Japan-based AI company 'Sakana AI' develops 'NAMM' technology that reduces cache memory usage by up to 75%

Sakana AI has published a paper titled 'Advanced Universal Transformer Memory.' According to the paper, by introducing a new mechanism called the Neural Attention Memory Model (NAMM), it is possible to reduce redundant information in the context and improve memory efficiency during inference.
An Evolved Universal Transformer Memory
https://sakana.ai/namm/
[2410.13166] An Evolved Universal Transformer Memory
https://arxiv.org/abs/2410.13166
Large-scale language models (LLMs), the core of AI, receive prompts from users as context and generate new responses. Current mainstream models can receive very long contexts of hundreds of thousands to millions of tokens, but there are problems with the computational costs and performance degradation depending on the length of the context.
Sakana AI developed NAMM as a simple neural network that decides whether to 'remember' or 'forget' each token stored in the LLM's memory. By actively 'forgetting' redundant parts of the prompts while retaining the important parts, Sakana AI succeeded in improving both efficiency and performance at the same time.
NAMM can be easily introduced because it can be trained separately from the model itself, but it can only be applied to open source models because it requires access to the inside of the model. In addition, it is said that the training is based on evolutionary algorithms rather than gradients.
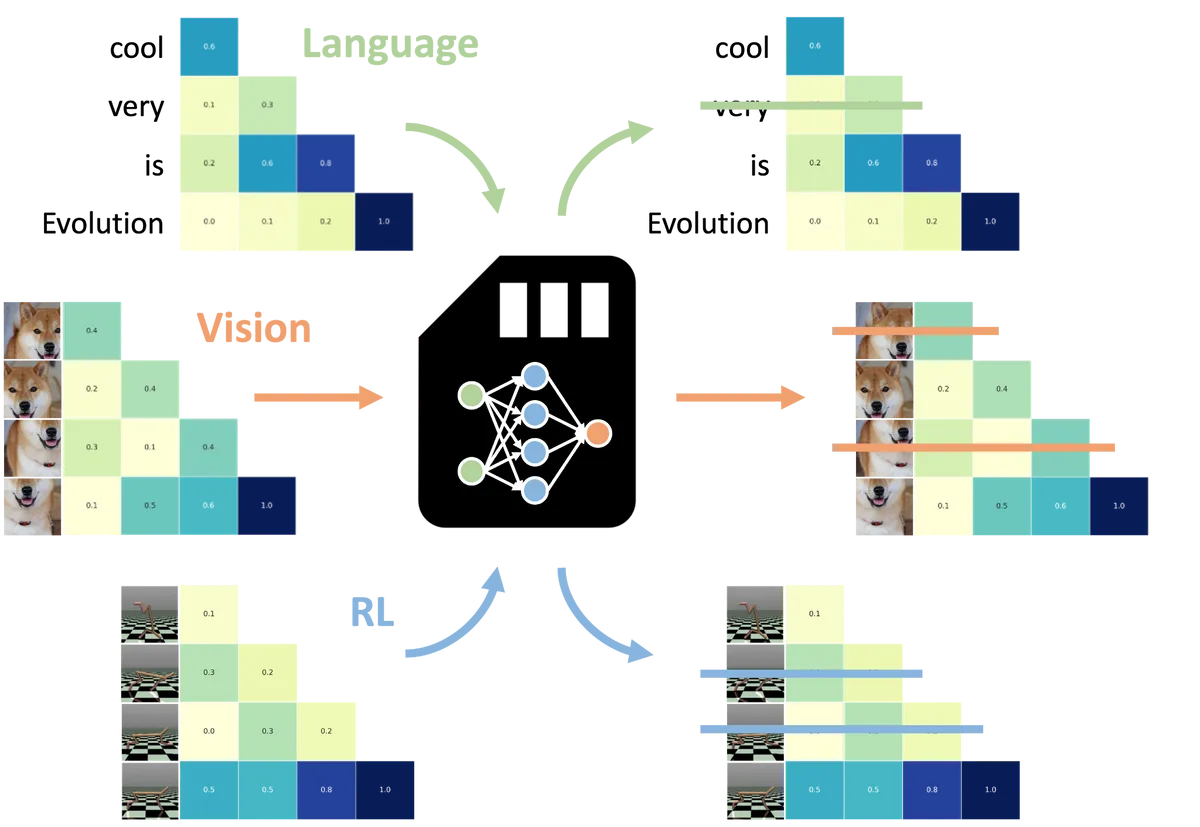
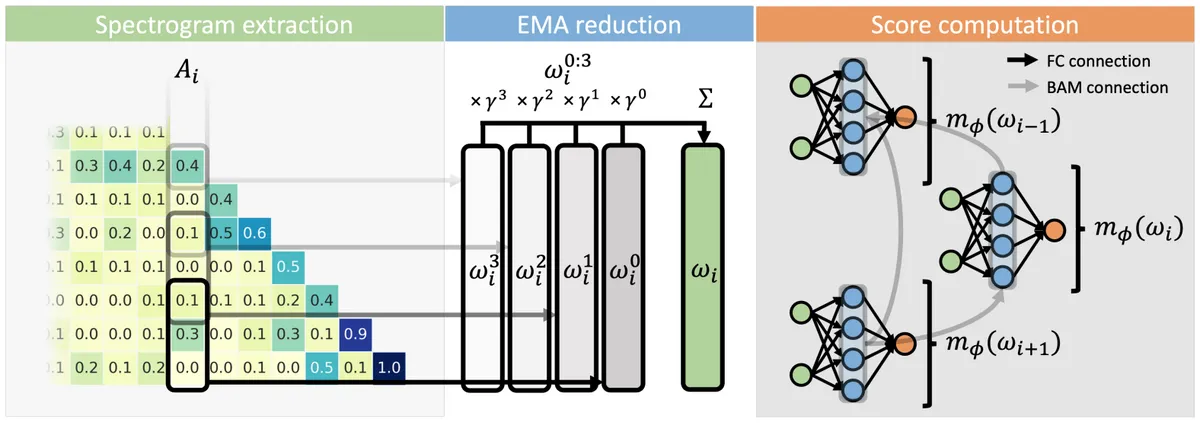
NAMM operates in the attention layer and chooses whether to keep or discard tokens in a context window depending on the attention value. By adopting an attention-based mechanism, it is possible to use a trained NAMM in another model.
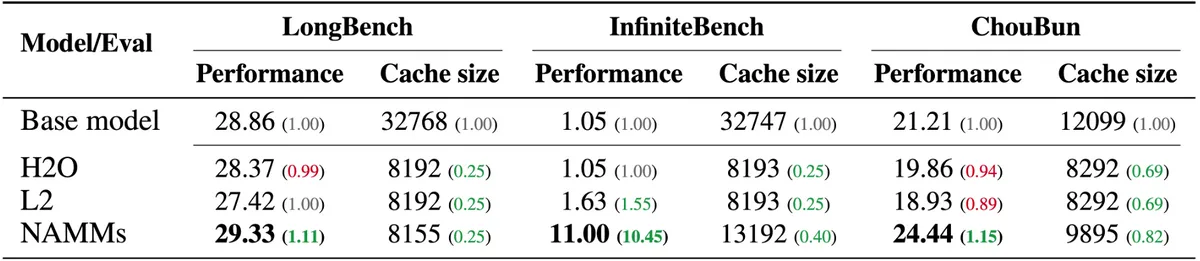
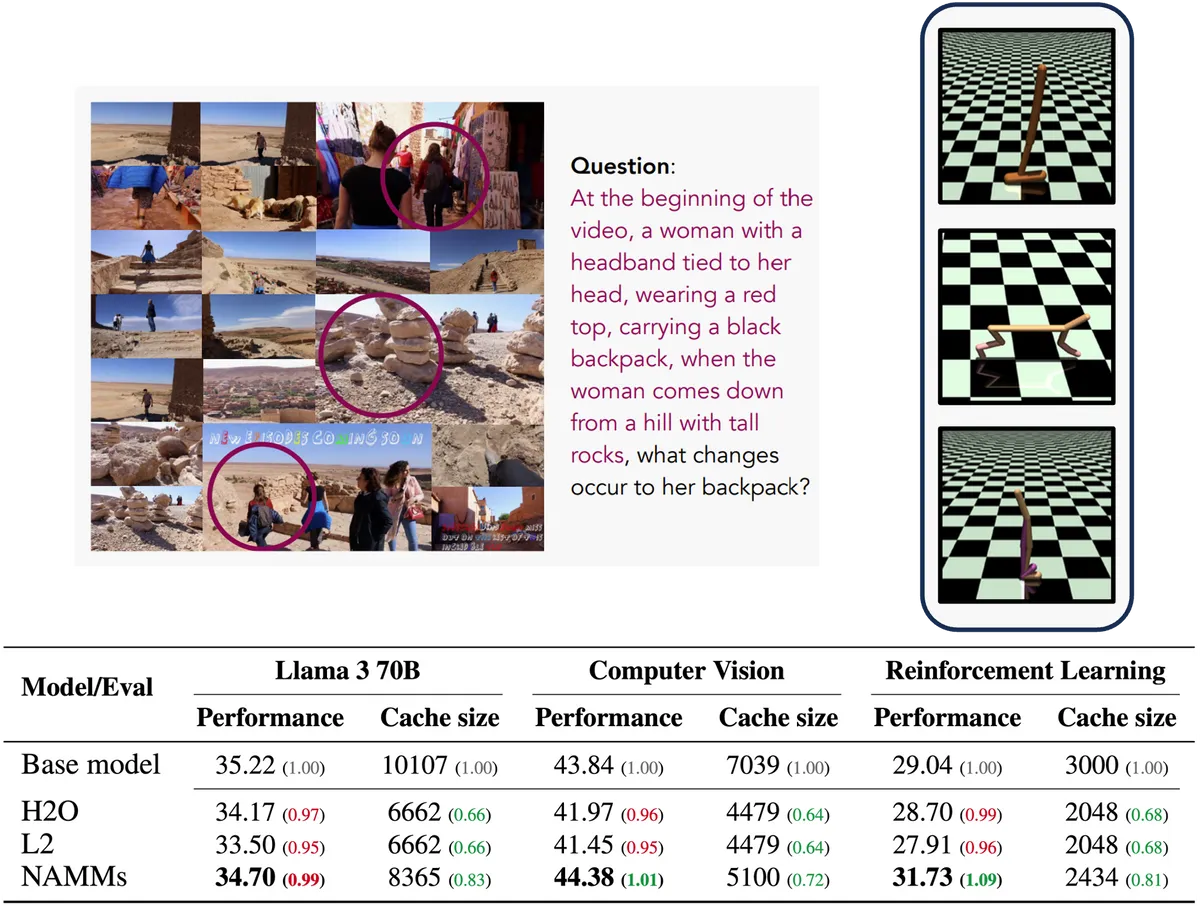
Sakana AI was trained and benchmarked on the Llama 3 8B model for NAMM and demonstrated that it reduces the cache memory required to execute tasks by up to 75%, while significantly outperforming other memory reduction techniques such as H2O and L2.
Even when NAMM was trained on text-only data, we were able to get it to work well on multimodal models that handle images and video without any tuning, and we were able to confirm that it worked well, for example by removing redundant video frames.
According to Sakana AI, NAMM varies which tokens to remove depending on the task. For example, for programming tasks, it removes chunks of code, comments, and whitespace, while for natural language tasks, it removes grammatically redundant parts even in the middle of a sentence.
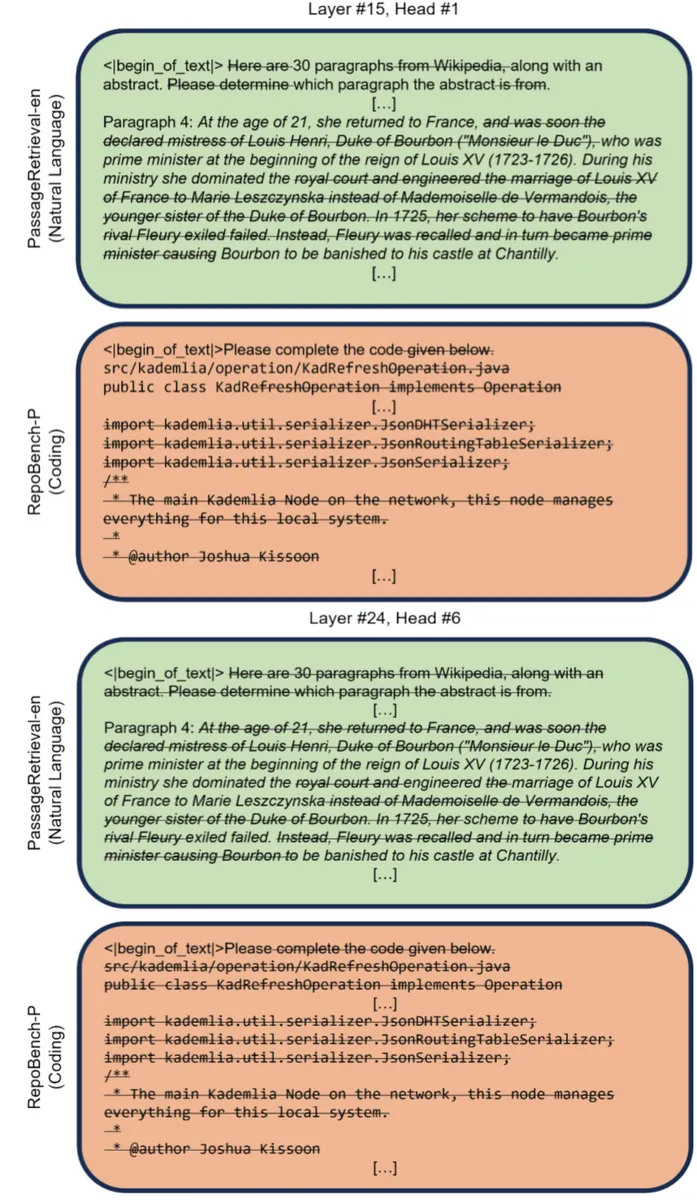
Sakana AI spoke about its future outlook, saying, 'By using NAMM when training models, it may be possible to train even very long data sequences efficiently.'
Related Posts:








in Software, , Posted by log1d_ts