AI21 Labs announces 'Jamba', a large-scale language model that uses SSM-Transformer architecture and achieves approximately three times the throughput of conventional models

AI21 Labs, an Israeli AI startup, has announced a large-scale language model called ' Jamba ' that supports English, French, Spanish, and Portuguese. Jamba is an SSM-Transformer model that combines the traditional Transformer model with the State Space Model (SSM) architecture.
Introducing Jamba: AI21's Groundbreaking SSM-Transformer Model
AI21 Labs Unveils Jamba: The First Production-Grade Mamba-Based AI Model
https://www.maginative.com/article/ai21-labs-unveils-jamba-the-first-production-grade-mamba-based-ai-model/
AI21 Labs' new AI model can handle more context than most | TechCrunch
https://techcrunch.com/2024/03/28/ai21-labs-new-text-generating-ai-model-is-more-efficient-than-most/
Jamba is a large-scale language model that can process up to 140K tokens and approximately 105,000 words on a single GPU with at least 80GB of memory. Part of the core model uses the open source model ' Mamba ' developed at Princeton University and Carnegie Mellon University.
A distinctive feature of Jamba is that it adopts the 'SSM-Transformer' architecture, which combines the Transformer architecture with an architecture called the 'State Space Model (SSM)'.
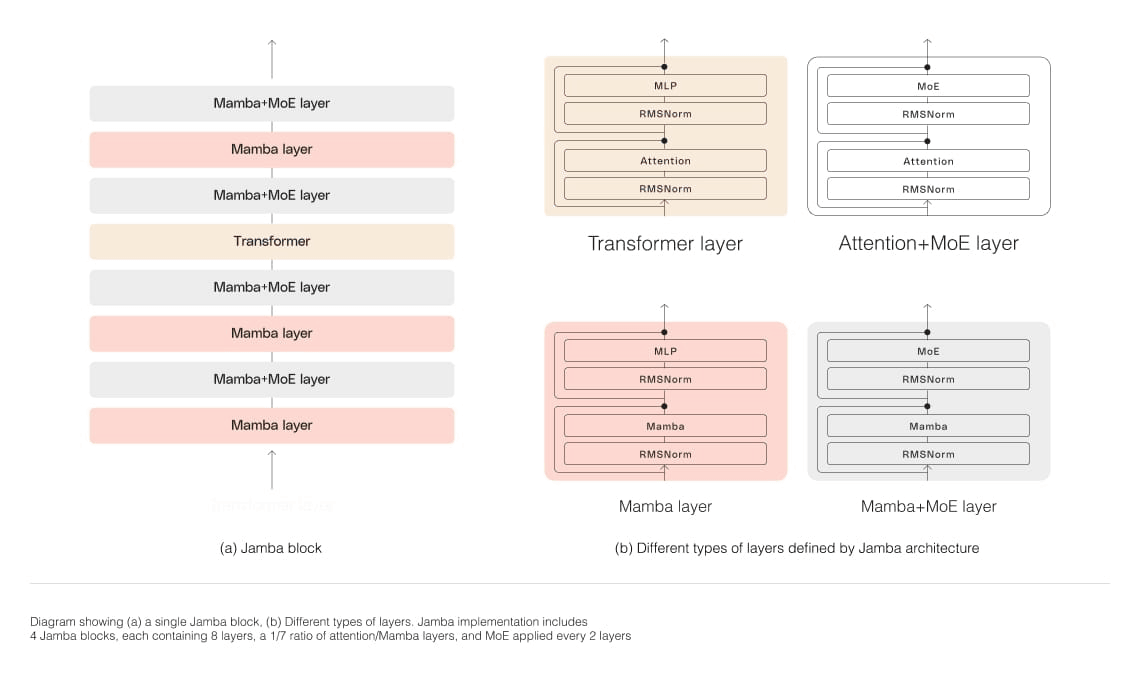
SSM is a type of probabilistic model for dealing with time series data and continuous data, and is computationally more efficient than Transformer, making it suitable for processing long sequences of data. Jamba's SSM-Transformer architecture is a hybrid of SSM and Transformer, and is characterized by its ability to achieve three times the throughput for long contexts compared to the same-sized Transformer model.
In addition to the SSM-Transformer architecture, Jamba also uses a Mixture-of-Experts (MoE) layer. This MoE layer is a technique that combines multiple neural networks to improve the expressiveness and efficiency of the entire model. AI21 Labs reports that by incorporating it into Jamba, it was possible to achieve high performance while using only 12 billion parameters out of the 52 billion available for inference.
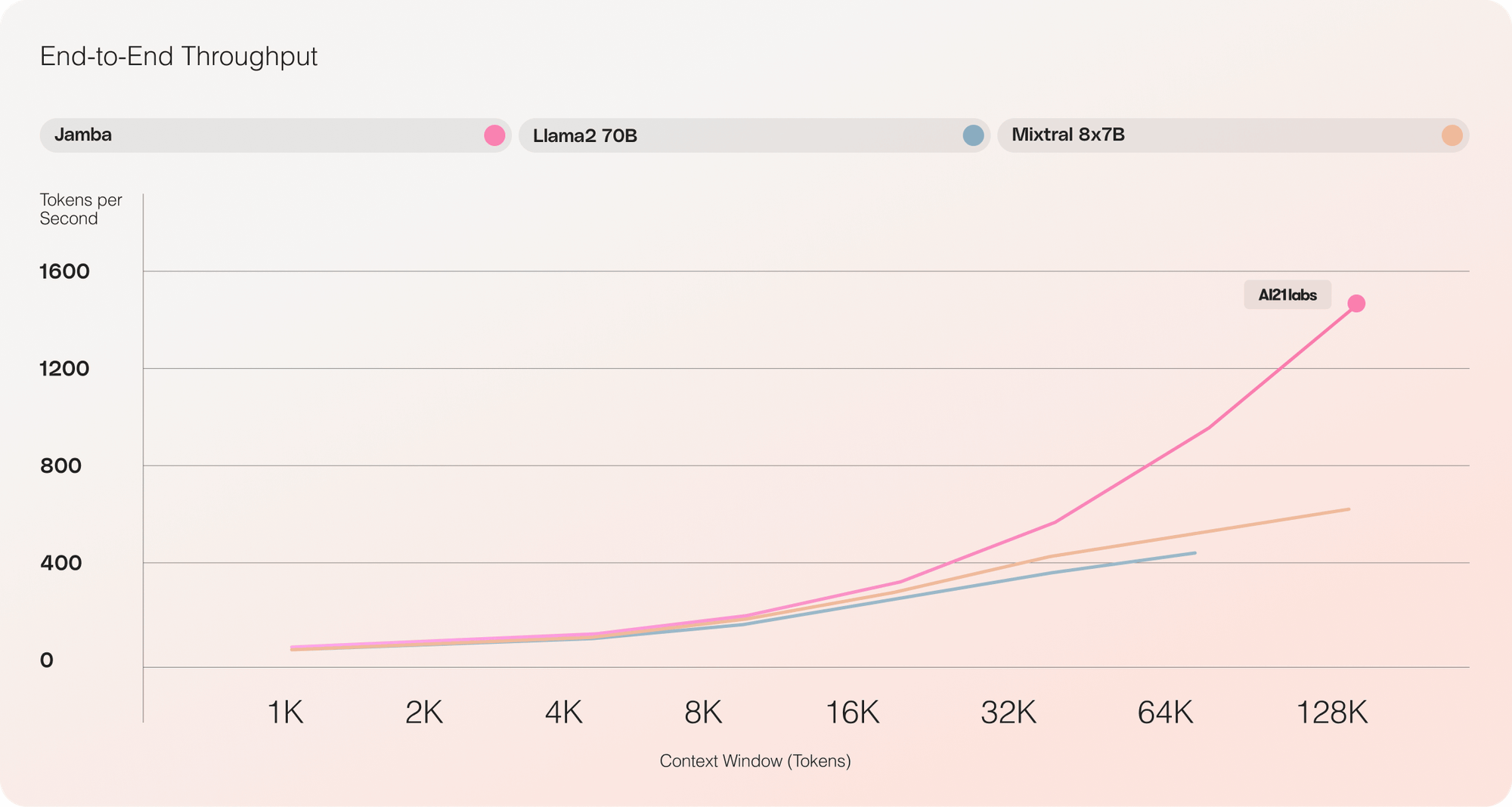
Below is a graph comparing the number of tokens processed per second (throughput) for Jamba (pink),
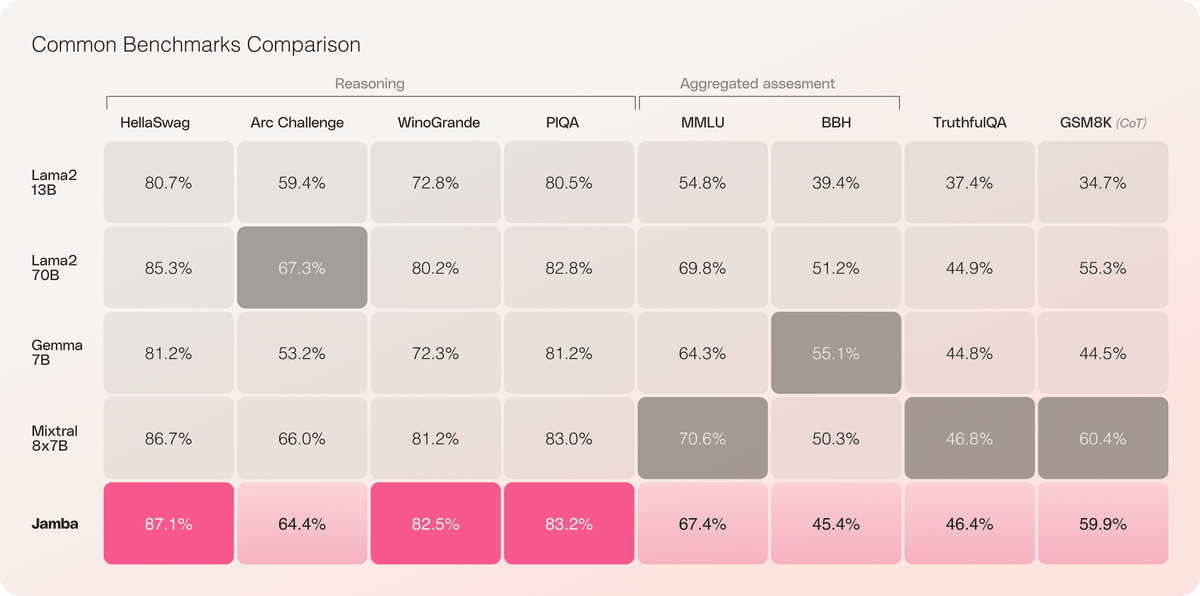
Below is a table measuring the performance of Llama 2-13B, Llama 2-70B,
Jamba is published under the Apache 2.0 license by Hugging Face , and its APIs are accessible to the NVIDIA NIM inference microservices deployed on the NVIDIA AI Enterprise software platform.
At the time of writing, Jamba has been released as a research model that does not have the safeguards necessary for commercial use, but AI21 Labs says it plans to release a tweaked, more secure version by April 2024.
Related Posts:








in Software, Posted by log1i_yk