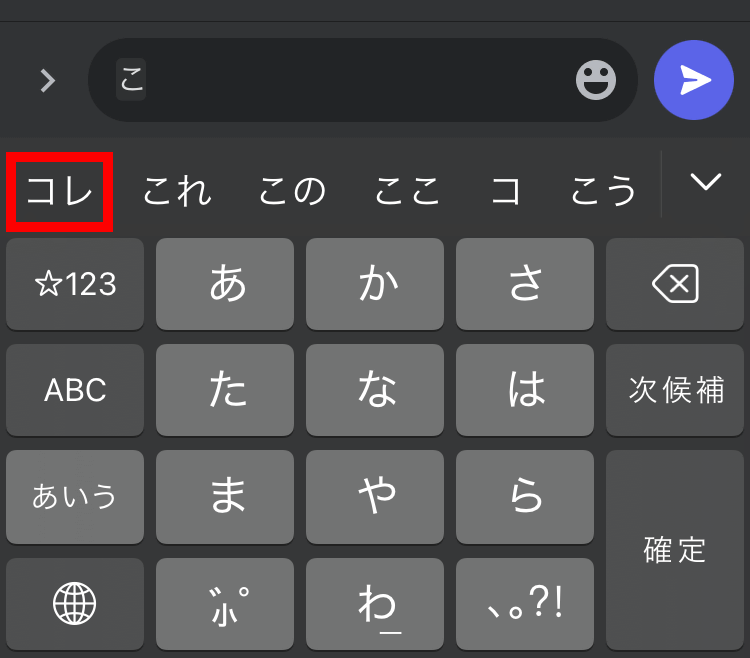
The completed sentence looks like this. I ended up with a sentence that doesn't make sense.
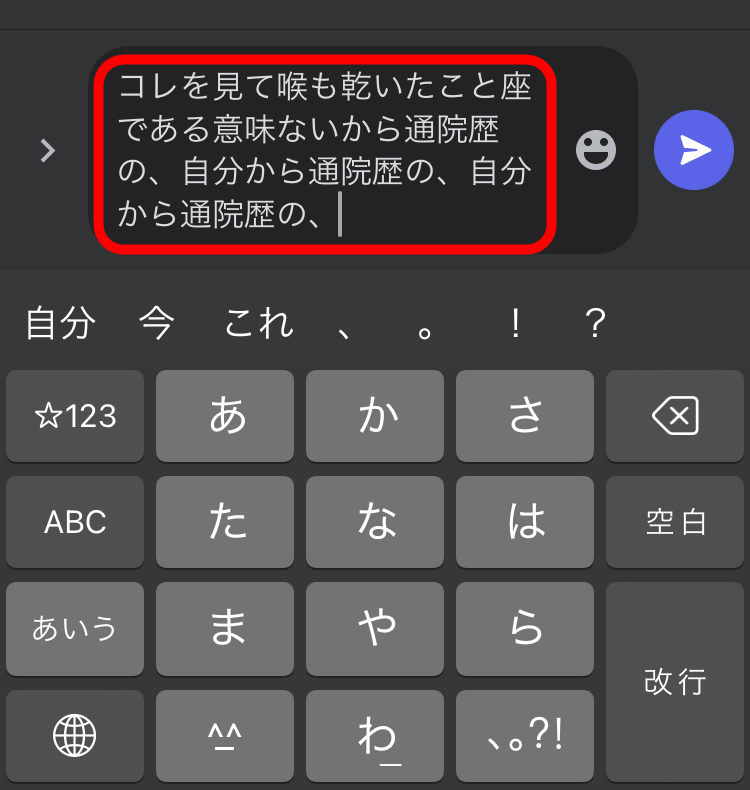
Transformer, on the other hand, can generate a continuation of the sentence while preserving the context. For example, if you enter the sentence 'Write a story.', expect that 'Once' will follow, and if you enter 'Write a story. Once', expect that 'upon' will follow, enter 'Write a story. Once upon' Then, it is possible to generate natural sentences that do not collapse, such as predicting that 'a' will continue.

Transformers are roughly divided into five stages of operations such as 'Tokenization', 'Embedding', 'Positional encoding', 'Transformer block', and 'Softmax'. Recognizing & generating. The details of each operation are as follows.
◆ Tokenization
Transformer divides sentences into units called 'tokens' and then processes them. For example, the sentence ``Write a story.'' will be chopped into ``Write'' ``a'' ``story'' ``.''.
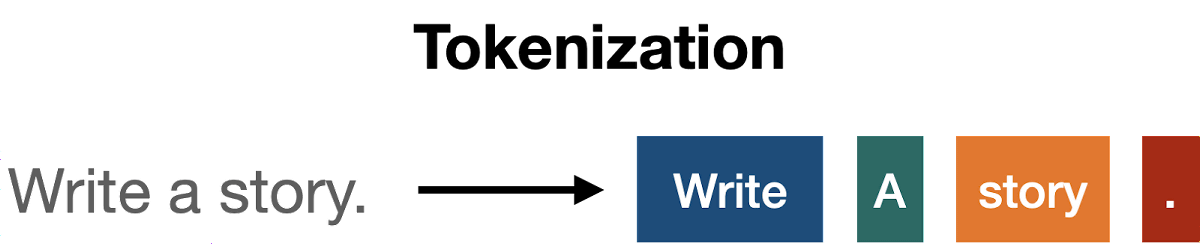
In English, one word is often one token, but the way tokens are divided differs depending on the type of word and language. You can understand how Japanese sentences are tokenized by reading the following article.
'Tokenizer' that you can see at a glance how chat AI such as ChatGPT recognizes sentences - GIGAZINE

◆ Embedded
Once tokenization is complete, 'padding' takes place, converting each token to a number. Embedding is done by checking the token against a 'correspondence list (vector) of tokens and numbers'.
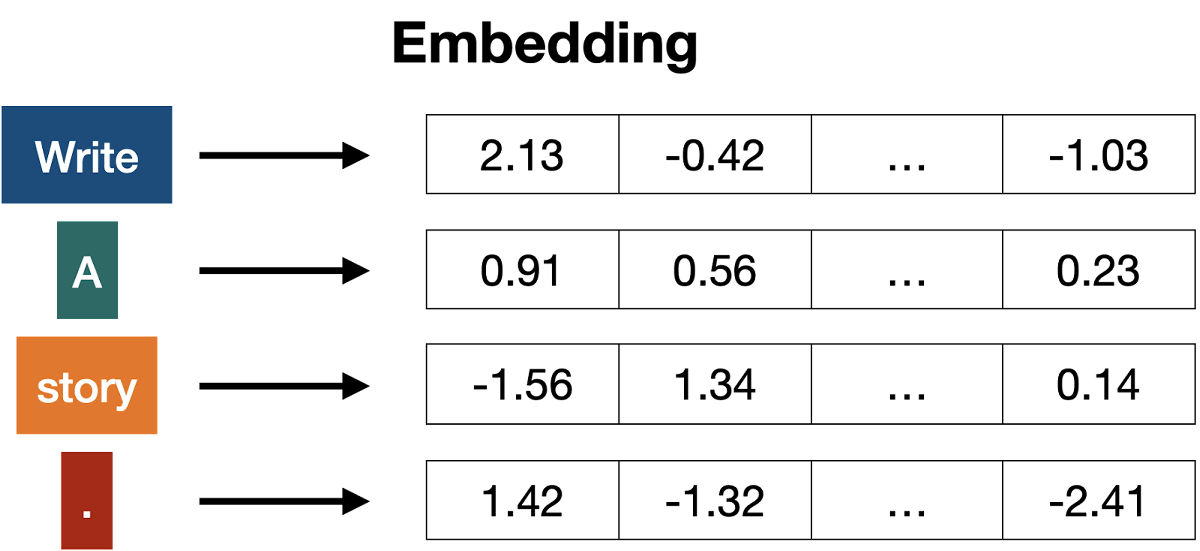
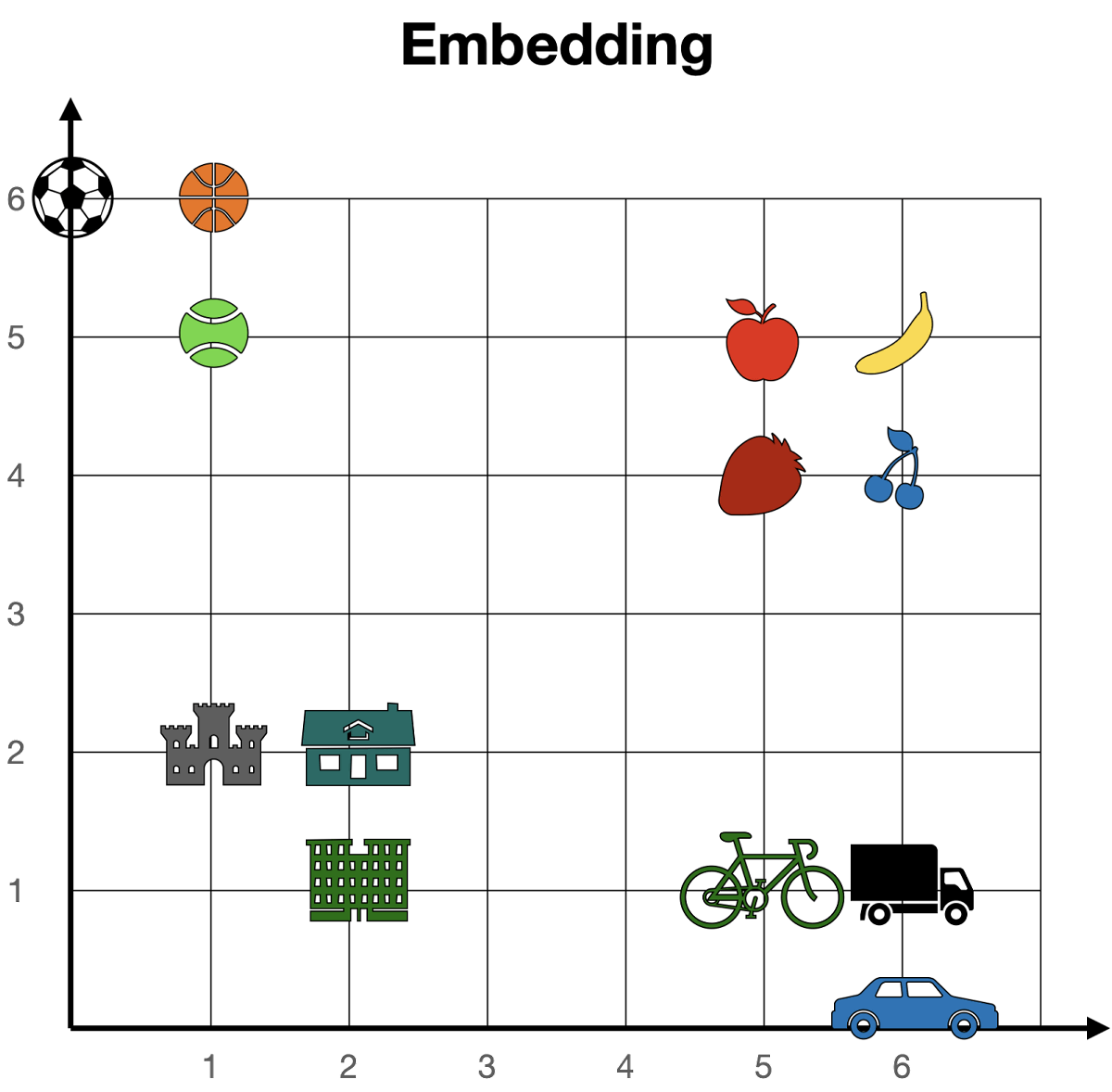
There are originally many types of vectors, but if we assume that there are two types of vectors, the state after token embedding is as follows. When you check the coordinates of each token, the coordinates of tokens with similar meanings such as 'apple (5,5)', 'banana (6,5)', 'strawberry (5,4)', and 'cherry (6,4)' are close. It can be seen that it is located in By digitizing the tokens in this way, embedding makes it possible to tell whether each token is similar or not.
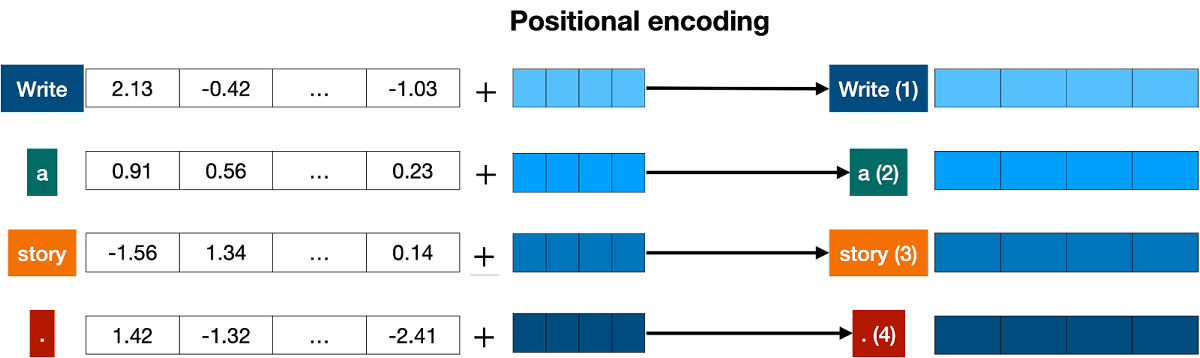
◆Positional encoding
After digitizing each token, we now need to convert the entire sentence into a single vector. To make the whole sentence into one vector, it is OK to derive the sum of the coordinates of each token. For example, if the coordinates of the tokens included in the sentence are '2,3', '2,4' and '1,5', the coordinates of the entire sentence are '2+2+1,3+4+5' = '5,12'.
However, in the case of the method of simply summing the coordinates, ``I'm not sad, I'm happy'' and ``I'm not happy, I'm sad'', ``sentences in which the same words are arranged in different orders'' will exist in the To solve this problem of identical coordinates, Transformer adds a position token to each token to indicate its ordering. For example, the sentence 'Write a story.' is divided into 'Write' 'a' 'story' '.' '.(4)'.
◆ Transformer block
When the token embedding and position encoding are completed, the process of 'generating the continuation according to the context' is executed. This processing is executed by passing through a number of processing systems called 'Transformer blocks'.
An important part of the Transformer block is a process called 'Attention' that weights the tokens so that they can take context into account. For example, the word ``bank'' has two meanings, ``bank'' and ``bank,'' and it is difficult to determine which one is meant even if only the word ``bank'' is shown. However, you can understand the meaning of 'bank' by words that are set with 'bank', such as 'The bank of the river' and 'Money in the bank' . Therefore, in Transformer, by placing 'bank' meaning 'bank' at coordinates near 'river' and 'bank' meaning 'bank' at coordinates near 'Money' It allows you to connect words without forcing them.

After performing the weighting process according to the context as described above, the Transformer block derives multiple appropriate words as a continuation of the sentence and assigns a score to each word.
◆Soft Max
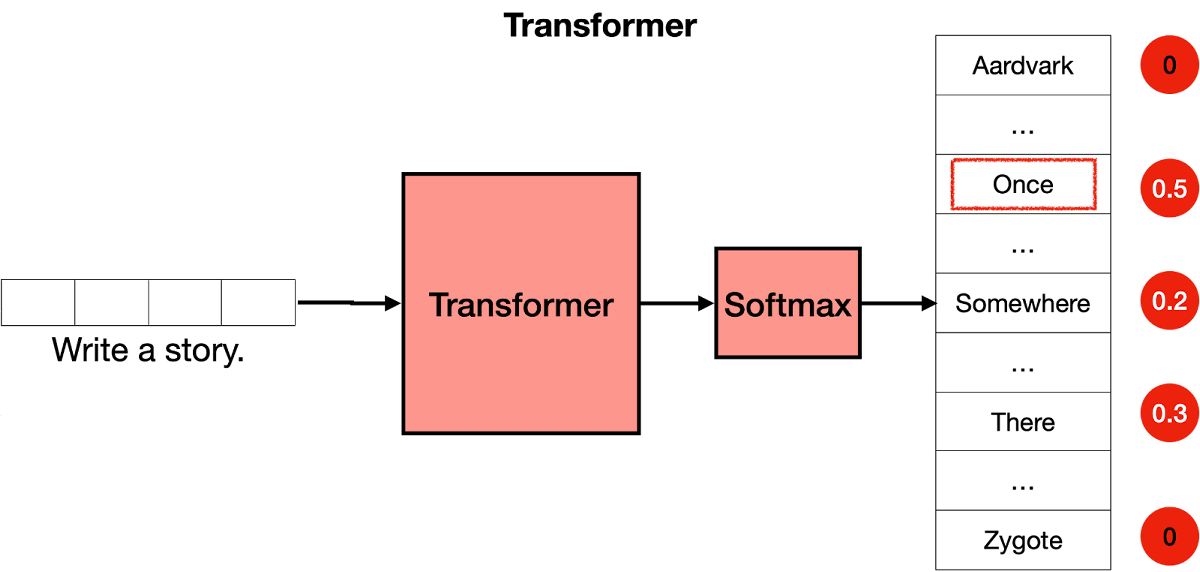
After the Transformer block derives word candidates that are suitable sentence continuations, it performs a softmax process that converts each candidate's score into a probability. The word with the highest probability is then output as the continuation of the sentence. In the example below, as a result of entering the sentence 'Write a story.', words such as 'Once', 'Somewhere' and 'There' are derived as candidates, and 'Once' with the highest probability among the candidates is the continuation of the sentence is output as Then, when 'Once' is output, 'Write a story. Once' is newly input, and the continuation of the sentence is generated one after another.
Related Posts:






in Software, Posted by log1o_hf