``FlexGen'' that can process large-scale language models such as GPT-3 even with a single GPU appears

Processing large language models such as GPT-3 is computationally intensive and memory intensive, typically requiring multiple high-end
GitHub - Ying1123/FlexGen: Running large language models like OPT-175B/GPT-3 on a single GPU. Up to 100x faster than other offloading systems.
https://github.com/Ying1123/FlexGen#readme
FlexGen is an engine created for the purpose of reducing the inference resource requirements of large language models to a single GPU and making it flexible to various hardware. It is up to 100x faster than other offload-based systems when running the language model OPT-175B.
The benchmark results are as follows. The numbers are production throughput, in tokens per second. A T4 (16 GB) instance on GCP with 208GB DRAM and 1.5TB SSD is used for testing.
| System | OPT-6.7B | OPT-30B | OPT-175B |
|---|---|---|---|
| Huggingface Accelerate | 25.12 | 0.62 | 0.01 |
| DeepSpeed ZeRO-Inference | 9.28 | 0.60 | 0.01 |
| Petals | - | - | 0.05 |
| FlexGen | 25.26 | 7.32 | 0.69 |
| FlexGen (with compression) | 29.12 | 8.38 | 1.12 |
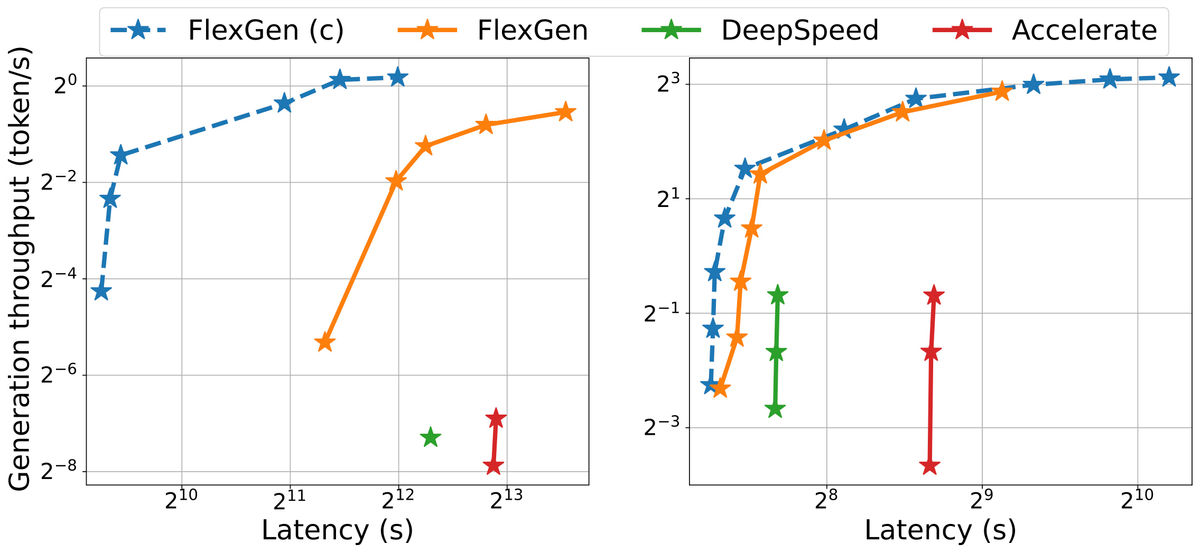
The figure below shows the latency-throughput trade-off for the three offload-based systems on the OPT-175B (left) and OPT-30B (right). Blue indicates FlexGen (with compression), orange indicates FlexGen, green indicates DeepSpeed, and red indicates Accelerate. FlexGen achieves a new Pareto optimal solution with 100 times the maximum throughput of the other two on the OPT-175B. Other systems were unable to increase throughput further due to lack of memory.
Future plans for FlexGen include Apple M1/M2 support, Google Colaboratory support, and latency optimization for chatbot applications.
Related Posts:







in Software, Posted by log1p_kr