Google develops 'SpecAugment' that enables high-accuracy automatic speech recognition without using language models

by
Google, which is at the forefront of machine learning and artificial intelligence (AI), is researching automatic speech recognition technology that automatically recognizes speech and converts it into text like Cloud Speech-to-Text . Google AI researchers have announced that they have developed ' SpecAugment ', a technology that improves the performance of state-of-the-art automatic speech recognition models without using language models .
[1904.08779] SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition
https://arxiv.org/abs/1904.08779
Google AI Blog: SpecAugment: A New Data Augmentation Method for Automatic Speech Recognition
https://ai.googleblog.com/2020/04/specaugment-new-data-augmentation.html
Google's SpecAugment achieves state-of-the-art speech recognition without a language model | VentureBeat
https://venturebeat.com/2019/04/22/googles-specaugment-achieves-state-of-the-art-speech-recognition-without-a-language-model/
A language model is a mathematical expression of the relationship between words in a language. It is possible to convert speech that is only sound if it was originally, into meaningful sentences by learning 'what kind of word comes to a word string'. Therefore, AIs that enable automatic speech recognition need to be trained based on language models.
Meanwhile, SpecAugment, released on the official blog by a research team led by Google AI's researchers William Chan and Daniel Park, has made automatic speech more accurate than conventional methods without the help of language models. It seems that it is a technology that can build a recognition model.
Traditional automatic speech recognition models convert speech data into visual representations in the form of spectrograms and then input them into a network model. The recognition process is performed by a spectrogram, but the data to be prepared itself requires a large amount of audio data, and the calculation cost is enormous.
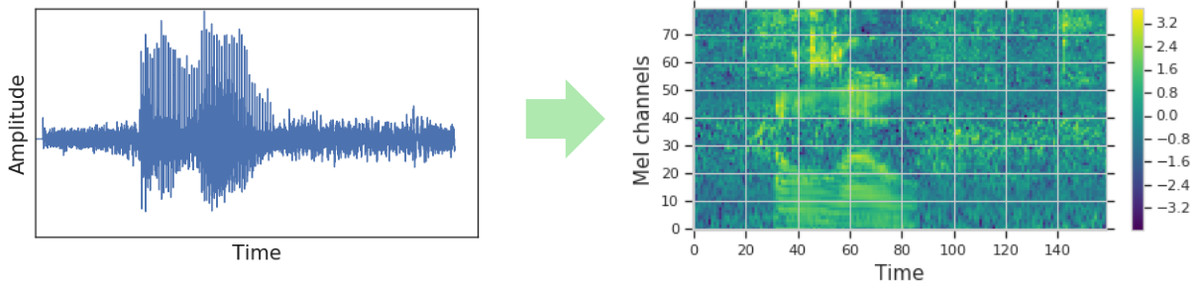
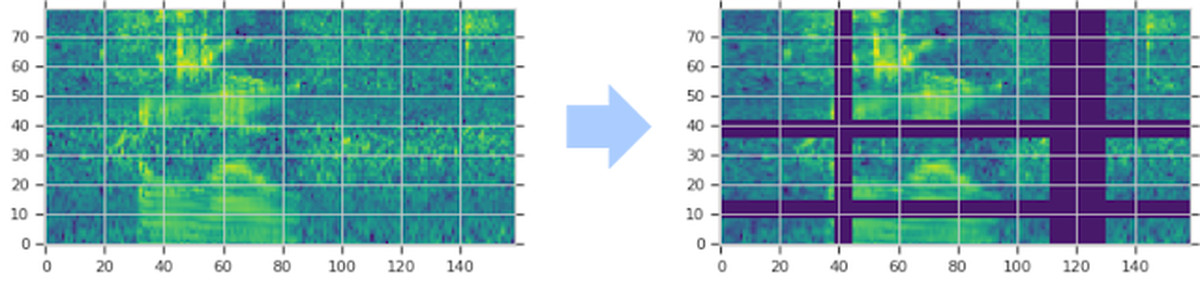
SpecAugment is to edit the spectrogram data directly and mask it to enhance the spectrogram data. By using this SpecAugment, it is possible to prevent over-learning of the model, and it has become possible to perform speech recognition with higher accuracy than the conventional model without the support of the language model.
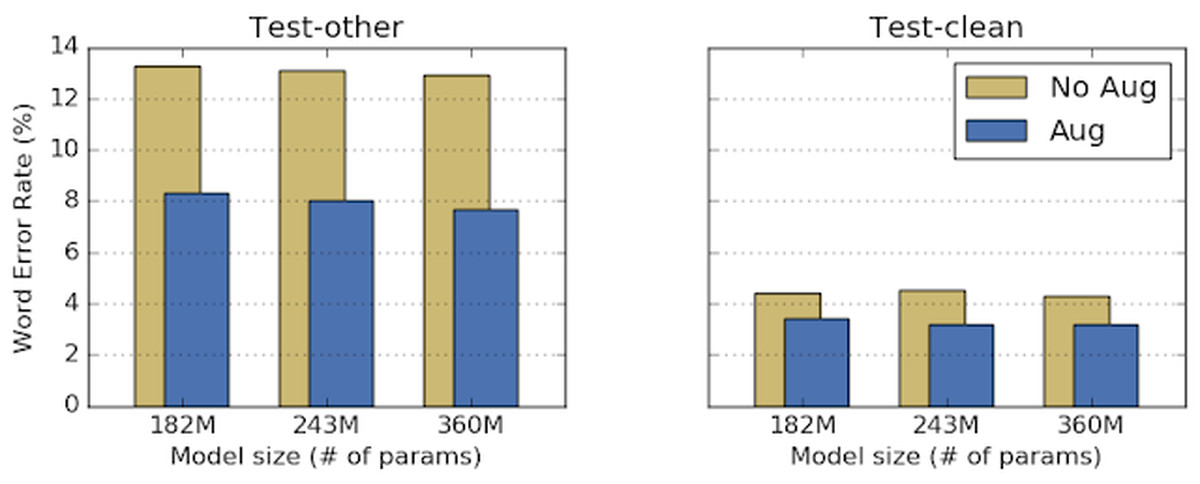
The graph below compares the accuracy of noisy speech on the left and low noise on the right. The false recognition rate of the conventional automatic speech recognition model (yellow) is about 12 to 14% for noisy speech and about 4 to 5% for noisy speech. On the other hand, in the case of an automatic speech recognition model (blue) using SpecAugment, the misrecognition rate clearly decreases and the accuracy is improved, such as about 8% for noisy speech and about 3% for noisy speech I understand this.
The automatic speech recognition model supported by these technologies is used in situations such as converting conversational AI speech into text, such as that used in dictation mode for emails and being installed in smart speakers. In addition, by reducing the false recognition rate, it can be expected that voice input will be faster than actually moving and typing a finger.
Related Posts: