Introducing the large-scale language model 'Mixtral 8x7B', which is available for free and commercial use, and can demonstrate performance equivalent to or better than GPT-3.5 with low inference cost

Mistral AI, an AI company founded by researchers from Google's DeepMind and Meta, has released Mixtral 8x7B , a large-scale language model that can significantly reduce the size of the model and perform inference with excellent cost performance. It is said to outperform GPT-3.5 and Llama 2 70B in many benchmarks.
Mixtral of experts | Mistral AI | Open source models
Mistral AI is a French startup AI company founded in May 2023, and in September, it created a large-scale language model with performance exceeding 'Llama 2 13B' and 'Llama 1 34B' while keeping the number of parameters to 7 billion. We are actively developing AI, including releasing ' Mistral 7B .' The funding raised in December 2023 was estimated to be approximately 300 billion yen , and the company is rapidly expanding its scale.
Mistral AI released a new model “Mixtral 8x7B” on December 11, 2023. Mixtral 8x7B is a model based on the Mistral 7B model that expands the FeedForward block in the Transformer to 8 times the size. Only part of the model has been multiplied by 8, so the total number of parameters is 46.7 billion instead of 56 billion.
Additionally, instead of using all FeedForward blocks each time during inference, only two of the eight blocks are used to process tokens, reducing the number of parameters used to process tokens to 12.9 billion. I am. By using this mechanism, it is possible to perform inference at the same speed and cost as with 12.9 billion parameters.
The specifications of Mixtral 8x7B are as follows.
・Can handle 32,000 token contexts
・Supports English, French, Italian, German, and Spanish
- Strong performance in code generation
・With fine tuning, it is possible to create an instruction following model that can achieve a score of 8.3 on MT-Bench.
Mixtral 8x7B scores as well or better than LLaMA 2 70B and GPT-3.5 on various benchmarks used to evaluate large-scale language models. Because the number of parameters is small and the inference cost is low, it is quite cost-effective.
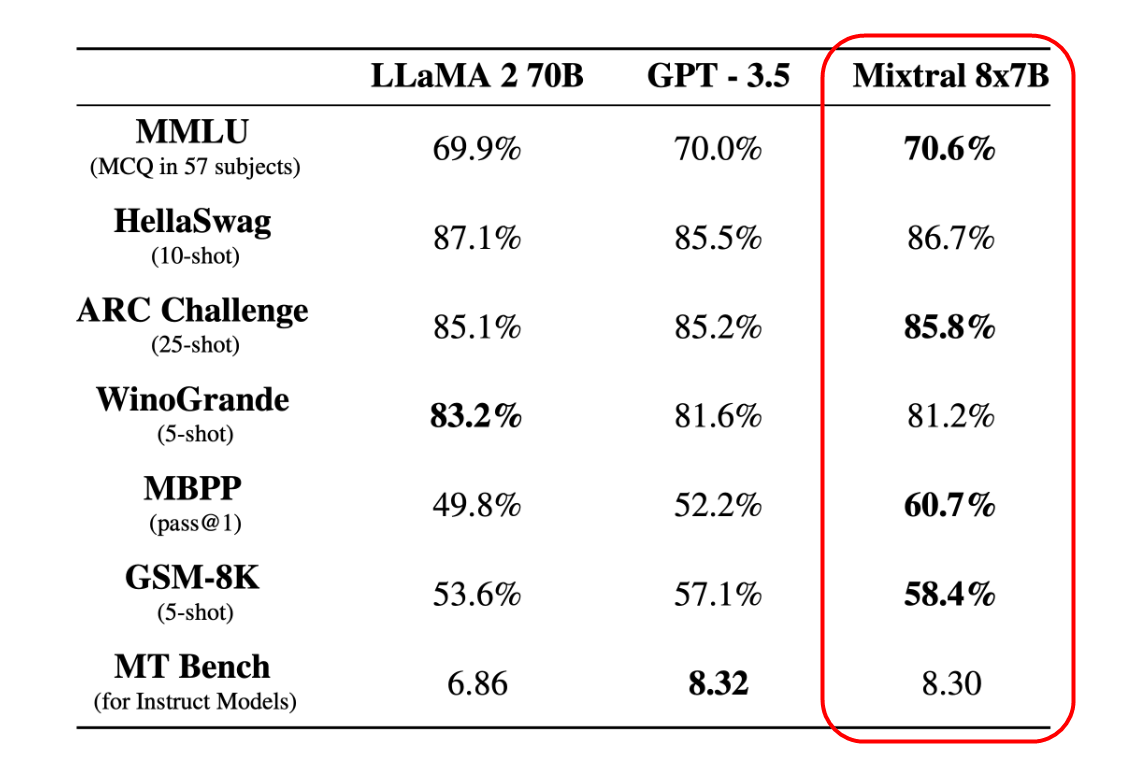
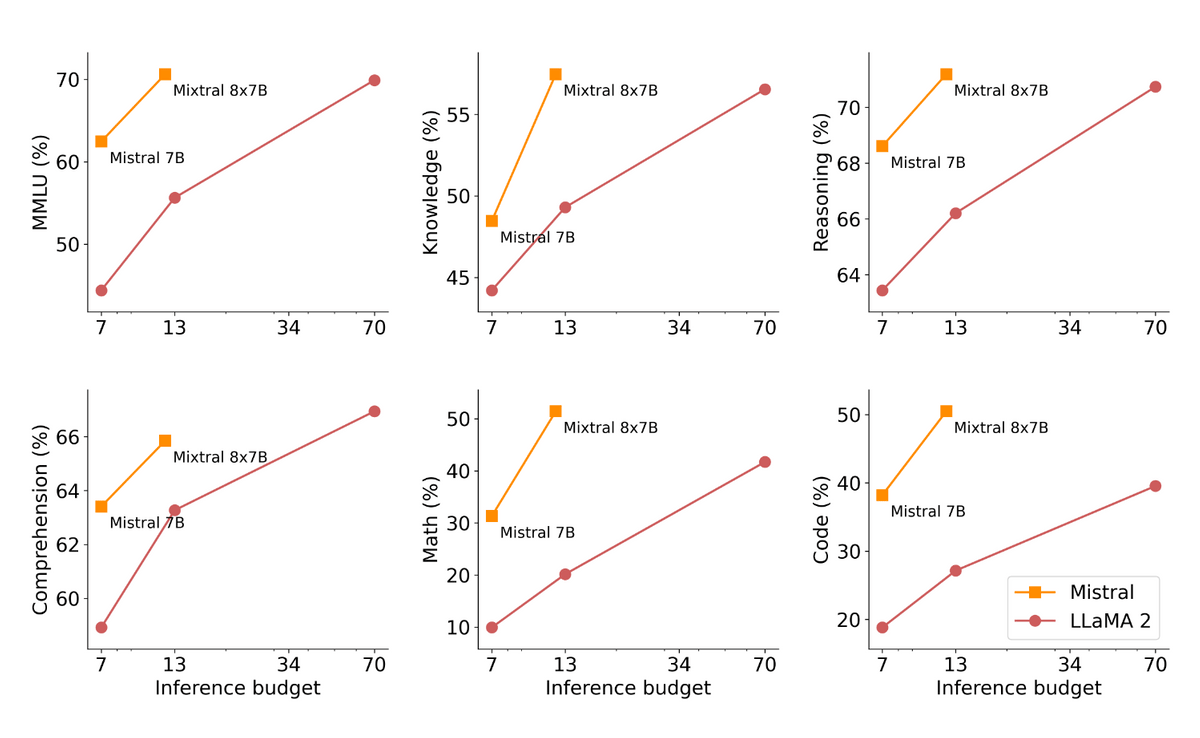
The results of comparing the performance per inference cost with Mistral 7B are shown in the figure below. This figure also shows that performance is improved while reducing inference costs.
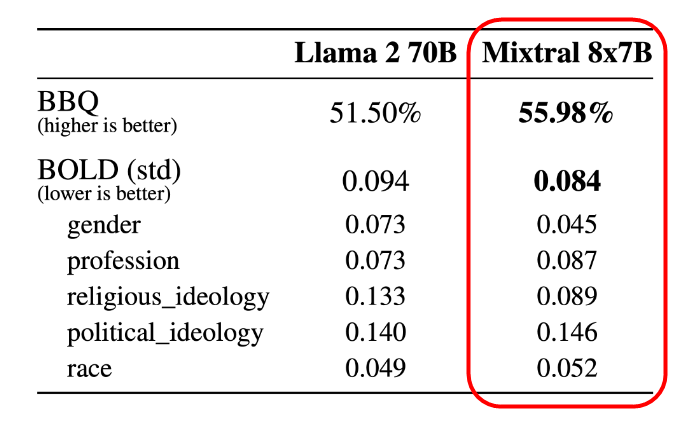
The Mixtral 8x7B also has improvements in hallucinations and prejudice, outperforming the Llama 2 70B model in many metrics.
At the same time, it is also multilingual, and in addition to English, it can handle French, Italian, German, and Spanish better than the Llama 2 70B model.

Mixtral 8x7B is an open source model licensed under Apache 2.0 and can be freely modified and used commercially. In addition to the model itself being hosted on Hugging Face , it can be used through Mistral AI's mistral-small endpoint. However, at the time of writing the article, the mistral-small endpoint was in beta version, and it was necessary to register on the waiting list and wait for your turn.
Related Posts:






in Software, Posted by log1d_ts