What is the new AI 'Q * (Q Star)' developed by OpenAI supposed to be?

OpenAI's new AI development project `
How to think about the OpenAI Q* rumors - by Timothy B Lee
https://www.understandingai.org/p/how-to-think-about-the-openai-q-rumors
Mr. Lee cites the following problem as an example.
'John gave Susan 5 apples and then 6 more. Susan then ate 3 apples and gave 3 to Charlie. She gave the remaining apples to Bob and he gave 1. Bob gave Charlie half of the apple. John gave Charlie seven of the apples, and Charlie gave two-thirds of the apple to Susan. Then Susan gave Charlie four of the apples. I gave you an apple. How many apples does Charlie have now?”

In the end, the correct answer is that Charlie has 8 apples. The calculation itself is not difficult at all, but you need to follow the numbers step by step according to the content of the problem statement.
To a large language model, numbers like 5 and 6 are just tokens. A large-scale language model will learn this token empirically if it calculates 5 + 6 = 11 because it appears thousands of times in the training data. However, examples of long calculations such as [3+[{(5+6)-3}-1]/2+7]/3+4=8 are not included in the training data. Therefore, if you try to perform these calculations all at once, there is a very high possibility that the large-scale language model will give the wrong answer.
In a paper published in January 2022 (PDF file) , Google researchers argued that 'large-scale language models produce better results when they are encouraged to reason one step at a time.' . Using chain-of-thought reasoning, large-scale language models divide complex computational problems into several steps, and derive the correct answer for each step from training data.
A few months before Google published this paper, OpenAI published a paper on GSM8K , a dataset of 8,500 elementary school level math word problems, and a new technique for solving them. OpenAI has a large language model generate 100 answers and evaluates each answer using a second model called a 'validation model.' The large-scale language model outputs the one that was rated highest by the verifier out of the 100 answers.

You might think that training this validation model would be as difficult as training a large-scale language model, but according to OpenAI, by combining a small-scale generative model with a small-scale validation model, it can be It is said that results comparable to a larger generative model with twice as many parameters can be obtained.
Furthermore, in a paper published in May 2023, it was revealed that OpenAI is tackling even more difficult math problems beyond elementary school math problems. Instead of the validation model scoring the answer, we use a method in which the validation model evaluates each step of the answer.
For example, in the image below, a large-scale language model is used to solve the problem, 'The denominator of a certain fraction is 7 times less than the numerator. If the fraction is equivalent to 2/5, how many times is the numerator of the fraction?' Where it was. “Put the numerator as x” “The denominator is 3x-7” “We can formulate the formula x/(3x-7)=2/5” “5x=2(3x-7)” “5x=6x- 14', and each one is correct, so a green pictogram is displayed as proof that it has been evaluated as OK by the verification model. The last part of the conclusion, 'Therefore, x = 7' is incorrect, so the validation model gives it an NG rating, and a red pictogram is displayed.
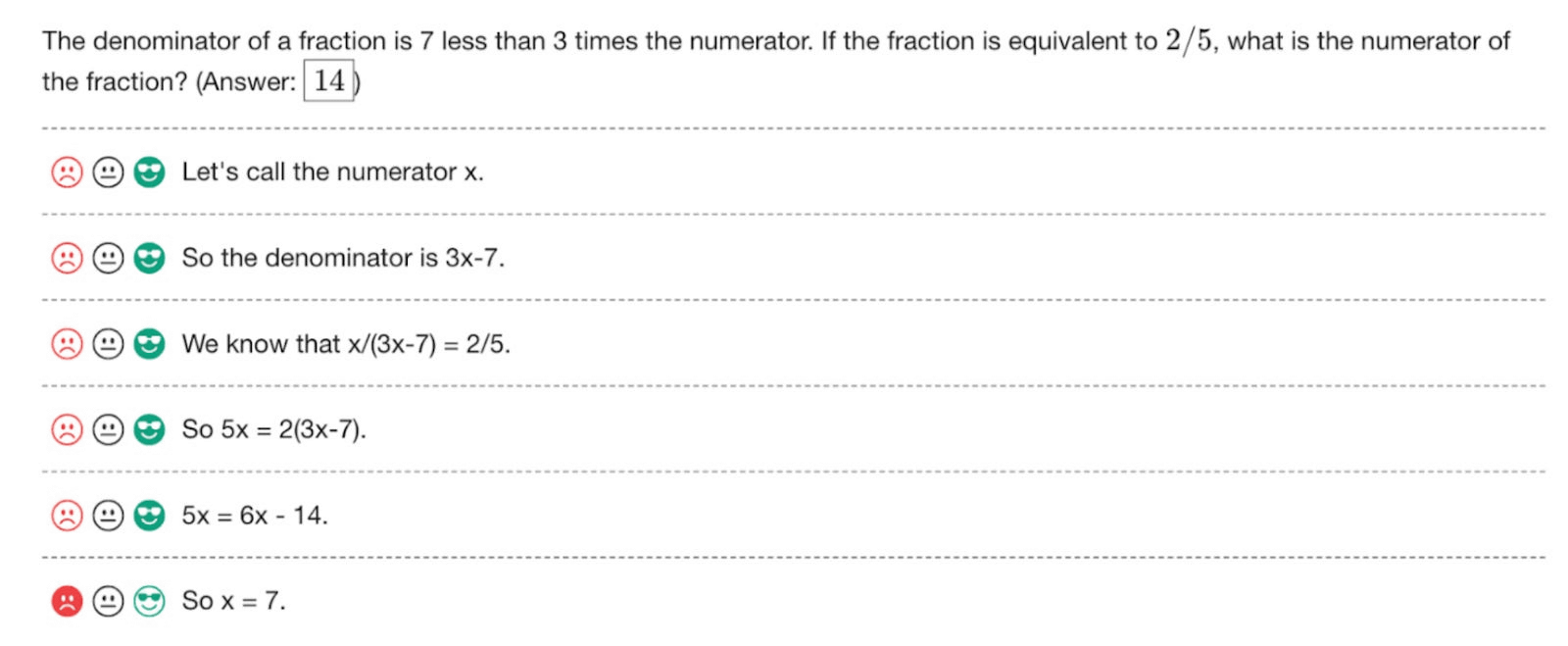
The advantage of this method is that using a validation model at each step of the inference process increases the accuracy of the answer. However, although the training data consists of a set of questions and answers, there is no way to verify whether the inference step itself is correct. Therefore, OpenAI has introduced a method in which humans are employed to evaluate the final accuracy of 800,000 steps in 75,000 different solution methods.
What if it's a logic problem rather than a calculation? Mr. Lee cites the following problem as an example.
“There will be five tables set up for the reception, and each table will seat three guests.
-Alice doesn't want to sit with Bethany, Ellen, and Kimmy.
-Bethany doesn't want to sit with Margaret.
-Chuck doesn't want to sit with Nancy.
Fiona doesn't want to sit with Henry or Chuck.
-Jason doesn't want to sit with Bethany and Donald.
-Grant doesn't want to sit down with Ingrid, Nancy, and Olivia.
-Henry doesn't want to sit with Olivia, Louise, and Margaret.
・Louise doesn't want to sit with Margaret and Olivia.
How do you seat your guests so that all of these preferences are respected? ”
When you input the above problem into GPT-4, GPT-4 starts reasoning step by step. Although I was able to solve the problem up to the third table, I was unable to solve the problem at the fourth table. The reason for this problem is that if you simply reason out the conditions from the top in the order they are presented, the later conditions will be related to the earlier ones, resulting in inconsistencies in your answers.
In order for a large-scale language model to solve this problem, it is necessary to proceed with inference by following the following route. Only the rightmost route will allow you to answer all questions correctly; anything else will fail no matter what you do. In other words, the probability of drawing an inference route that yields the correct answer is 1/4.
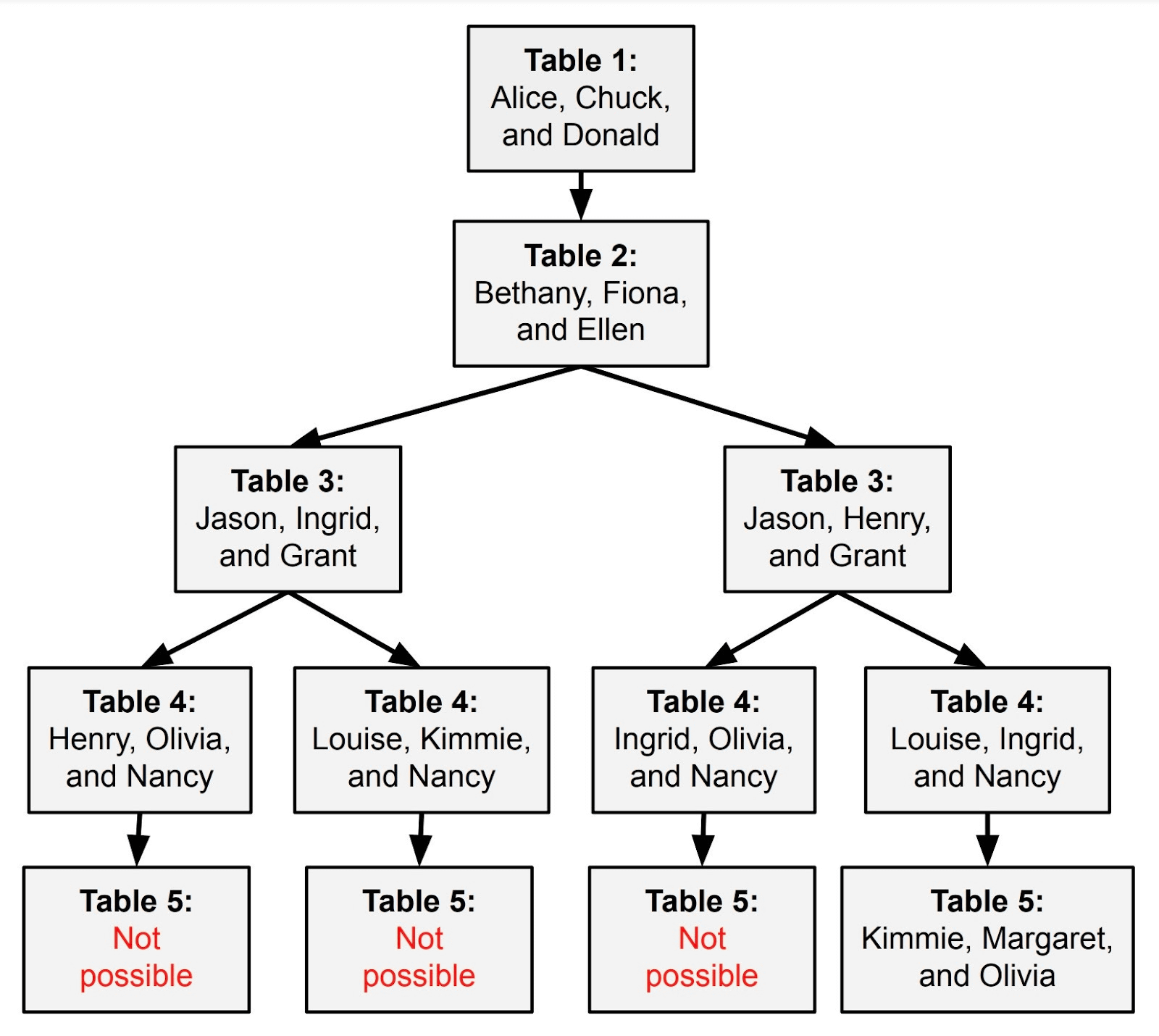
A paper published in May 2023 by researchers from Google DeepMind and Princeton University suggests that instead of solving a problem with a single inference route, you can systematically check a series of inference routes that branch out in different directions. announced an approach called the Tree of Thoughts . The research team argued that this algorithm is highly effective in solving problems and text generation that are difficult to solve using conventional large-scale language models.
Google DeepMind focused on the Go AI AlphaGo for this part of ``systematically checking multiple inference routes''. If AlphaGo, which instantly evaluates and makes decisions about various moves, is combined with a large-scale language model, the inference ability of the large-scale language model may also be improved.
OpenAI hired computer scientist Norm Brown in early 2023. Mr. Brown is a person who developed an AI that can play poker at a superhuman level , and after that he also conducted AI research in Meta. 'Q* could be OpenAI's plan. They almost hired Norm Brown to work on Q*,' said Yan LeCun, lead AI researcher at Meta. ” states.
Please ignore the deluge of complete nonsense about Q*.
— Yann LeCun (@ylecun) November 24, 2023
One of the main challenges to improve LLM reliability is to replace Auto-Regressive token prediction with planning.
Pretty much every top lab (FAIR, DeepMind, OpenAI etc) is working on that and some have already published…
Mr. Brown was conducting research on AI that plays poker and diplomacy , but posted in June 2023, ``From now on, we are researching how to truly generalize these methods.''
I'm thrilled to share that I've joined @OpenAI ! ???? For years I've researched AI self-play and reasoning in games like Poker and Diplomacy. I'll now investigate how to make these methods truly general. If successful, we may one day see LLMs that are 1,000x better than GPT-4 ???? 1/
— Noam Brown (@polynoamial) July 6, 2023
The methods used by AlphaGo and Brown's poker AI were specific to specific games. However, Brown predicted, ``If we can find a common version, the benefits will be huge.''
However, Lee says that OpenAI needs to overcome at least two major challenges to truly complete Q*.
One is to 'discover how large-scale language models can reproduce themselves.' For example, AlphaGo played a match and received feedback on whether it won or lost. In order to improve the accuracy of OpenAI's Q*, it is necessary to have a mechanism that feeds back the results of whether the problem has been solved or not. As of May 2023, OpenAI was using hired humans to check its correctness. If there is a breakthrough, we can say that a major discovery will be made within 2023.
Another is that ``general inference algorithms require the ability to learn on the fly while searching for possible solutions.''
Today's neural networks separate training and inference. For example, AlphaGo does not learn and evolve while playing Go, but instead learns by providing feedback to itself after the game is over. However, if you are a real person, you can experience all the situations that can occur during a game of Go, and play the game while learning as you go.
'Wouldn't building a truly general inference engine require more fundamental architectural innovations? Just like the human brain, we have no idea that this is possible,' Lee said. 'But it may be a while before OpenAI or DeepMind or anyone else figures out how to do it in silicon.'
Related Posts:







in Software, Posted by log1i_yk