A method called ``StreamingLLM'' that allows large-scale language models to accept ``infinite input'' is developed.

A paper on `` StreamingLLM '', a large-scale language model method that can process infinite input while maintaining computational cost and performance, was published on September 29, 2023. As the input gets longer, the information at the beginning is lost, so it is not suitable for tasks such as book summaries, but it is possible to respond smoothly while maintaining performance even when the dialogue becomes long. It has become.
mit-han-lab/streaming-llm: Efficient Streaming Language Models with Attention Sinks
[2309.17453] Efficient Streaming Language Models with Attention Sinks
https://arxiv.org/abs/2309.17453
A movie is available that shows how StreamingLLM changes the behavior of large-scale language models.
Demo movie of ``StreamingLLM'', a method that allows large-scale language models to accept ``infinite input'' - YouTube
Both have the same behavior when loading a model.
We prepare a large number of questions and repeat the process ``Question → Answer by AI → Question → Answer by AI →...''.
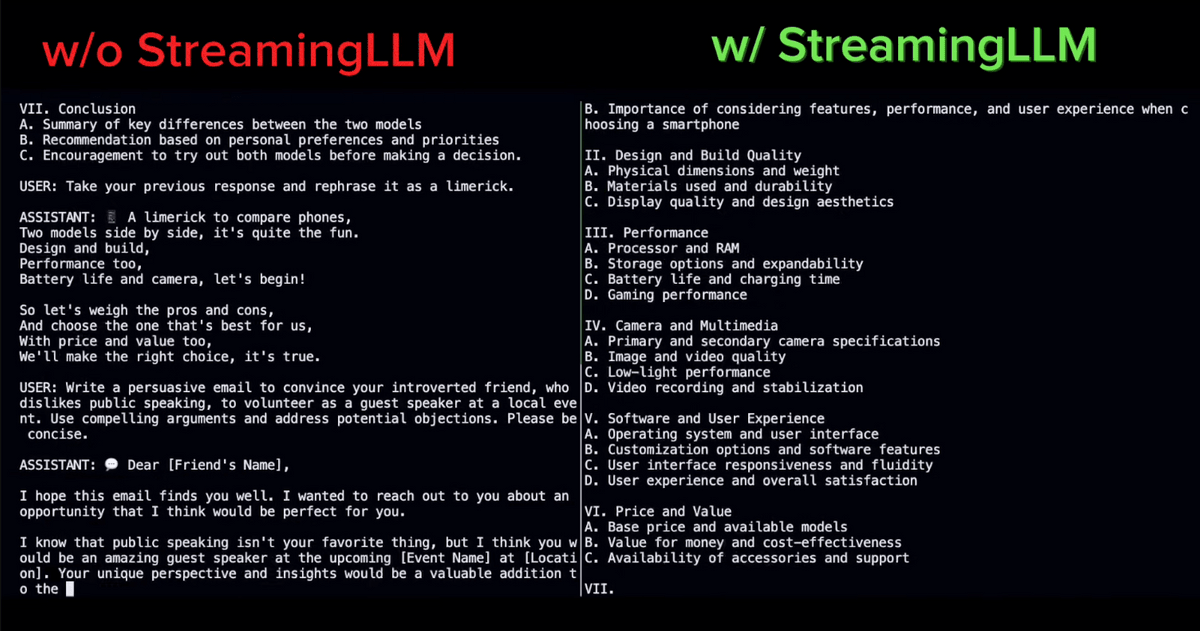
After continuing for a while, the answers for models that did not use StreamingLLM became incoherent. On the other hand, the model using StreamingLLM is successfully responding.

After that, the model that did not use StreamingLLM ran out of memory and stopped, but the model that used StreamingLLM continued to run.

A comparison image with existing methods is shown below. Along with operational images of the four methods, the time complexity of the algorithm is displayed in O-notation and the PPL value, which indicates prediction accuracy, is displayed. L is the length of the pre-trained text, and T is the number of tokens to predict.
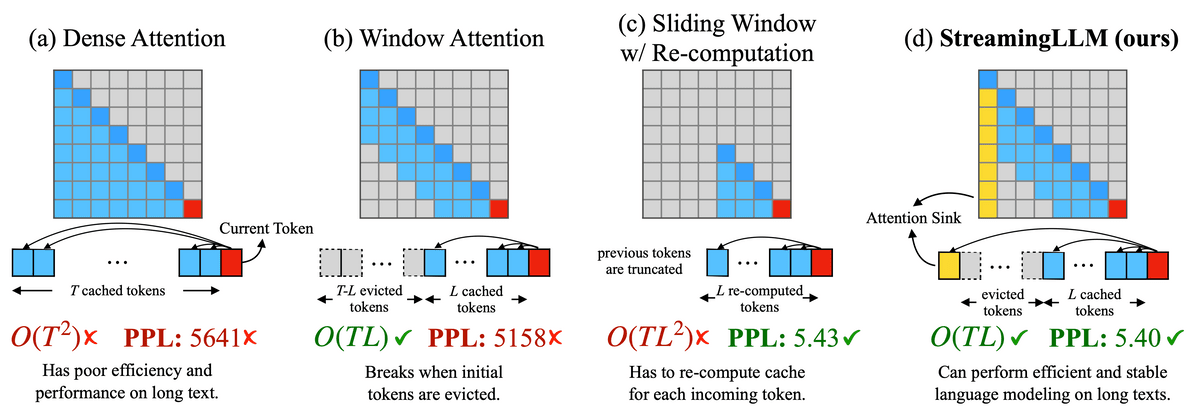
Dense Attention in (a) not only requires the time complexity of T squared, but also consumes a large amount of memory. Additionally, if the length of the text exceeds the length of the pre-trained text, performance will drop significantly.
Window Attention in (b) is a mechanism that only holds the cache for the nearest L tokens, and although the time complexity was suppressed, performance suddenly deteriorated when the first token went out of the cache range.
(c) Sliding Window w/ Re-computation is a mechanism that updates the cache for the nearest L tokens for each token. Although it is possible to maintain prediction accuracy even with long sentences, the amount of calculation will increase.
(d) StreamingLLM is the mechanism developed this time. The authors of the paper discovered a phenomenon in which performance can be recovered by retaining the cache of the first token in (b) Window Attention, and incorporated it into the attention calculation, giving it the name 'attention sink.' It is said that it can demonstrate good performance on long sentences while maintaining the time complexity of Window Attention.
By incorporating StreamingLLM, large-scale language models such as ' Llama-2 ', ' MPT ', ' Falcon ', and ' Pythia ' can handle sentences with a length of more than 4 million tokens. In addition, it was confirmed that further speed improvements were confirmed by preparing a placeholder token as an attention sink during pre-learning.
Although it is now possible to input long sentences, the context length limit remains unchanged. For example, if Llama-2 is pre-trained with a context length of 4096 tokens, the maximum cache size will remain 4096 tokens even when using StreamingLLM, and the missing part will be handled by discarding intermediate tokens.
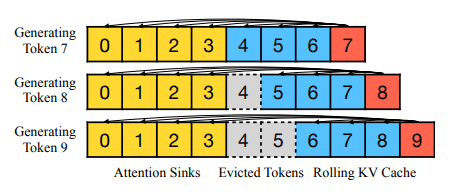
StreamingLLM is not a mechanism to strengthen long-term memory, so when doing a task of summarizing a long text such as a book, it is likely that only the last part will be summarized. On the other hand, it is a suitable method when you want to run the model continuously without needing past data, such as for daily assistants. It can continue working even if the conversation length exceeds the context length.
The code that actually incorporates StreamingLLM into a large-scale language model is published on GitHub , so if you are interested, please check it out.
Related Posts:






