NVIDIA announces next-generation GPU architecture 'Hopper', AI processing speed is 6 times faster than Ampere and various performances are dramatically improved
At the
GTC 2022 Keynote with NVIDIA CEO Jensen Huang --YouTube
NVIDIA Announces Hopper Architecture, the Next Generation of Accelerated Computing | NVIDIA Newsroom
https://nvidianews.nvidia.com/news/nvidia-announces-hopper-architecture-the-next-generation-of-accelerated-computing
NVIDIA Hopper GPU Architecture Accelerates Dynamic Programming Up to 40x Using New DPX Instructions | NVIDIA Blog
https://blogs.nvidia.com/blog/2022/03/22/nvidia-hopper-accelerates-dynamic-programming-using-dpx-instructions/
The announcement of 'Hopper' and 'H100' was made during the keynote speech by Jensen Huang, the company's founder and CEO. At the beginning, CEO Juan emphasized that GPUs are making a significant contribution to AI, which is making dramatic progress in scientific fields such as human genome analysis, DNA 3D structure analysis, climate science, and automatic translation. hand……

The breakthrough that created

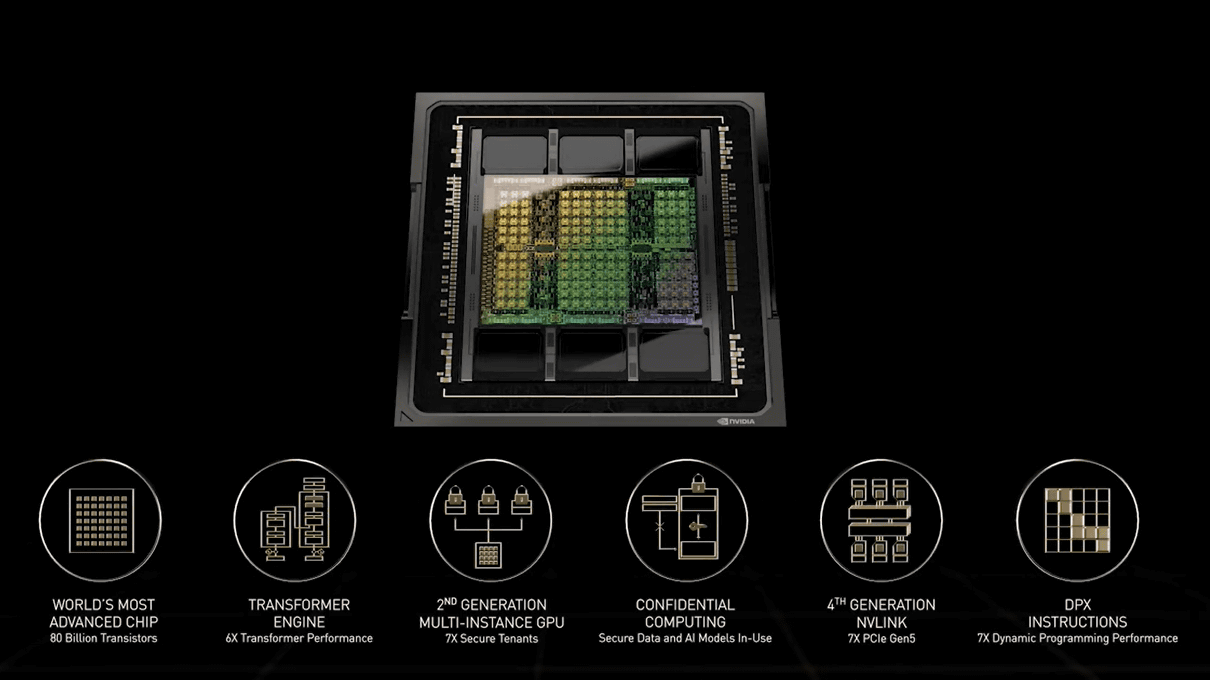
And the existence that makes a big leap in the engine of AI computing infrastructure in the world is the H100 announced this time.

The H100 is equipped with 80 billion TSMC 4-nanometer process transistors, making it the first 5th generation PCI-e GPU and the first HBM3 GPU. It is said that one H100 can maintain an IO bandwidth of 40 terabits / second, so it is a calculation that only 20 H100s can maintain the world's web traffic.

The basis of the H100 is the Hopper, which is the successor to

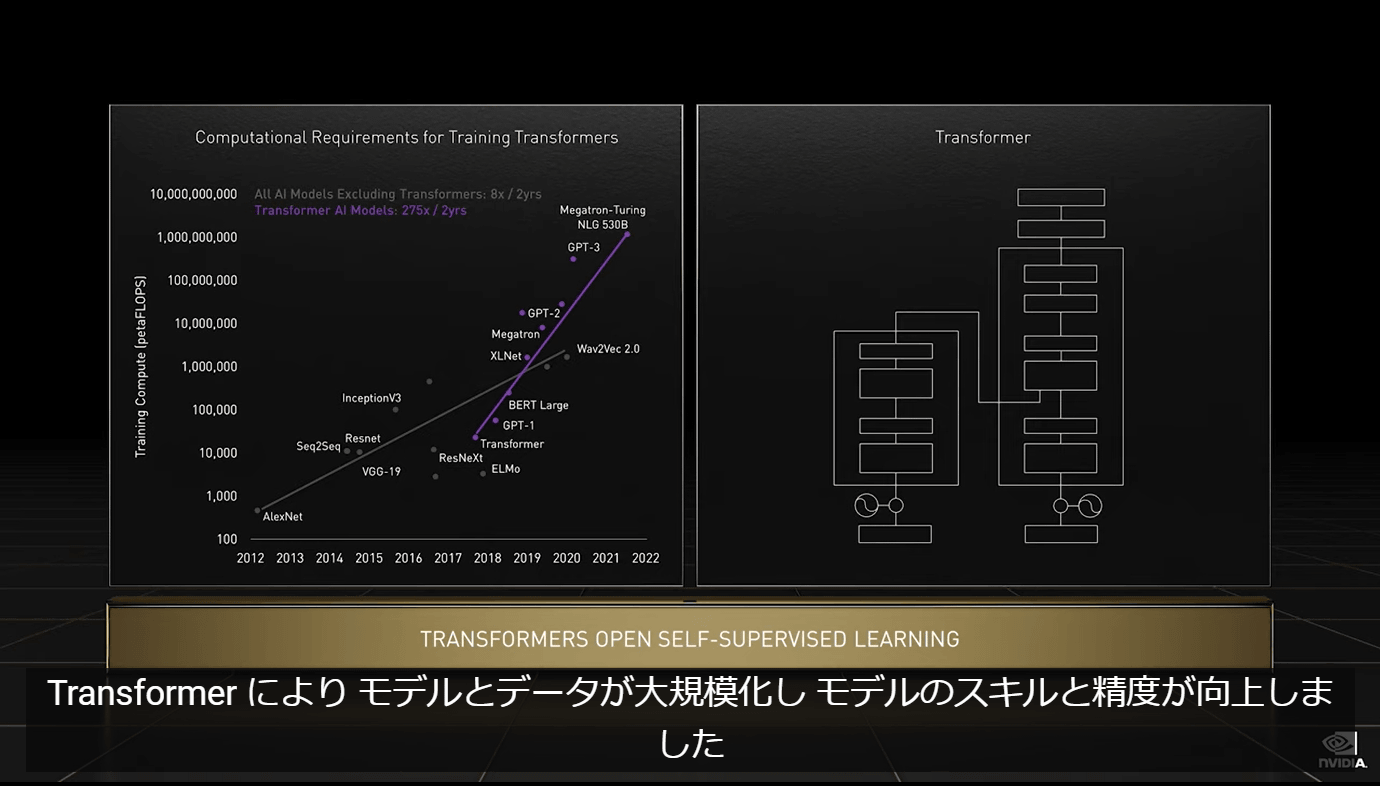
The first is that it is compatible with the new Tensor processing format 'FP8', which has an amazing processing speed of 4 petaFLOPS. The AI processing performed by the Hopper H100's FP8 is 6 times the performance of the Ampere A100's FP16.

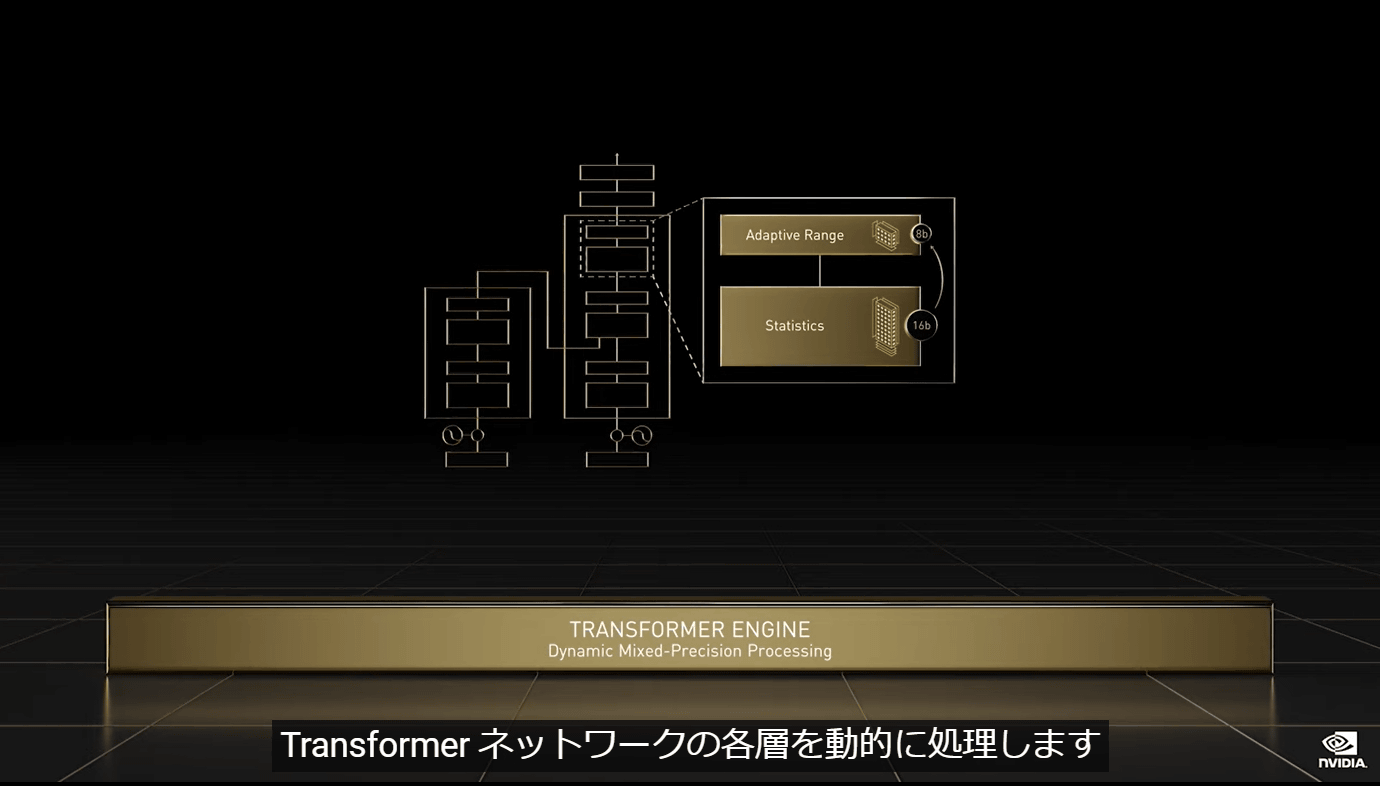
The second point is the introduction of the 'Hopper Transformer Engine' that dynamically processes each layer of the Transformer network.
The third is '2nd generation multi-instance' that supports multi-tenancy in the cloud, which is more advanced than Ampere by completely separating each instance and adding IO virtualization. Regarding multi-tenancy, the H100 is said to be able to host up to 7 cloud tenants equivalent to the 2 currently most popular cloud inference GPUs 'T4 GPUs'.

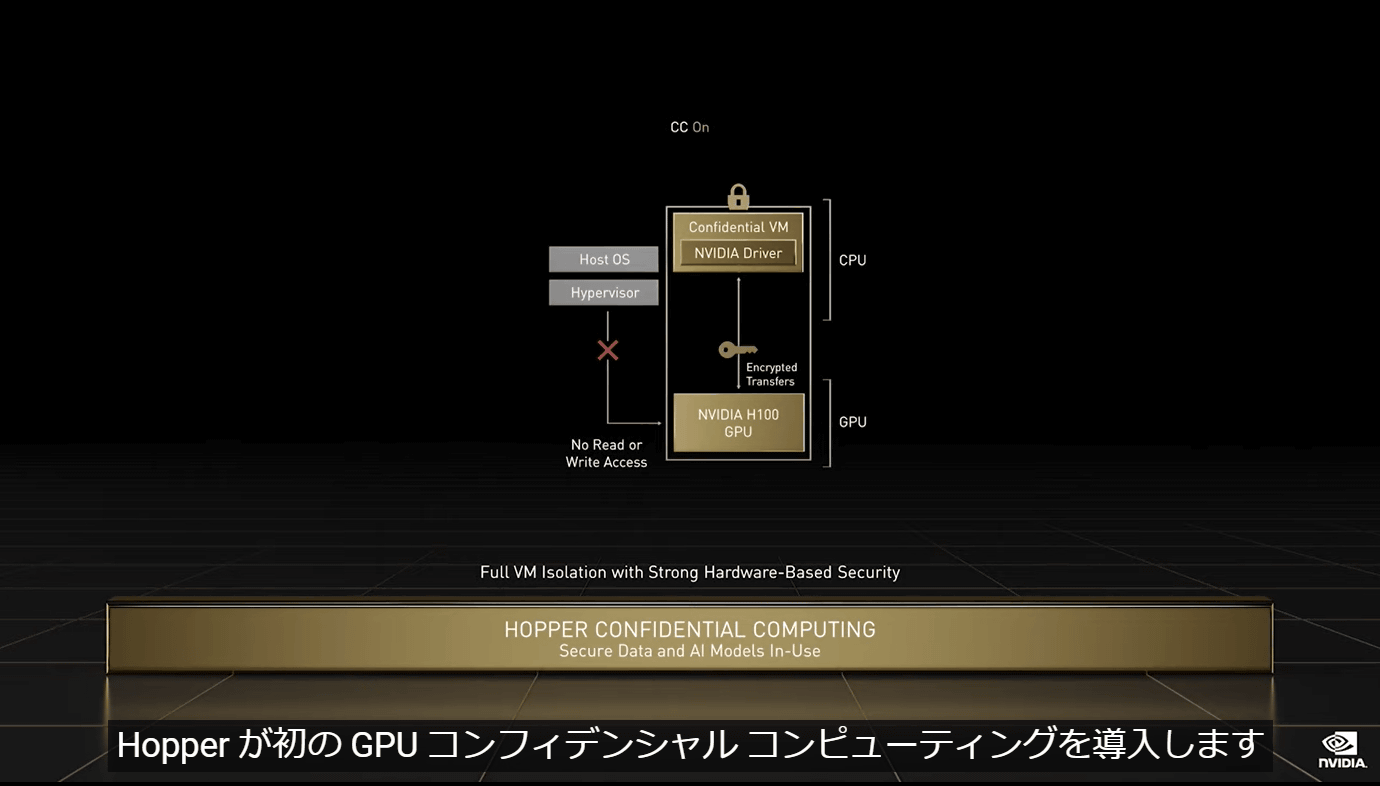
Fourth, 'GPU Confidential Computing' that protects the confidentiality and integrity of AI models and owners' algorithms by providing 'protection of sensitive data in use' that many existing systems do not support. Was introduced.
Fifth is a

Sixth, it is now possible to combine new external NVLink Switches to build a scale-up network that goes beyond servers. It seems that it is now possible to connect up to 256 H100s with a bandwidth of 9 times that of the previous generation using NVIDIA HDR Quantum InfiniBand.

The H100 will be available in the third quarter of 2022. In addition, we will also provide 'DGX H100' equipped with 8 H100s, 'DGX H100 SuperPOD' which connects 32 units of this DGX H100 with NVLink Switch, and 'NVIDIA EOS' which connects 576 units. The AI processing performance of '' is expected to reach 18 Exa Flops, which is four times the performance of 'Tomitake', which boasts the highest performance of supercomputers as of March 2022.

Related Posts:







