







ディープラーニングで翻訳プログラムを0から作った人がその仕組みを複雑な数式ではなく図で解説するとこうなる

テクノロジーが発達することで、専門家でなくてもニューラルネットワークを使って翻訳プログラムを作ることが可能になりました。とは言っても、全く知識がない人にその仕組みを理解するのは難しいもの。そこでライターのSamuel Lynn-Evansさんが自分で情報を調べつつ0から翻訳プログラムを作成し、その時に理解した仕組みを数式を使わずに説明しています。
Found in translation: Building a language translator from scratch with deep learning
https://blog.floydhub.com/language-translator/
言語は非常に複雑で、これまで機械翻訳を行うには何人もの専門家が必要でした。しかし、人工知能(AI)の発達により、もはや専門家でなくても機械翻訳を行うことが可能になりました。これまで専門家が扱っていた言語のルールを、ニューラルネットワークが自動的に学んでくれるようになったためです。
では実際に専門家ではない人物が機械翻訳に手を出すと、どんなことになるのか?ということで、ライターのLynn-Evansさんは、AIを使った言語翻訳プログラムを0から構築し、完成させました。Lynn-Evansさんは過去10年間にわたって科学と言語学の教師として働き、42歳にしてパリでAIについて学び始めた人物です。
Lynn-Evansさんが作成したのは英語-フランス語の翻訳プログラム。機械翻訳プログラムを作るには最初に大量のデータを「学習」させる必要がありますが、Lynn-Evansさんは8GBのGPUを搭載したマシン1台で3日かけて200万の文章を含むデータベースを学習させたとのこと。Neural Machine Translation(NMT)に詳しい人からすると、この学習量は少ないものとなっています。なお、データベースには1996年から2011年にかけての欧州議会議事録のパラレルコーパスが使用されました。ここには200万以上の文章、5000万以上の単語が含まれています。
翻訳精度を測る「BLEU」という評価アルゴリズムでLynn-Evansさんの翻訳プログラムが訳した3000の文章をテストしたところ、そのスコアは0.39だったとのこと。英語-フランス語のGoogle翻訳のスコアが0.42なので、これは悪くない数字です。
Lynn-Evansさんによると、テストの結果、いくつかの文章はGoogle翻訳よりも高精度で翻訳できていたそうです。しかし、ニューラルネットワークは機械学習のデータに含まれる言葉しか意味を把握できないため、自分の知らない単語には対応できません。そのため、Google翻訳が100%正しく翻訳できることでも、Lynn-Evansさんの翻訳プログラムは「わからない単語を繰り返し述べる」という形で混乱を見せたといいます。
例えば「Tom DupreeとRosie Macyntyreというフィラック出身の2人のペリシテ人は美しいルフィアンの略奪にあった」という固有名詞&珍しい名詞のオンパレードで文章を作ると、インプットの文章(上段)に対し、Google翻訳(下段)は適切な翻訳を行っていますが、Lynn-Evansさんの翻訳プログラム(中段)は明らかに文章が足りないことがわかります。

名詞に弱いという弱点があるものの、全体的に見ると翻訳結果は「信じがたいほどによいもの」だったとLynn-Evansさん。実際に、Lynn-Evansさんが作成した翻訳プログラムのコードは以下から見ることができます。
GitHub - SamLynnEvans/Transformer: Transformer seq2seq model, program that can build a language translator from parallel corpus
https://github.com/SamLynnEvans/Transformer
では翻訳プログラムがどのように動作するのか?という点について、Lynn-Evansさんは数式を使わない形で解説しています。
まず最初にLynn-Evansさんは再帰型ニューラルネットワーク(RNN)を用いた文の生成モデル「Seq2Seq(sequence to sequence)」を使用することを考えます。Seq2Seqは1つのネットワークが入力したシークエンスをエンコード(暗号化)し、その後、別のネットワークがデコード(復号)を行うことで翻訳結果が出力されるというもの。
以下の図では、エンコードされた文章が「State」という状態で記されていますが、このStateという状態はそれ自体が独自の文章のようなもの。英語からフランス語の翻訳は、直接翻訳が行われているのではなく、いったん機械語に翻訳されるのです。

RNNは、文章のように長さが変わる入力を処理する時に、エンコーダー/デコーダーの構築に使われます。以下はVanilla RNNと呼ばれるRNNがエンコードを行うプロセスを可視化したもの。1つ目の言葉、2つ目の言葉、とプロセスが進むごとに「State」がアップデートされているのがわかります。
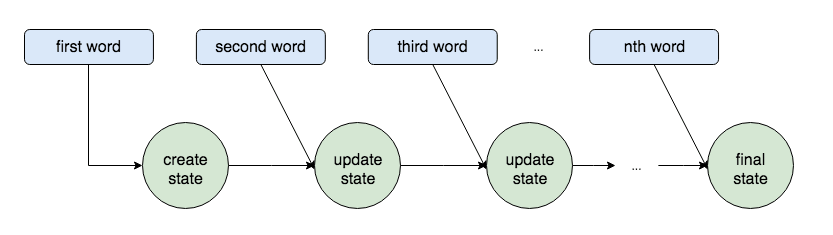
この作業が入力するデータを可変にし、また、正しい順序での処理を可能にしているとのこと。ニューラルネットワークにはRNNの他にも畳み込みニューラルネットワーク(CNN)がありますが、CNNには時系列の概念がなく、「正しい順序」であることが鍵となってくる「文章の翻訳」にはRNNが適しているというわけです。ただしRNNは文章が長くなると文章の最初の方を思い出せなくなるという問題があり、それを解決するために「LSTM(Long short-term memory)」や「GRU(Gated Recurrent Unit)」というモデルが生み出されました。
このとき、エンコーダーの各プロセスは最終的な「State」を生み出すだけでなく、1つ目の言葉、2つ目の言葉の処理の際に、それぞれの「出力」を作り出します。研究者は長年、これら「それぞれの出力」をデコーダーへと渡し翻訳結果をブーストさせるということに気づきませんでした。
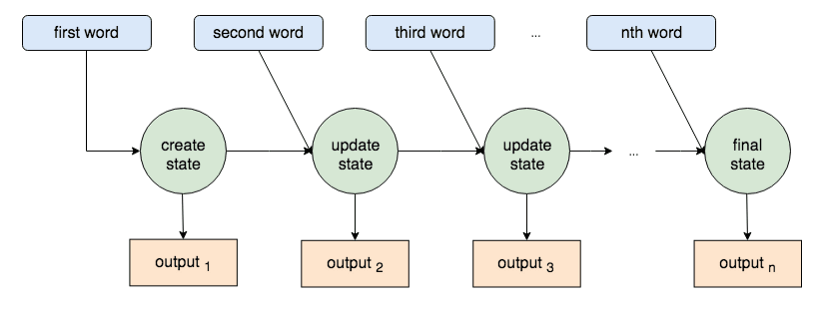
この各出力を利用した「Attentionモデル」はDzmitry Bahdanau氏やMinh-Thang Luong氏によって2015~2016年に発表されました。
Lynn-EvansさんがLSTMモデルやAttentionモデルについて調べているうちに気づいたのは「RNNはかなり速度が遅い」ということだそうです。RNNは反復ループを使ってデータを処理するため、小規模な実験ではうまくいきますが、大規模な機械学習を行うには8GBのGPU1つだと1カ月を要します。
「そんな時間もお金もない」というLynn-Evansさんが発見したのは、RNNやCNNを使わずAttentionのみを使用したニューラル機械翻訳「Transformer」というもの。
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE

Transformerは、「重要なのは『State』ではなく各入力ワードから発生する『出力』だ」と考えたGoogle BrainのAshish Vaswani氏らが発表したモデルです。Transformerモデルは反復ループを行わず、最適化された線形代数ライブラリを利用するものとのこと。RNNは速度の遅さが問題点として挙げられましたが、Transformerはこれにより迅速でより高精度の結果が得られるようになっています。
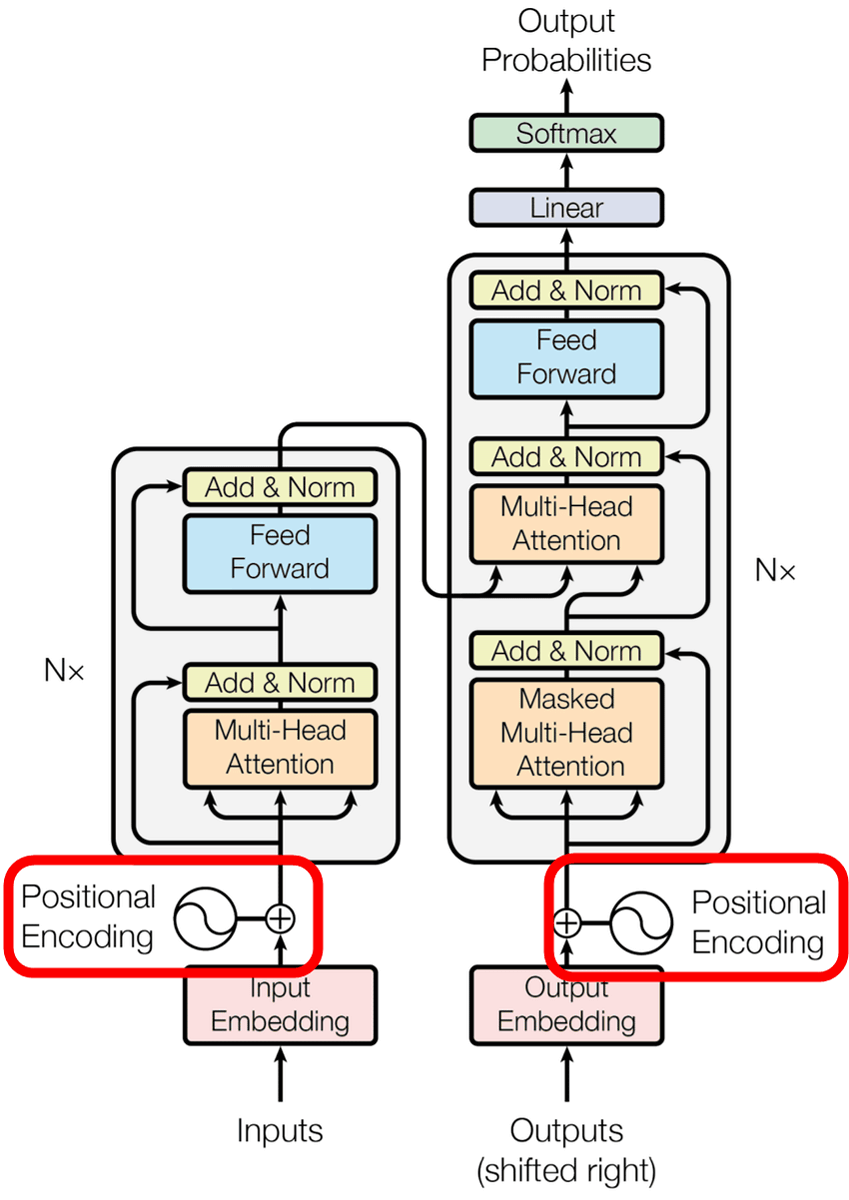
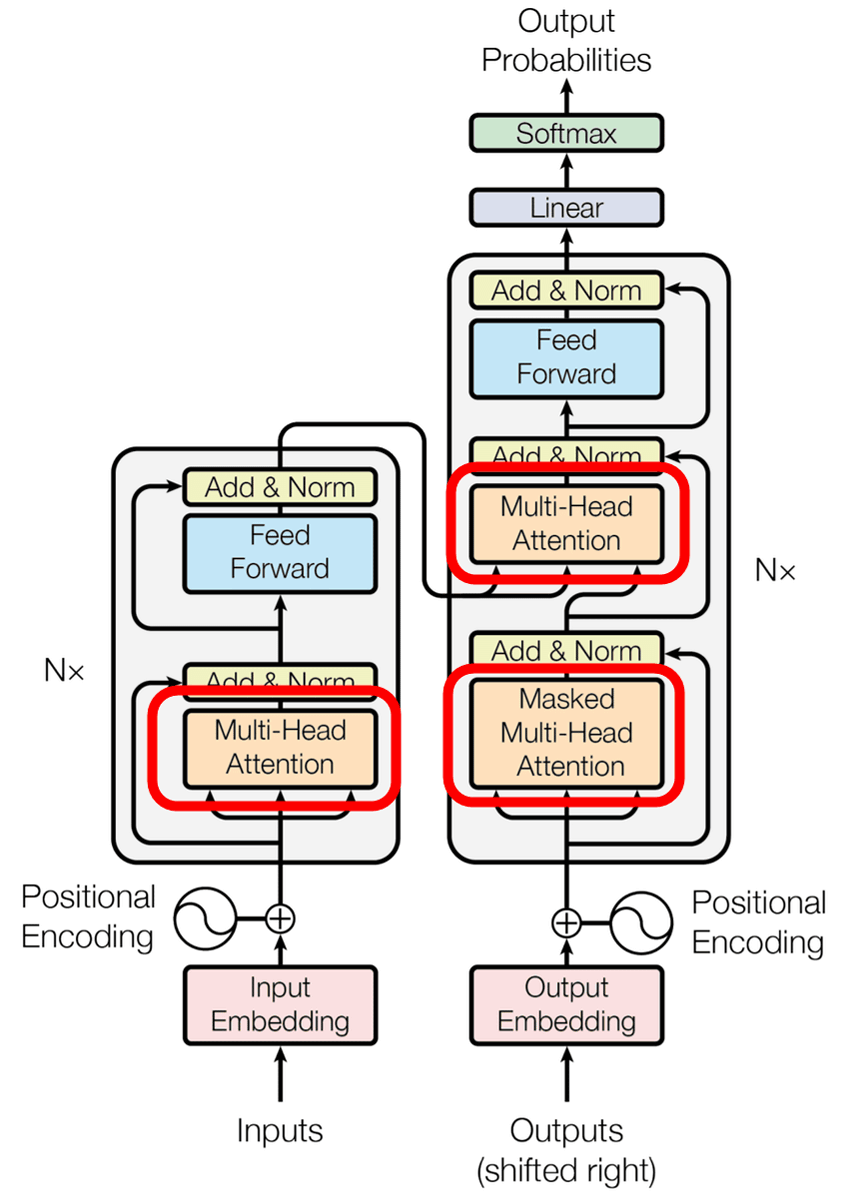
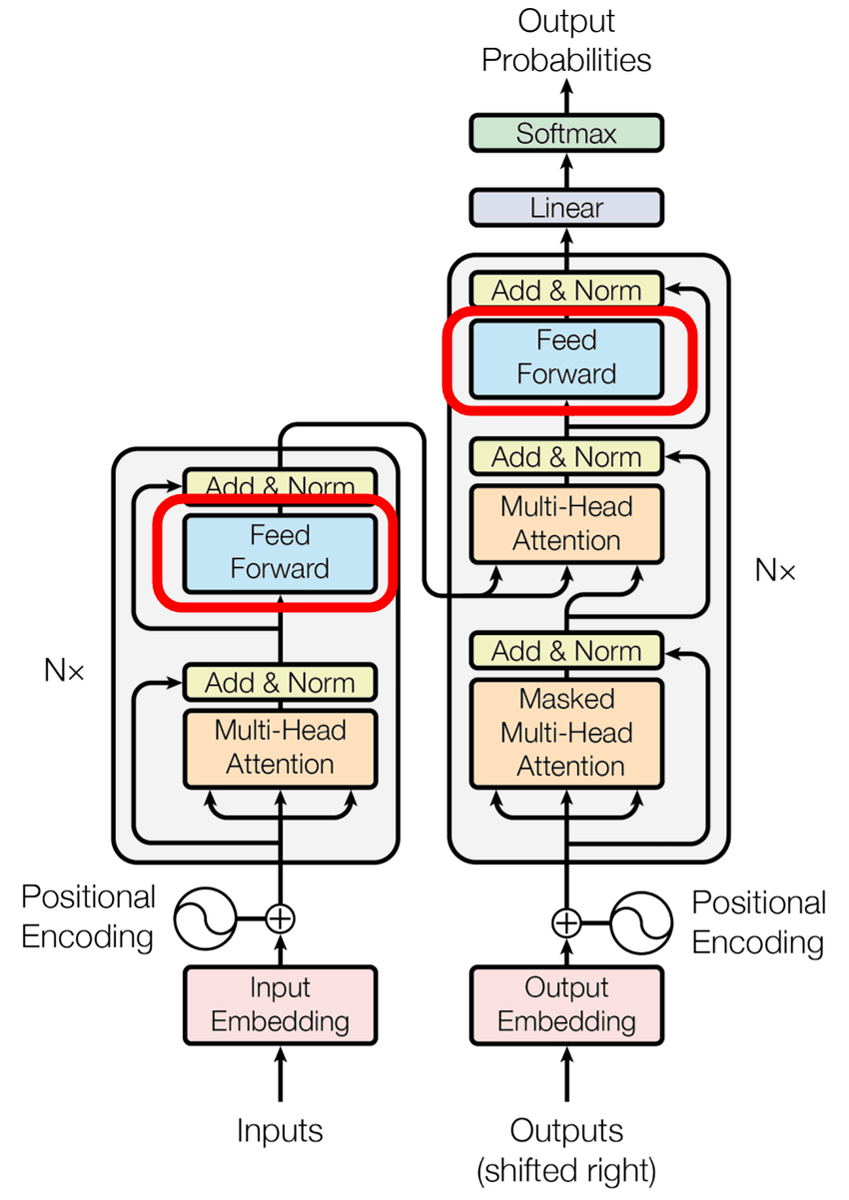
以下がTransformerモデルの概要を表した図。左がエンコーダー、右がデコーダーです。エンコーダーがそれぞれの言葉を出力すると共に、デコーダーでは各出力から次にくる言葉の「予測」が行われるというのがTransformerモデルの特徴です。
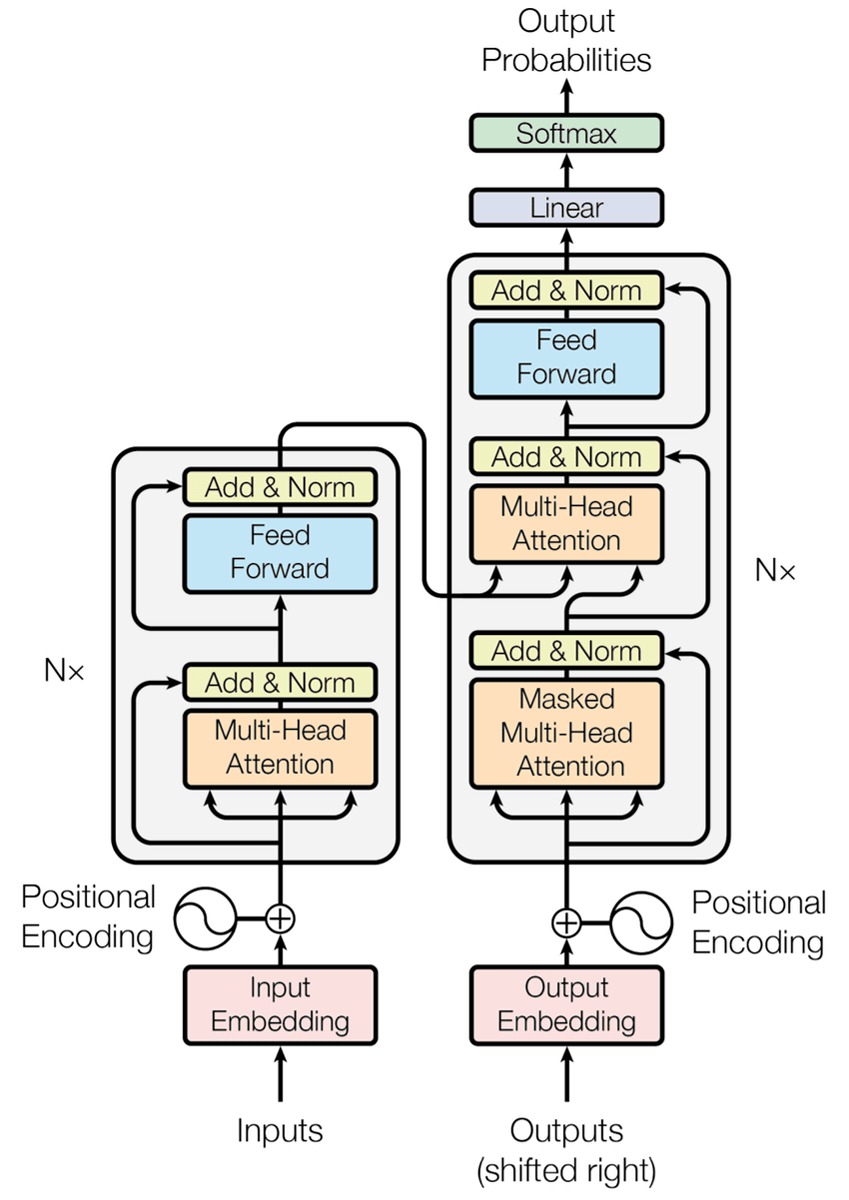
Transformerのプロセスは、大きく以下の4つに分けられます。
1:埋め込み
2:位置エンコーディング
3:Attention層
4:フィードフォアードネットワーク
1:埋め込み
自然言語処理(NLP)において鍵となるのは「埋め込み」です。もともとNLPにおいて、単語を0と1を使って置き換えるone-hotエンコーディングが行われていました。

埋め込みは図でいうところのここ。
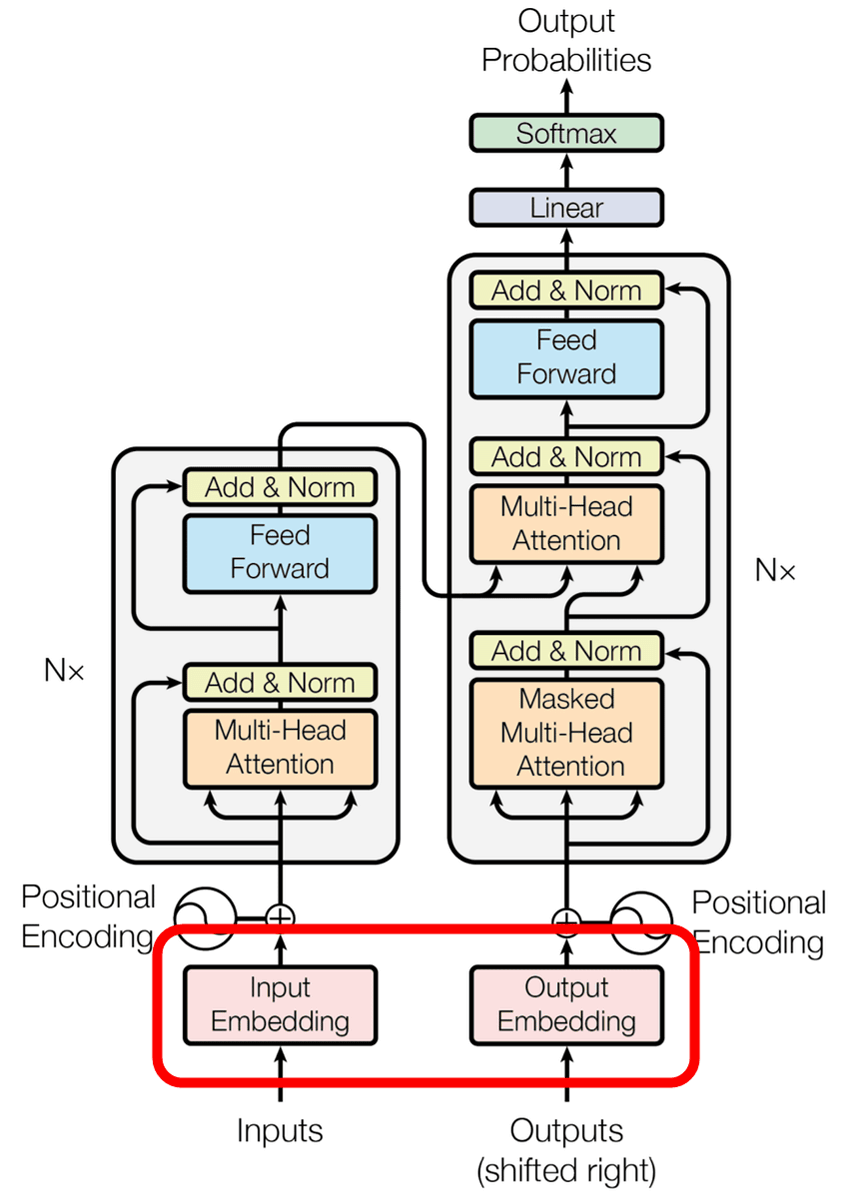
しかし、one-hotエンコーディングはベクトルが巨大になり効率が悪く、また単語という文脈という複数の意味を持つものの情報量を少なくしてしまうということで「埋め込み」が行われるようになりました。埋め込みは、数百次元のベクトル内部に各単語の特徴を格納したもので、モデルが調整可能な値を与えます。

2:位置エンコーディング
埋め込みで単語の意味を数値化することができましたが、文章が成立するには単語の意味だけでなく、「単語が文章のどの位置にあるのか」ということも重要です。これを行っているのが、位置エンコーディングのアルゴリズム。位置エンコーディングによって埋め込みの値に特定の値を追加することで、文章中で単語が特定の順序で並ぶようになります。
位置エンコーディングはここ。
3:Attention層
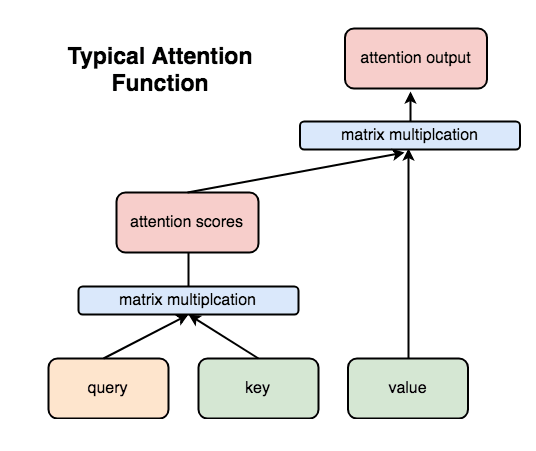
位置エンコーディングされた埋め込み値は、その後、Attention層を通ることになります。一般的なAttention層は以下の通り。query・key・valueという3つの入力があり、queryとkeyの行列の積がAttentionスコアで評価され、その値とvalueの積がAttention出力となっています。
これら一連の行列の積からモデルは次の単語を予測する際に「どの単語の重要度が高いのか」を判断できるようになるとのこと。
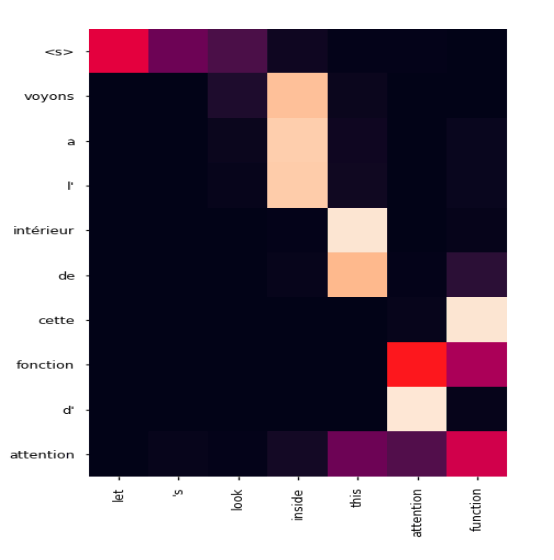
例えば「let’s look inside the attention function」という単語をフランス語に翻訳する際、翻訳プログラムが予測する「次の単語」を示したものが以下。縦軸がフランス語、横軸が英語となっていて、フランス語の最初の単語<S>のトークンが登場すると「let」「's」「look」が可能性のある単語として上がっています。Let'sはフランス語の「voyons」にあたるので、<S>と入力されるだけでニューラルネットワークが翻訳結果の次の単語を予測できているのがわかります。
4:フィードフォアードネットワーク
フィードフォアードネットワークはシンプルに全結合・ReLU・全結合の順に入力を通す構造になっているとのこと。
Lynn-Evansさんによると、8GBのGPUを持つ自分のPCで3日間にわたって学習を行ったところ、最終的に1.3の損失関数で収束したそうです。反省点としては「ディープラーニングは急速に変化する分野であり、もっと調査に時間を割くべきだった」「欧州議会のデータセットは日常会話が欠けてしまう」「翻訳結果の精度を上げるにはビームサーチを使うべき」ということなどが挙げられています。
・関連記事
より高い品質の翻訳を実現するGoogleの「Transformer」がRNNやCNNをしのぐレベルに - GIGAZINE
Facebookが機械翻訳の質を劇的に向上させるAI技術を開発 - GIGAZINE
AIを実現する「ニューラルネットワーク」を自動的に構築することが可能なAIが出現 - GIGAZINE
逆翻訳を利用してAIをバイリンガルにする新しい翻訳技術が開発中 - GIGAZINE
ニューラルネットワークが持つ欠陥「破滅的忘却」を回避するアルゴリズムをDeepMindが開発 - GIGAZINE
・関連コンテンツ






