Qwen releases open source AI model 'QWQ-32B' that achieves performance almost on par with DeepSeek, and a demo page that anyone can run for free is also available
Qwen, an AI research team at Alibaba Cloud, released the AI model ' QWQ-32B ' on March 6, 2025. Although it is a model with 32 billion parameters, it is said to have the same performance as
DeepSeek-R1
, which has 671 billion parameters.QwQ-32B: Embracing the Power of Reinforcement Learning | Qwen
https://qwenlm.github.io/blog/qwq-32b/
DeepSeek-R1 utilizes reinforcement learning (RL) to achieve higher performance than conventional pre-training and post-training methods. Its performance was so high that when DeepSeek-R1 was released in January 2025, it caused a major disruption, includinga drop in NVIDIA's market capitalization of 91 trillion yen .
Why is DeepSeek causing such a fuss and what's so great about it?

The Qwen research team applied reinforcement learning to a base model that was pre-trained with extensive world knowledge. First, reinforcement learning was performed specifically for math and coding tasks, and then reinforcement learning for general features was performed in a separate stage, allowing the model to perform general tasks while still improving its math and coding performance.
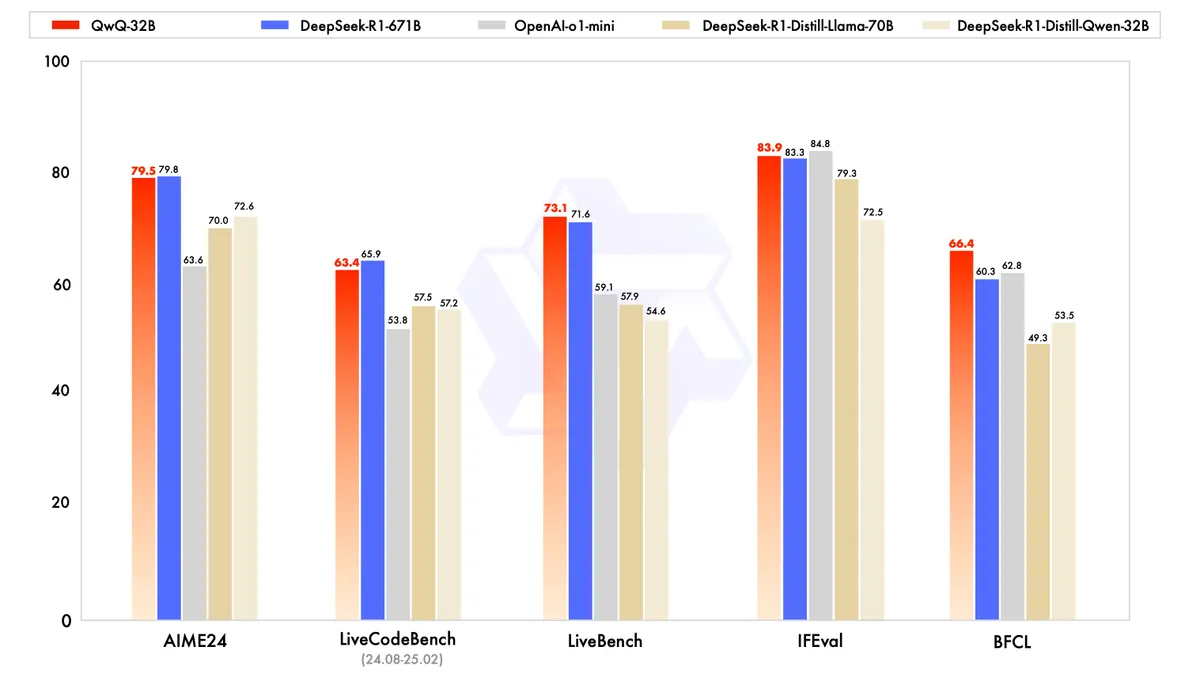
Various benchmark results look like this. The red one is the QwQ-32B and the blue one is the DeepSeek-R1-671B. In both benchmarks, the QwQ-32B performs on par with the DeepSeek-R1-671B model.
There is a free
demo
available for anyone to try out QwQ-32B, so I'll try it out. This time, I entered the prompt 'Prove that for a given natural number n, n^3 + (n+1)^3 + (n+2)^3 is always divisible by 9.'When you enter a prompt, the thinking phase begins. I entered the question in Japanese, and looking at the contents of the thinking, it seems to have been understood correctly.
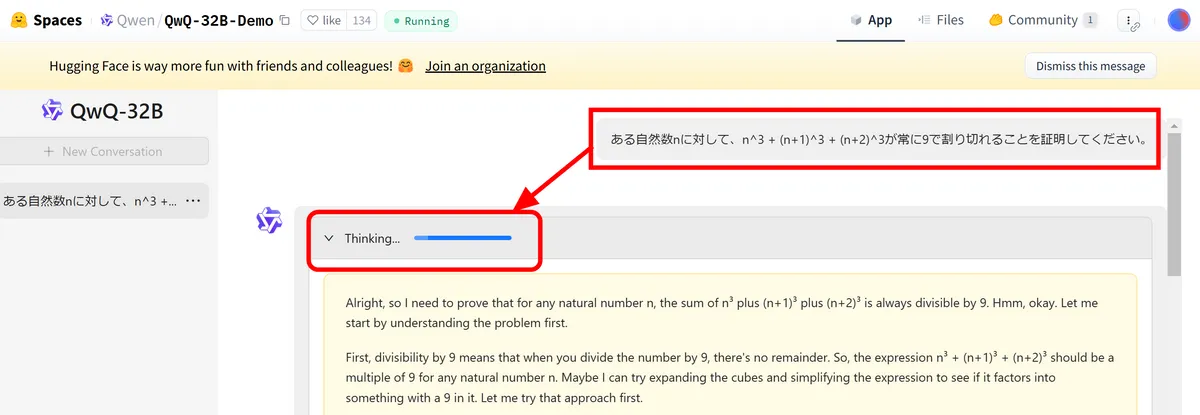
After about three minutes of thinking, the correct answer was printed out, albeit in English.

It also seems to support output in Japanese, and by instructing it to 'output in Japanese,' it converted the answers into Japanese.

The Qwen research team said, 'We have witnessed the immense potential of reinforcement learning,' and about the development of the next generation of Qwen, 'we are confident that by combining more powerful underlying models with reinforcement learning, we can get closer to realizing artificial general intelligence (AGI).'
Related Posts: