A small language model 'Zamba2-7B', a hybrid of Transformer and Mamba2, is released

Zyphra, an American AI startup, has released the natural language processing model ' Zamba2-7B '. Zyphra claims that Zamba2-7B outperforms Google's
Zyphra is excited to release Zamba2-7B
https://www.zyphra.com/post/zamba2-7b
Zyphra/Zamba2-7B · Hugging Face
https://huggingface.co/Zyphra/Zamba2-7B
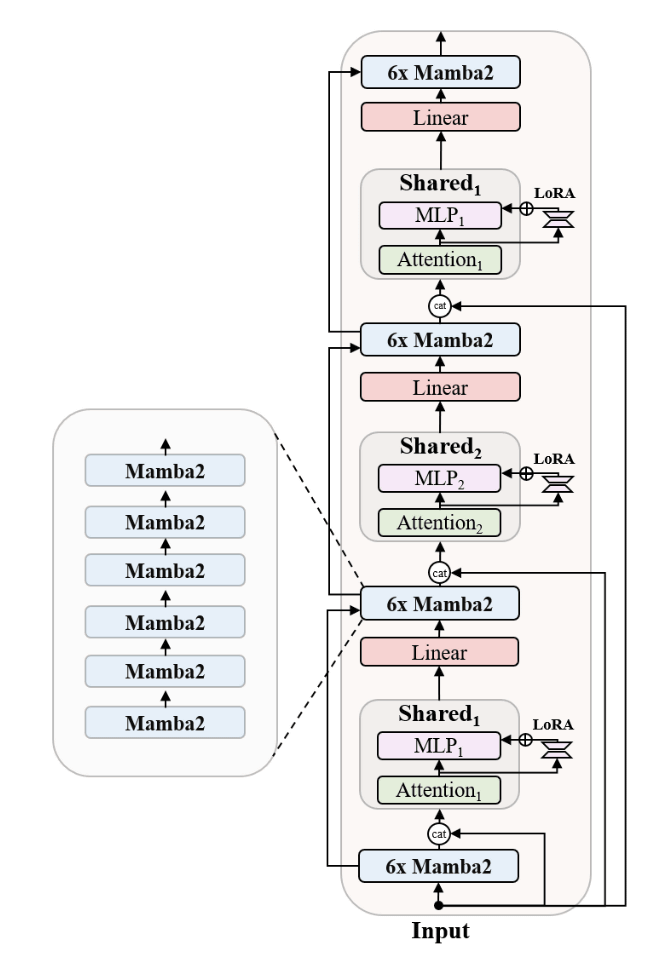
Zamba2-7B is designed with the ' Zamba architecture ,' a hybrid of the Transformer architecture, which is widely used in traditional language models, and the Mamba architecture announced in December 2023.
Zamba2-7B also evolves from its predecessor, Zamba1, by replacing the Mamba1 block with a Mamba2 block and introducing two interleaved shared attention blocks. The 'shared' part means that attention blocks with the same weights are reused in multiple places in the model. Zyphra explains that this shared approach allows the model to leverage the capabilities of the Transformer architecture while keeping the overall parameter count of the model low, balancing model size and performance.
To improve efficiency, we apply LoRA (Low-Rank Adaptation) projectors, which are used for fine-tuning large-scale language models, to each shared Multi-Layer Perceptron (MLP) and attention block, allowing for depth-dependent specialization of the network. We also introduce Rotary Position Embeddings in the shared attention layer to further improve performance.
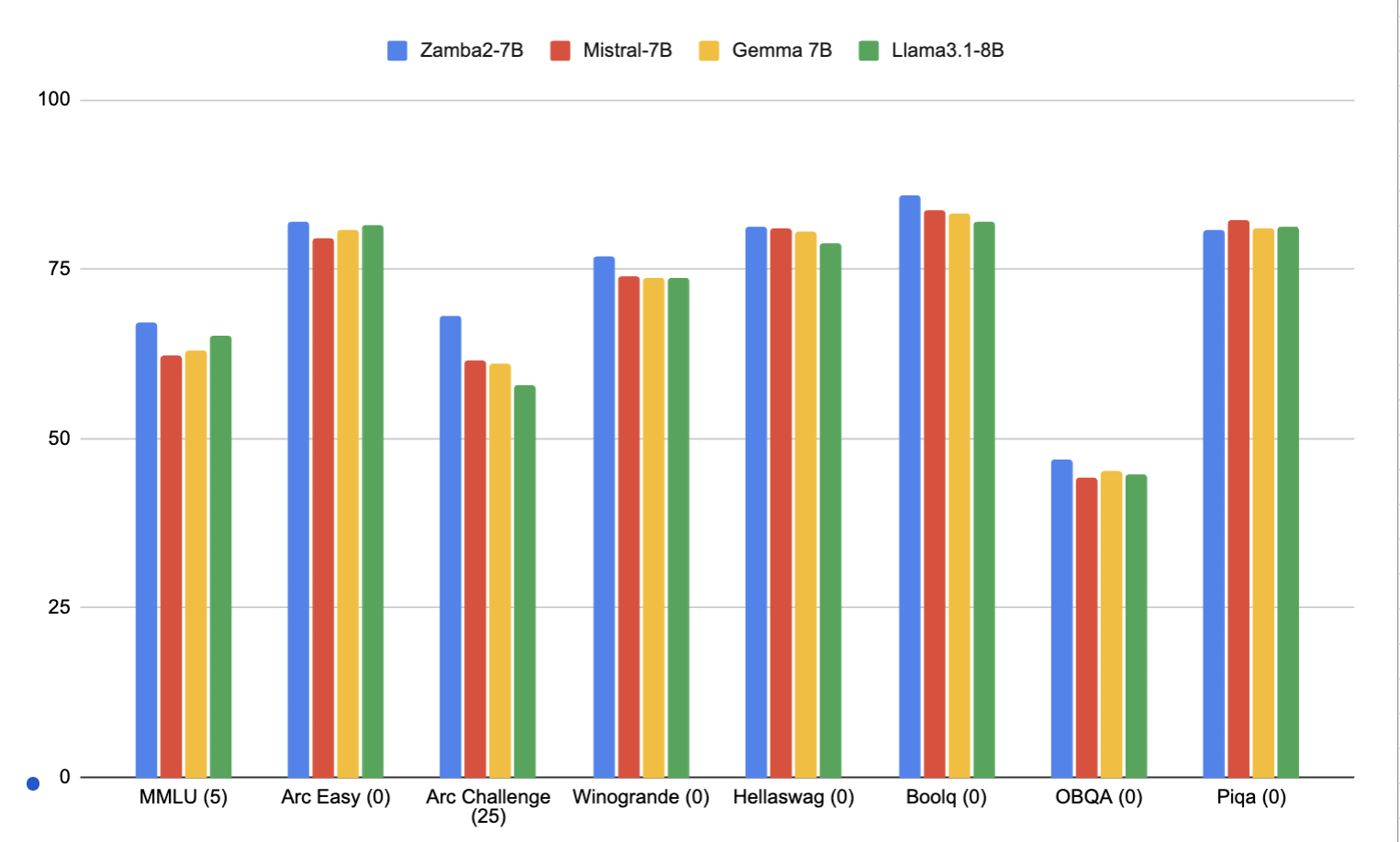
Zamba2-7B has about 7.4 billion parameters, and was pre-trained with 2 trillion tokens of text and code data, followed by an additional training phase using about 100 billion high-quality tokens. As a result, Zamba2-7B (blue) outperforms Mistral-7B (red), Gemma 7B (yellow), Llama 3.1-8B (green), and other models with parameters of 8B or less, Zyphra claims.
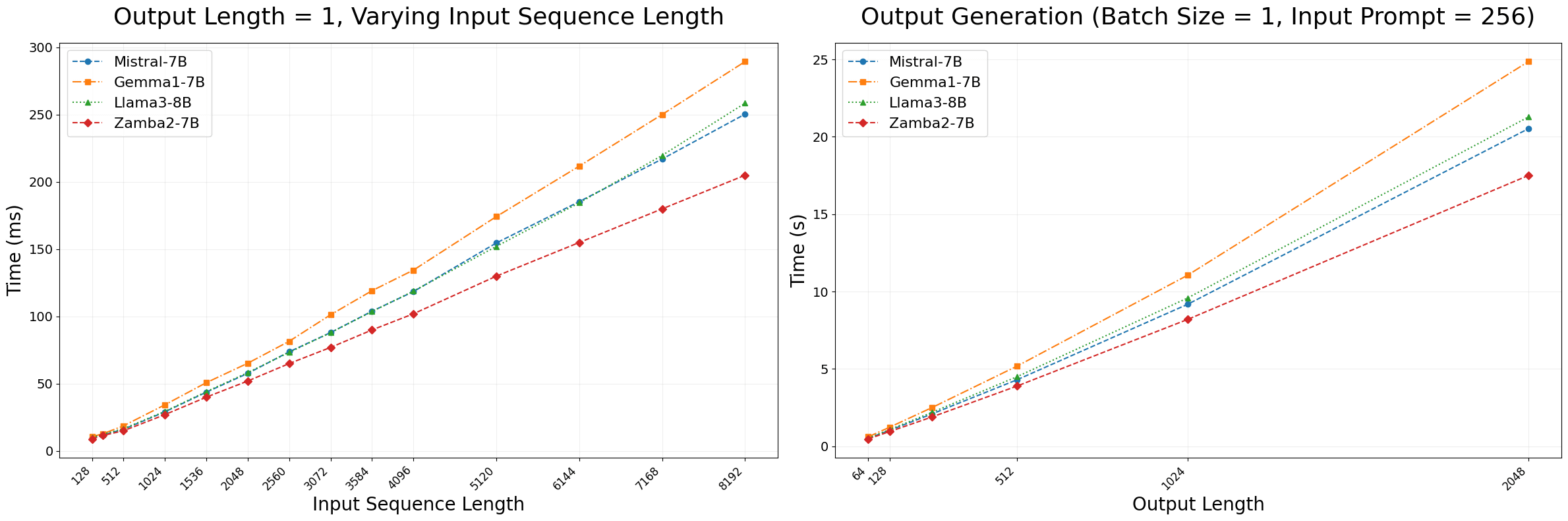
In particular, Zyphra focuses on the inference efficiency of Zamba2-7B. As shown in the graphs below, Zamba2-7B (red) is capable of generating tokens faster with a significantly smaller memory footprint than conventional Transformer-based models, with a 25% reduction in time to token generation (left) and a 20% improvement in token generation speed (right).
Zamba2-7B has been released as open source under the Apache 2.0 license , making it freely available to researchers, developers and companies. Zephra said that Zamba2-7B is a small, high-performance and efficient language model that is a suitable choice for on-device processing, running on consumer GPUs, and for many enterprise applications.
Related Posts:







