




独自のデータセットでGPTのような大規模言語モデルを簡単にファインチューニングできるライブラリ「Lit-Parrot」をGoogle Cloud Platformで使ってみた

特定の分野についての知識を増やす場合など、大規模言語モデルの出力を特定の方向に寄せる場合に利用されるのがファインチューニングで、これはモデルをゼロから構築するのに比べてはるかに少ないデータセット&はるかに少ないコストでトレーニングできる手法です。「Lit-Parrot」はファインチューニングを簡単に行えるようにしたライブラリとのことなので、実際に使ってどれくらい簡単なのかを試してみました。
lit-parrot/scripts at main · Lightning-AI/lit-parrot · GitHub
https://github.com/Lightning-AI/lit-parrot
How To Finetune GPT Like Large Language Models on a Custom Dataset - Lightning AI
https://lightning.ai/pages/blog/how-to-finetune-gpt-like-large-language-models-on-a-custom-dataset/
ファインチューニングを行うにあたって、32GB以上のメモリおよび12GB以上のGPUメモリを搭載したマシンが必要です。今回はGoogle Cloud Platform(GCP)上に仮想マシンを用意します。GCPのコンソールを開き、左上のメニューから「Compute Engine」を選択し、「VMインスタンス」をクリックします。

「インスタンスを作成」をクリック。
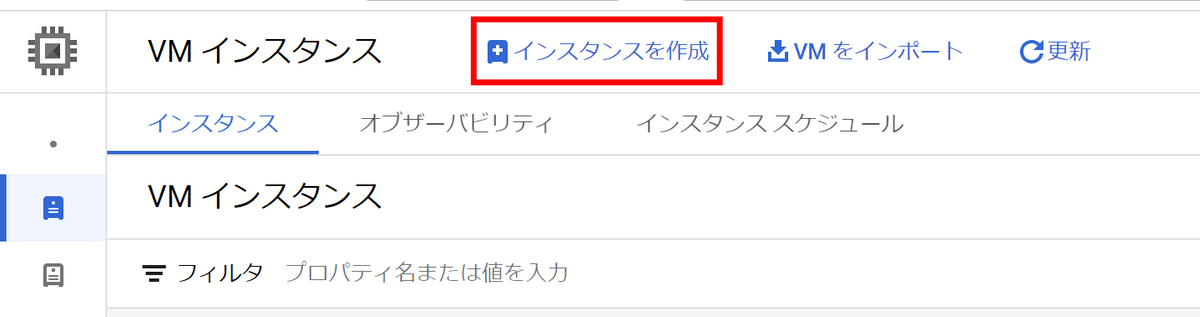
わかりやすい名前を付けてゾーンを「asia-northeast1-a」に設定します。このゾーン選択次第で利用できるGPUが異なっています。
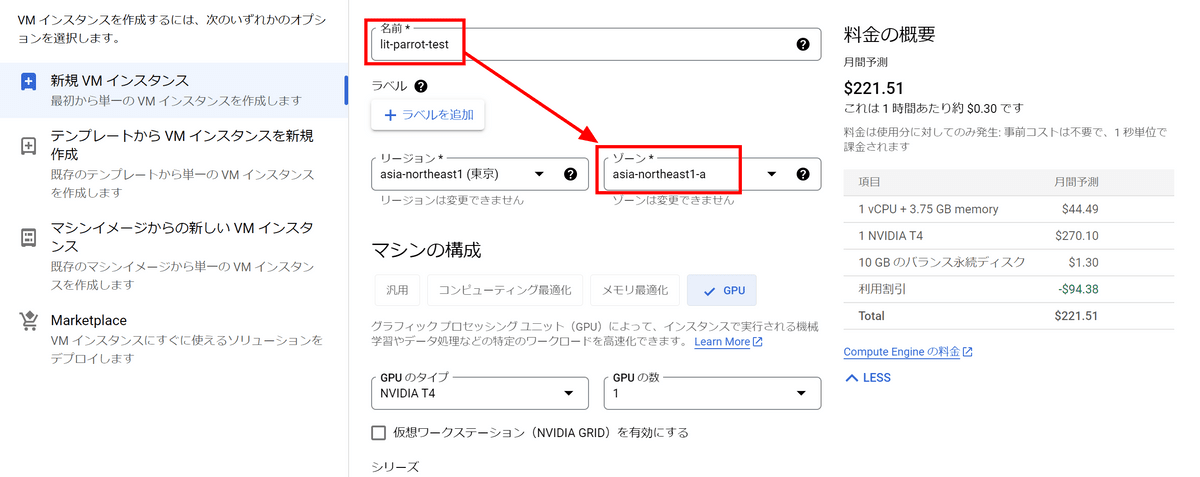
Lit-Parrotのファインチューニングではbfloat16に対応したGPUが必要です。今回はNVIDIA A100 40GBを選択しました。GPUでA100を選択するとマシンタイプが自動でa2-highgpu-1gに変わります。
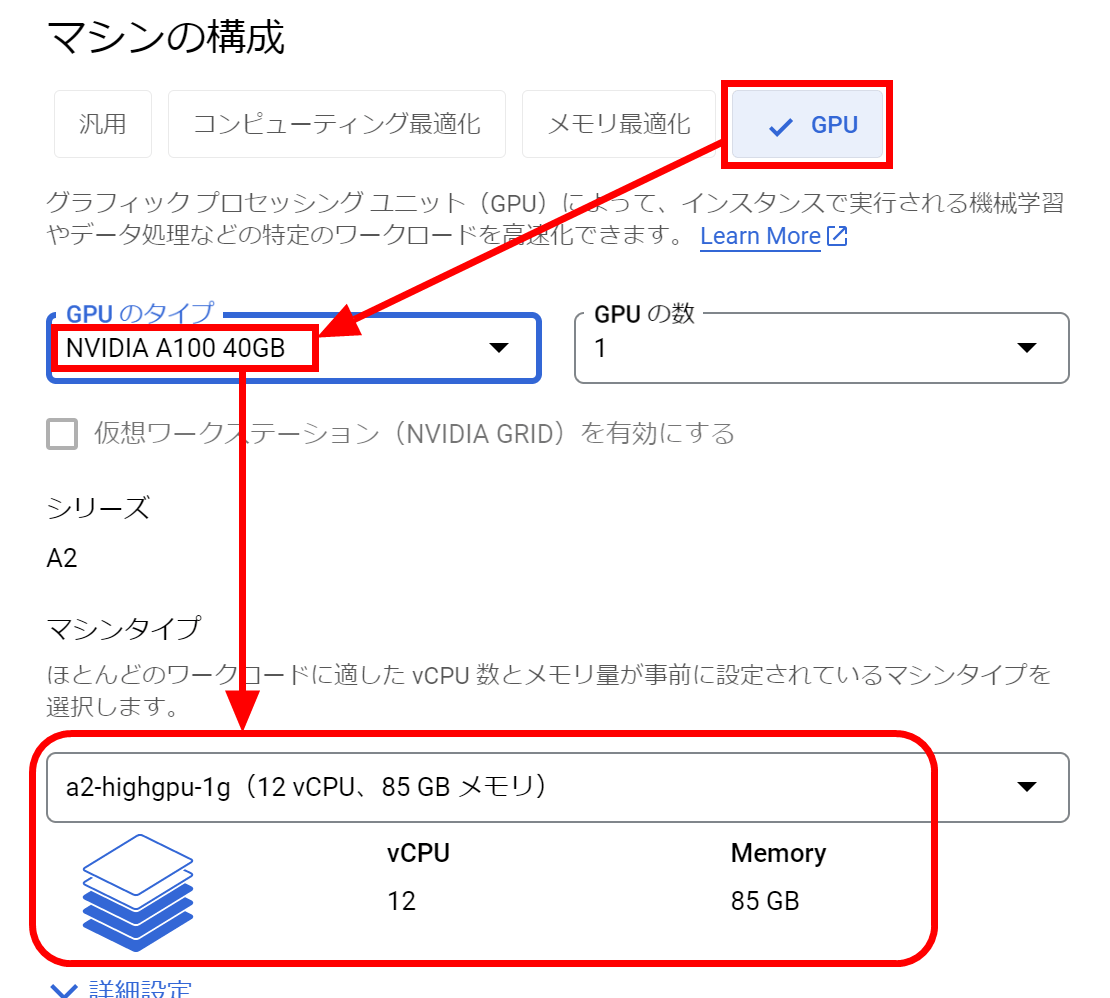
ディスクの容量が小さいので変更します。「変更」をクリック。
サイズを50GBに変更し、「選択」をクリックします。なお、GCPではCUDAがプレインストールされているイメージが用意されていますが、利用したいCUDAのバージョンと一致しないので、今回はCUDAを手動でインストールします。
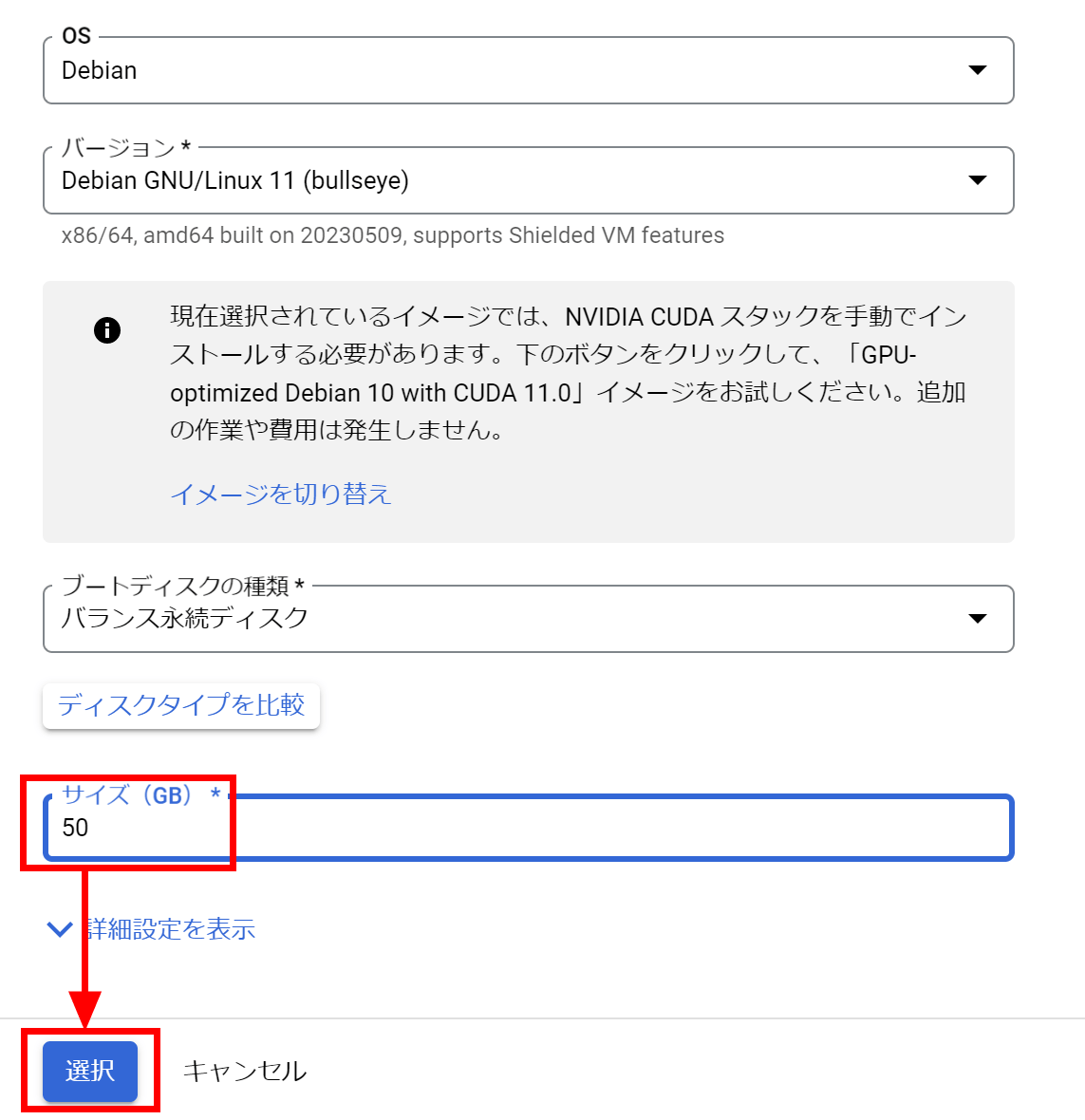
A100 GPUの利用料金はかなり高額なので、少し対策をします。「詳細オプション」をクリックして開き、「管理」をクリック。
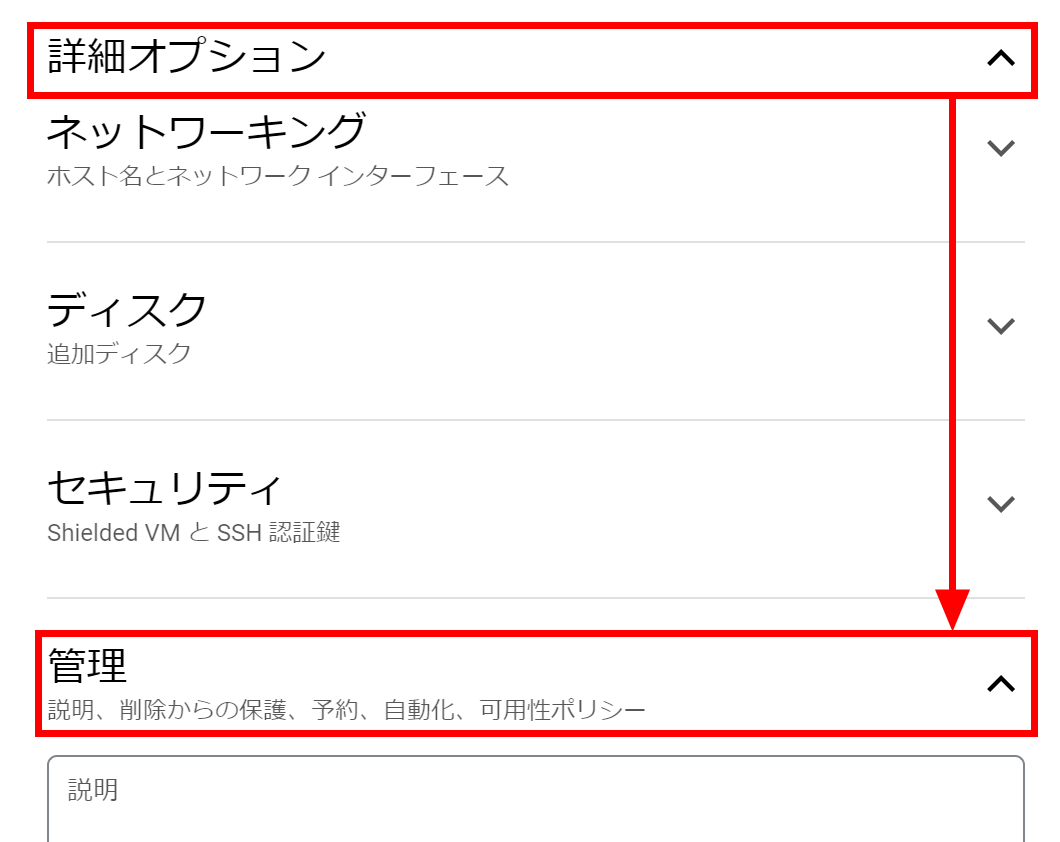
「可用性ポリシー」の「VMプロビジョニングモデル」が標準になっています。現状では1時間ごとに4.06ドル(約570円)の利用料金がかかるとのこと。
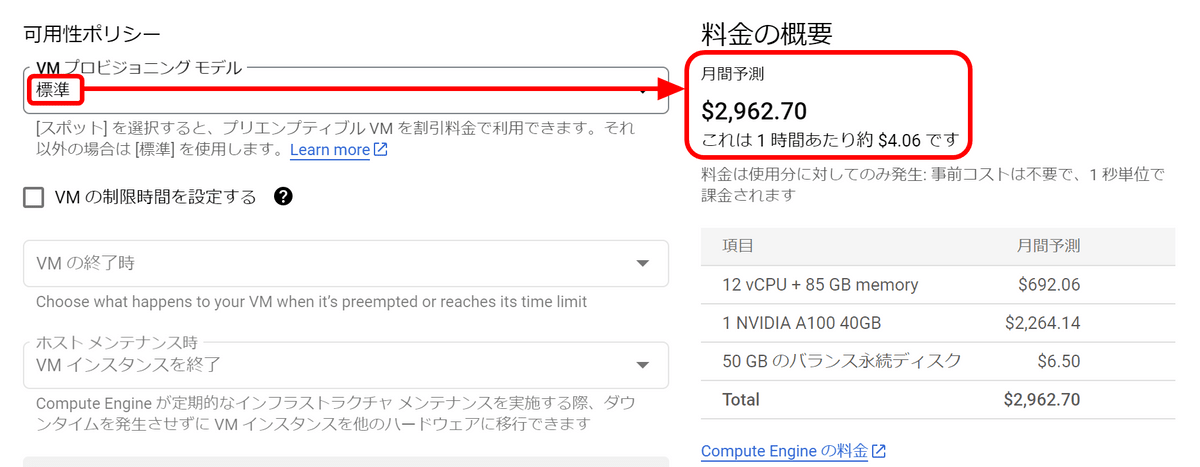
これを「スポット」に変更すると、1時間あたりの料金が1.22ドル(約170円)まで下がりました。もちろん、スポットにすることでGoogleの都合で突然シャットダウンされる可能性が発生しますが、今回はファインチューニングのために短時間起動するだけで、途中で終了したときに困るようなデータを扱わないので問題なさそうです。
その他の設定は初期状態のままで「作成」をクリック。

状態欄に緑のチェックマークが入ったら「SSH」をクリックしてサーバーに接続します。

ブラウザでSSH画面が開くので、ここからコマンドを入力していきます。
まずは下記のコードで各パッケージを更新しておきます。
sudo apt update && sudo apt upgrade -y
下記のコマンドでpipとgitをインストール。
sudo apt install python3-pip git -y
GCPのドキュメントの「GPUドライバをインストールする」ページを参考に、下記のコマンドでGPUドライバーおよびCUDAをインストールします。
curl https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-installation/main/linux/install_gpu_driver.py --output install_gpu_driver.py
sudo python3 install_gpu_driver.py
これで環境構築は完了です。下記のコマンドでLit-Parrotのリポジトリをクローンします。
git clone https://github.com/Lightning-AI/lit-parrot.git
cd lit-parrot
Lit-Parrotは記事作成時点でPyTorchのnightlyバージョンにしか搭載されていない機能を利用するとのことなので、下記のコマンドで通常のライブラリとは別にインストールを行います。
pip install --index-url https://download.pytorch.org/whl/nightly/cu121 --pre 'torch>=2.1.0dev'
そして下記のコマンドでその他のライブラリをまとめてインストール。
pip install -r requirements.txt
また、Hugging Faceからモデルをダウンロードするためのライブラリが必要なので別途インストールしておきます。
pip install huggingface-hub
今回はファインチューニングの元のモデルとして「RedPajama-INCITE」のBase-3B-v1を利用します。RedPajamaについては下記の記事で解説されています。
オープンソースの大規模言語モデル開発プロジェクト「RedPajama」が最初のモデル「RedPajama-INCITE」をリリース、無料で商用利用も可能 - GIGAZINE

下記のコードを入力すると自動でモデルがダウンロードされます。
python3 scripts/download.py --repo_id togethercomputer/RedPajama-INCITE-Base-3B-v1
モデルのダウンロードが完了したら、下記のコマンドでウェイト情報をLit-Parrotの形式に整えます。
python3 scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1
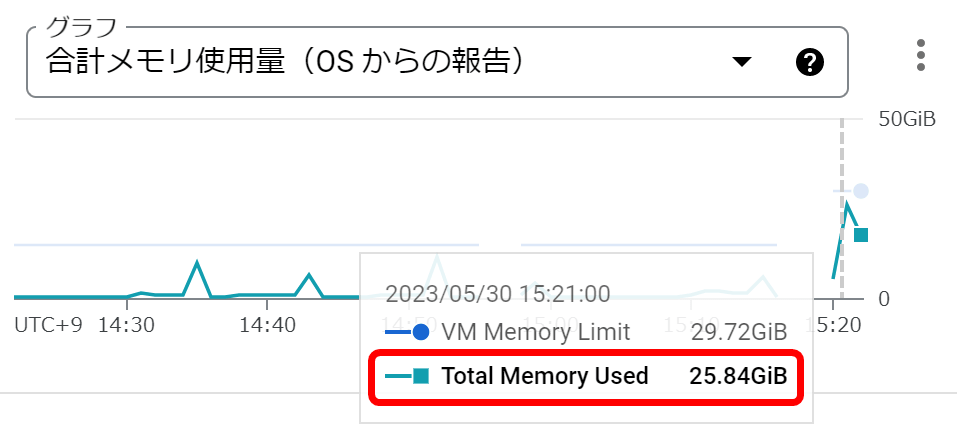
この処理には通常のメモリが約26GB程度必要でした。
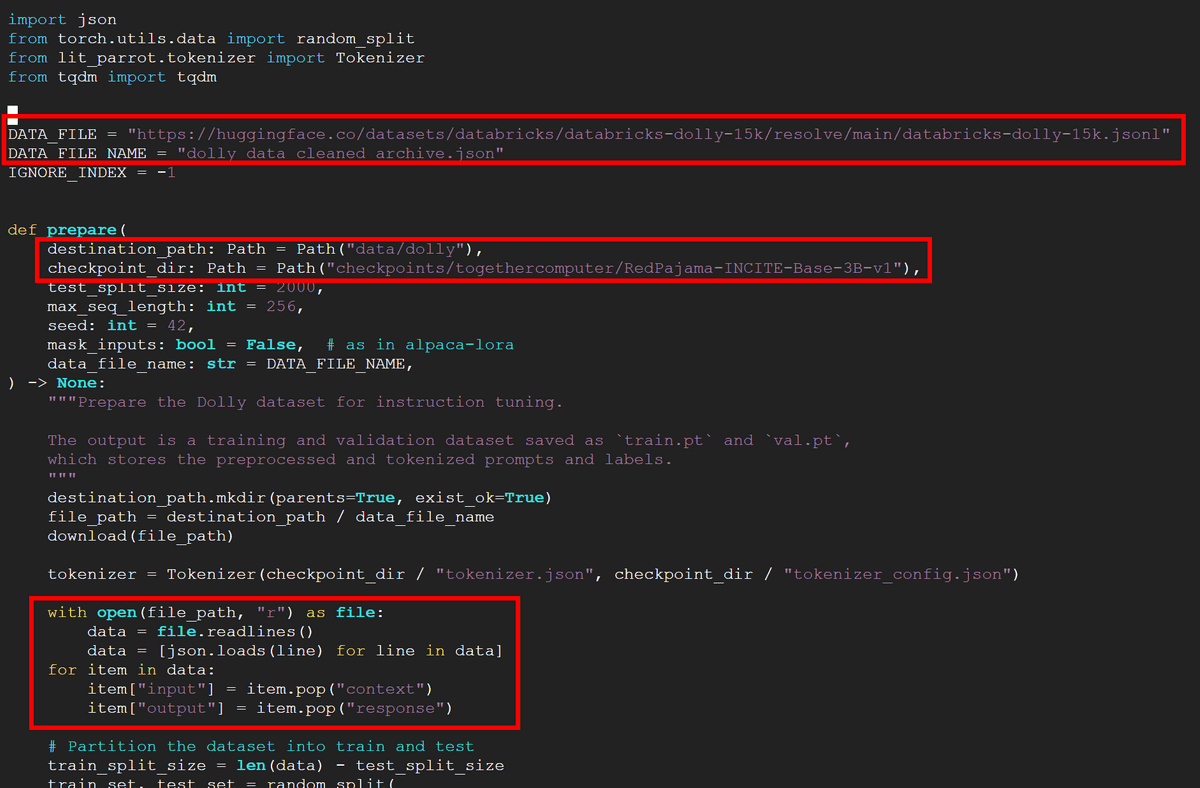
ファインチューニングの設定をするため、下記のコードを入力してprepare_alpaca.pyをテキストエディタで開きます。
vi scripts/prepare_alpaca.py
ファインチューニングに用いる訓練用のデータとして「Dolly 2.0」のファインチューニングに用いられた高品質データセット「databricks-dolly-15k」を利用します。Dolly 2.0については下記の記事で解説されています。
無料で商用利用も可能なオープンソースの大規模言語モデル「Dolly 2.0」をDatabricksが発表 - GIGAZINE

prepare_alpaca.pyに記述されているDATA_FILEをdatabricks-dolly-15kがホストされているURLに設定し、checkpoint_dirを先ほど用意したRedPajamaのディレクトリに書き換えます。さらに、databricks-dolly-15kでは入力・出力の名前が「context」「response」となっているのでそれぞれ「input」「output」に書き換えるコードを追加。
下記のコードでprepare_alpaca.pyを実行してファインチューニングの事前準備を行います。
python3 scripts/prepare_alpaca.py \
--destination_path data/dolly \
--checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1
そして下記のコードでファインチューニングを開始します。
python3 finetune_adapter.py \
--data_dir data/dolly \
--checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1 \
--out_dir out/adapter/dolly
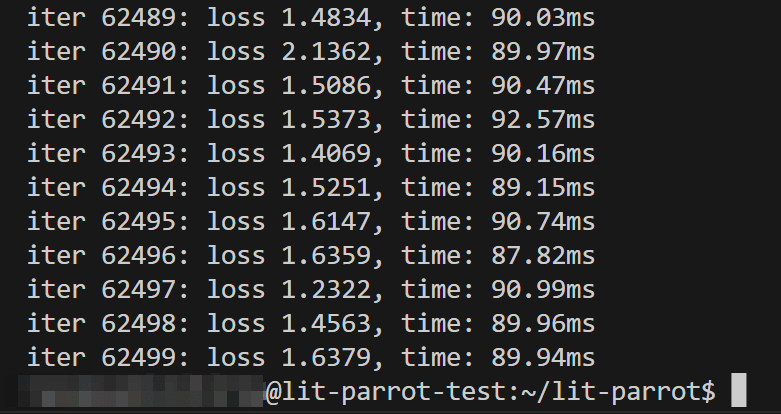
A100 40GB GPUを利用して2時間ほどでファインチューニングが完了しました。
下記のコードを入力し、ファインチューニング後のモデルでの応答を試してみます。
python3 generate_adapter.py \
--adapter_path out/adapter/dolly/lit_model_adapter_finetuned.pth \
--checkpoint_dir checkpoints/togethercomputer/RedPajama-INCITE-Base-3B-v1 \
--prompt "[ここに質問を入力]"
例えば、「ゲーム・オブ・スローンズの作者は?」という質問をしてみると下記の通り「George R. R. Martin」という答えが返ってきました。
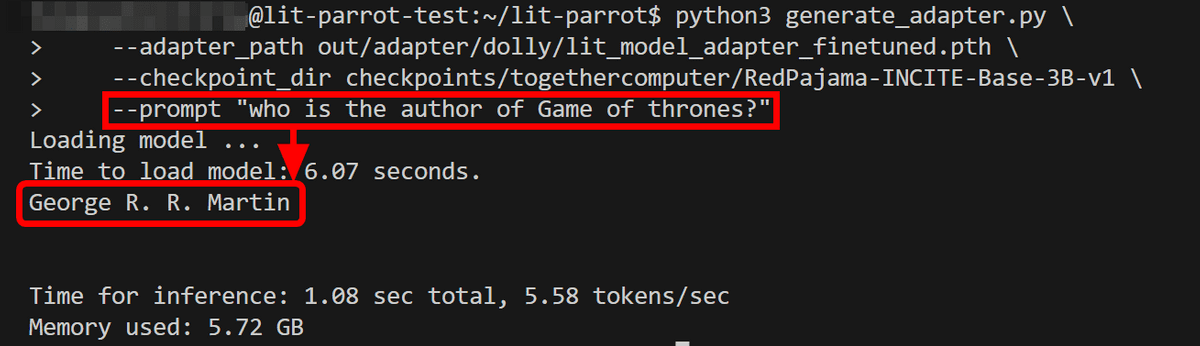
ファインチューニングに利用した「databricks-dolly-15k」データセットの中にゲームオブスローンズの情報が含まれており、この情報を学習して返答を生成したわけです。

もちろん、データセットの中に含まれていない情報を正しく答えることはできません。試しにGIGAZINEについて説明をお願いしたところ、「音楽についての月刊デジタル雑誌」と返事が返ってきました。

・関連記事
大規模言語モデルの開発者が知っておくと役立つさまざまな数字 - GIGAZINE
画像生成AI「Stable Diffusion」を数枚の画像でファインチューニングする「Textual Inversion」のメリットとデメリットを実例と共に解説 - GIGAZINE
OpenAI開発のテキスト生成AI「GPT-3」がどんな処理を行っているのかを専門家が解説 - GIGAZINE
対話型チャットAIのベンチマーク番付で1位はGPT-4ベースのChatGPTで2位はClaude-v1、GoogleのPaLM 2もトップ10にランクイン - GIGAZINE
ChatGPTなどに使われる大規模言語モデルを従来のシステムよりも15倍高速・低コストで学習できる「DeepSpeed-Chat」をMicrosoftが公開 - GIGAZINE
・関連コンテンツ



in ソフトウェア, ネットサービス, レビュー, Posted by log1d_ts
You can read the machine translated English article I tried using the library ``Lit-Parrot&#….