``RedPajama'', a project to develop a completely open source large-scale language model that is free for commercial use, has released a training dataset

AI technology is rapidly spreading due to large-scale language models such as OpenAI's GPT-4. However, many large-scale language models such as GPT-4 are either closed commercial models or only partially open. “ RedPajama ” is a project to develop a fully open-sourced large-scale language model, and as the first step, the LLaMA training dataset containing over 1.2 trillion tokens has been released.
RedPajama, a project to create leading open-source models, starts reproducing by LLaMA training dataset of over 1.2 trillion tokens — TOGETHER
https://www.together.xyz/blog/redpajama

GitHub - togethercomputer/RedPajama-Data: The RedPajama-Data repository contains code for preparing large datasets for training large language models.
https://github.com/togethercomputer/Red Pajama-Data
RedPajama is an effort to create reproducible and fully open language models, a collaborative effort by AI startups Together , Ontocord.ai , ETH DS3Lab from ETH Zurich, Stanford CRFM from Stanford University, Hazy Research and MILA Québec AI Institute. It's on-going as a project.
This Redpajama is based on 'LLaMA' developed by Meta. LLaMA is a large-scale language model trained on a dataset of 1.2 trillion tokens, and features a 7 billion parameter model that is much lighter than GPT-4 and Chincilla but has comparable performance.
Meta announces large-scale language model 'LLaMA', can operate with a single GPU while having performance comparable to GPT-3 - GIGAZINE

However, although LLaMA is partly open-sourced, it is only available for non-commercial research purposes and the weight data is not publicly available. Therefore, RedPajama aims to be developed as 'completely open source that can also be used for commercial applications'.

RedPajama is ``developing high-quality pre-learning data that covers a wide range,'' ``developing a base model that has been trained on a large scale with that pre-learning data,'' and ``tuning data that improves the base model to make it easier to use and safer.'' and model development”, and the pre-learning data “RedPajama-Data-1T”, which is the first stage, was released this time on Hugging Face, a repository site for AI. increase.
togethercomputer/RedPajama-Data-1T Datasets at Hugging Face
https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T
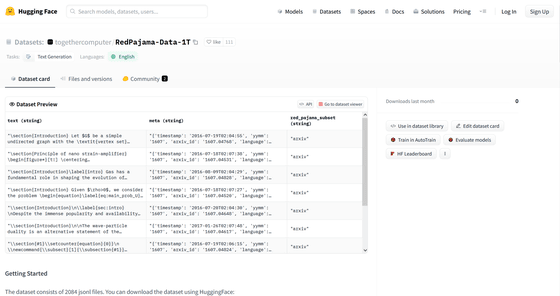
RedPajama-Data-1T consists of 7 data slices, 'CommonCrawl', 'C4', 'GitHub', 'arXiv', 'Books', 'Wikipedia', and 'StackExchange', depending on the source of the dataset, each of which is carefully It is said that preprocessing and filtering are being done. RedPajama-Data-1T is a reproduction of the dataset used in LLaMA, and the number of tokens in each data slice is quite close.
RedPajama's next goal is to use this RedPajama-Data-1T to train powerful large-scale language models. Already at the time of writing the article, training is underway with the support of the Oak Ridge Leadership Computing Facility (OLCF) , and the first model will be available in May 2023.
Related Posts:







in Software, Posted by log1i_yk