




大規模言語モデルの開発者が知っておくと役立つさまざまな数字

Googleの人工知能部門の責任者を務めるスゴ腕エンジニアのジェフ・ディーンがかつて作成した「すべてのエンジニアが知っておくべき数字」に習って、「大規模言語モデル(LLM)の開発者が知っておくべき数字」が元Googleのエンジニアだったワリード・カドスさんによってまとめられています。
ray-project/llm-numbers: Numbers every LLM developer should know
https://github.com/ray-project/llm-numbers
◆プロンプト編

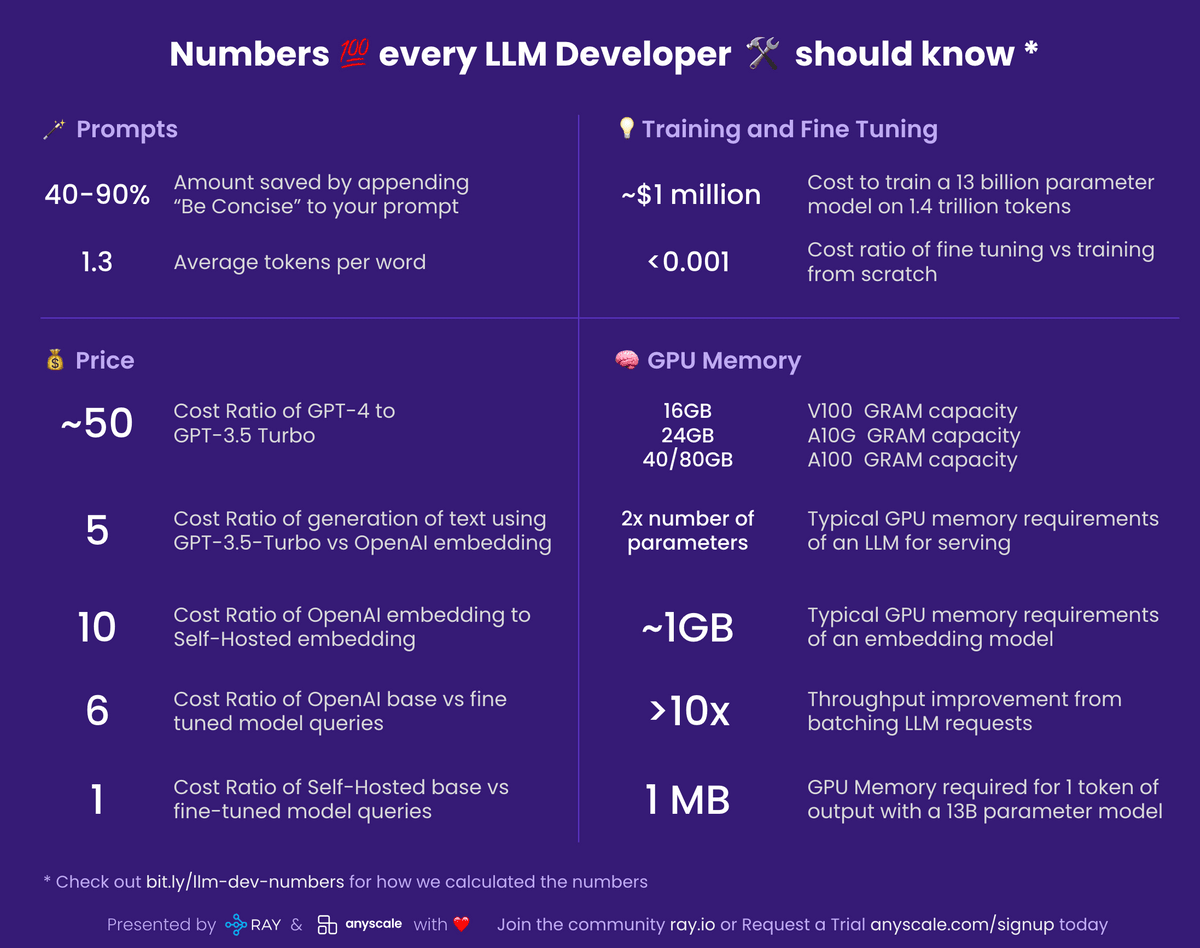
40-90%:プロンプトに「簡潔に」を追加することで節約できる量
LLMの返答はトークン単位で課金されるため、LLMに簡潔に返答するよう要求すると大幅にコストを削減可能です。単にプロンプトに「簡潔に」を追加するだけでなく、例えば10個の案を出すというプロンプトを行う時に代わりに5個を指定するとコストを半額にできます。
1.3:単語あたりの平均トークン数
LLMはトークンで動作します。トークンとは単語または単語のサブパーツのことで、例えば、「eating(食べる)」は「eat」と「ing」という2つのトークンに分けられる場合があります。750単語で構成される英文の場合、約1000トークンに分解されることになります。英語以外の言語の場合、LLMの埋め込みコーパス内の共通性に応じて、単語あたりのトークンが増加します。ほとんどの請求はトークン単位で行われ、LLMのコンテキストウィンドウサイズもトークンで定義されるため、この比率を知ることは重要です。
なお、日本語の場合は1文字あたり約1.1トークンになるとのこと。
◆価格編

もちろん価格は変更される可能性がありますが、LLMの運営コストがいかに高いかを考えると、このセクションの数値は重要です。ここでは数値にOpenAIのものを使用していますが、AnthropicやCohereなど他のプロバイダーの価格もほぼ同じです。
50倍:GPT-4とGPT-3.5 Turboのコスト比
多くの実用的なアプリケーションでは、GPT-4を使用してデータを生成し、生成したデータを使用して小規模なモデルを微調整する方がはるかに優れているということです。GPT-3.5-Turboを使用すると、そのコストはGPT-4のおよそ50分の1に抑えられます。そのため、GPT-3.5-Turboの性能でどんなことができるのかを実際に確認する必要があります。たとえば要約などのタスクであればGPT-3.5-Turboで十分です。
5倍:GPT-3.5-Turbo とOpenAI embeddingを使用したテキスト生成のコスト比
これは、LLMに生成を依頼するよりも、ベクターストアにデータを保存して検索する方がはるかに安価であることを意味します。例:「デラウェア州の首都はどこですか?」とニューラルエンジン検索システムで検索すると、GPT-3.5-Turboに依頼した場合よりもコストが約5分の1に抑えられます。GPT-4と比較すると、そのコストはなんと250分の1です。
10倍:OpenAI embeddingとセルフホスト型embeddingのコスト比率
カドスさんの調査では、1時間あたり1.20ドル(約165円)で利用可能なg4dn.4xlargeを使用すると、OpenAIのembeddingと同等の性能を持つHuggingFaceのSentenceTransformersにて1秒あたり約9000トークンのペースでembeddingを行うことができたと述べました。レートとノードタイプについて基本的な計算を行うと、自己ホスト型埋め込みの方が約10倍安いことがわかります。ただし、この数値は負荷と埋め込みバッチサイズに影響されるため、おおよその値だとのこと。
6倍:OpenAIの基本モデルとファインチューニングされたモデルのクエリのコスト比
ファインチューニングされたモデルを利用するには、OpenAIの基本モデルの場合と比べて6倍の費用がかかります。これはかなり法外な金額ですが、基本モデルはおそらくマルチテナンシーが行われているため大きな差が付いてしまっている可能性があるとのこと。これはモデルをファインチューニングするよりも基本モデルのプロンプトを調整する方がはるかにコスト効率が高いことも意味します。
1倍:セルフホストベースのクエリとファインチューニングされたモデルのクエリのコスト比
モデルを自己ホストしている場合、ファインチューニングされたモデルを提供する場合も、基本モデルを提供する場合とほぼ同じコストがかかります。モデルのパラメーターの数は同じです。
◆トレーニングとファインチューニング編

約100万ドル(約1億3700万円):1兆4000億個のトークンで130億パラメータのモデルをトレーニングするコスト
LLaMaの論文には、2048個のA100 80GB GPUを使用してLLaMaをトレーニングするのに21日かかったことが記載されています。そこで、Red Pajamaトレーニングセットで独自のモデルをトレーニングすると仮定して数値を計算しました。上記は、すべてが正常に進み、何もクラッシュせず、計算が初回に成功することを前提としています。さらに、2048個のGPUを連携させることが必要です。それは、ほとんどの企業ができることではありません。独自のLLMをトレーニングすることは可能ですが、費用は安くないということです。そして、各実行を完了するには文字通り何日もかかります。事前トレーニングされたモデルを使用する方がはるかに安価です。
0.001以下:ファインチューニングとゼロからのトレーニングのコスト比
これは少し一般論ですが、ファインチューニングにかかるコストは無視できます。たとえば、60億パラメータモデルであれば約7ドルでファインチューニング可能です。OpenAIの最も高価なファインチューニング可能なモデルであるDavinciのレートでも、1000トークンあたり3セント(約4円)です。つまり、シェイクスピアの作品全体(約100万語)をファインチューニングするには、40ドル(約5500円)かかることになります。
◆GPUメモリ編

モデルを自己ホストしている場合、LLMはGPUのメモリを限界まで利用するため、GPUメモリを理解することが非常に重要です。以下の統計は、特に推論に関するものです。トレーニングやファインチューニングにはかなり多くのメモリが必要です。
V100:16GB、A10G:24GB、A100:40/80GB
さまざまな種類のGPUが搭載するメモリの量を知ることが重要です。これにより、LLMが持つことができるパラメータの数が制限されます。一般に、A10GはAWSオンデマンド価格で1時間あたり1.50~2ドル(約200~280円)で利用でき、24GBのGPUメモリを搭載しているため、カドスさんはA10Gを使用するのが好きとのこと。一方、A100はAWSオンデマンド価格で1時間あたり約5ドル(約690円)かかります。
パラメータ数の2倍:サービスを提供するためのLLMの一般的なGPUメモリ要件
たとえば、70億パラメータのモデルがある場合、約14GBのGPUスペースが必要になります。これは、ほとんどの場合、パラメーターごとに1つの16ビット浮動小数点、つまり2バイトが必要になるためです。通常、16ビット精度を超える必要はありませんが、ほとんどの場合、8ビット精度にすると解像度が低下し始めます。もちろん、精度を削減する取り組みも存在しており、特にllama.cppは、積極的に4ビットまで量子化することで6GB GPUで130億パラメータのモデルを実行しますが、これは一般的ではありません。
約1GB:埋め込みモデルの一般的なGPUメモリ要件
クラスタリング、セマンティック検索、および分類タスクでよく行われる一般的な操作である文の埋め込みを行うときは常に、センテンストランスフォーマーのような埋め込みモデルが必要です。OpenAIには、商用提供される独自の埋め込み機能もあります。
通常、埋め込みメモリはかなり小さいため、GPU上でどれだけの量を占めるかについて心配する必要はありません。カドスさんはembeddingとLLMを同じGPU上に配置したこともあると述べています。
10倍以上:LLMリクエストのバッチ処理によるスループットの向上
GPUを介してLLMクエリを実行すると遅延が非常に長くなりますが、バッチにまとめることで遅延を減らすことが可能です。たとえば、1つのタスクに5秒かかり、1秒あたり0.2クエリのスループットとなる場合を考えてみます。2つのタスクをバッチにまとめて実行した場合、所要時間は5.2秒のようになり、25個のクエリをバッチにまとめることができる場合、所要時間は約10秒でスループットは1秒あたり2.5クエリに向上します。ただし、以下で述べるGPUメモリの制限に注意が必要です。
約1MB:13Bパラメーターモデルの出力の1トークンに必要なGPUメモリ
必要なメモリの量は、生成するトークンの最大数に正比例します。したがって、例えば最大512トークンの出力を生成したい場合、メモリは512MB必要になります。24GBのメモリを利用している場合、512MBは大したことのない量に見えますが、バッチ処理を行う場合はバッチの量だけ必要量が加算されていきます。例えば16個のタスクをバッチにまとめる場合はメモリを512MB×16タスク=8GBも必要とするわけです。
・関連記事
人は「細かい数字」より「大体の数字」を高く評価する - GIGAZINE
古代ローマ人が編み出した「両手の指だけを使って0~9999までの数字をカウントする方法」とは? - GIGAZINE
なぜ人は「$9.99」のような端数の価格に引き寄せられてしまうのか? - GIGAZINE
データに関してぜひとも知っておきたい基礎知識が一発で分かるムービー - GIGAZINE
Google検索を使って必要な情報を正しく検索するために役立つ10のテクニック - GIGAZINE
・関連コンテンツ





in ソフトウェア, Posted by log1d_ts
You can read the machine translated English article Various Numbers Good to Know for Develop….