Commentary on `` MobileNetV3 '' and `` MobileNetEdgeTPU '' that Google mentions indispensable for next-generation on-device processing such as Pixel 4

“
Google AI Blog: Introducing the Next Generation of On-Device Vision Models: MobileNetV3 and MobileNetEdgeTPU
https://ai.googleblog.com/2019/11/introducing-next-generation-on-device.html
Google announced various new technologies in Google I / O 2019 , but the keyword was “on-device”, that is, processing on the terminal. For example, in the case of a function that uses machine learning, it is possible to ensure both privacy and security by speeding up the processing speed by completing all the necessary processing “on-device”.
Algorithmic neural network models and hardware that can run billions of operations per second with just a few milliwatts of power to run on-device machine learning on computing power and power limited devices Seems to be necessary.
Pixel 4 which is Google's latest smartphone adopts “ Pixel Neural Core ” which can accelerate on-device processing developed with the same architecture as Edge TPU which is machine learning accelerator. Pixel Neural Core supports the core functions of Pixel 4, such as Face Unlock, a face recognition function that has been newly introduced in Pixel 4, the Google Assistant that is faster than before, and the camera function. Can also be called.

If Pixel Neural Core helps Pixel 4's on-device processing from the hardware side, it is a lightweight, high-performance
Becomes indispensable to on-device processing will continue to be important next generation in such recent technology, the newest version of MobileNet ' MobileNetV3 a' corresponds to the Edge TPU optimization of Pixel 4 ' MobileNetEdgeTPU ' Was announced by Google. Google describes these models as 'the culmination of the latest advances in hardware-enabled automatic machine learning (AutoML) technology and some advances in architecture design.'
For example, in the case of MobileNetV3, it has doubled the processing speed with the same accuracy as MobileNetV2 on the mobile CPU for smartphones, so it says that “the advanced technology of mobile computer vision network can be advanced”. MobileNetEdgeTPU also succeeds in reducing runtime and power consumption at the same time by improving model accuracy.

◆ MobileNetV3
Unlike manually-designed MobileNetV2, MobileNetV3 is designed as an 'architecture that can find the best
First, use MnasNet, which uses reinforcement learning, to roughly search the architecture and select the optimal configuration from individual options. Next, it seems that a fine adjustment to the architecture will be made using NetAdapt, which is the best complementary method to trim the activation channel with low usage rate with a small decrement. This allows you to create both large and small models that can deliver the best possible performance under various conditions.
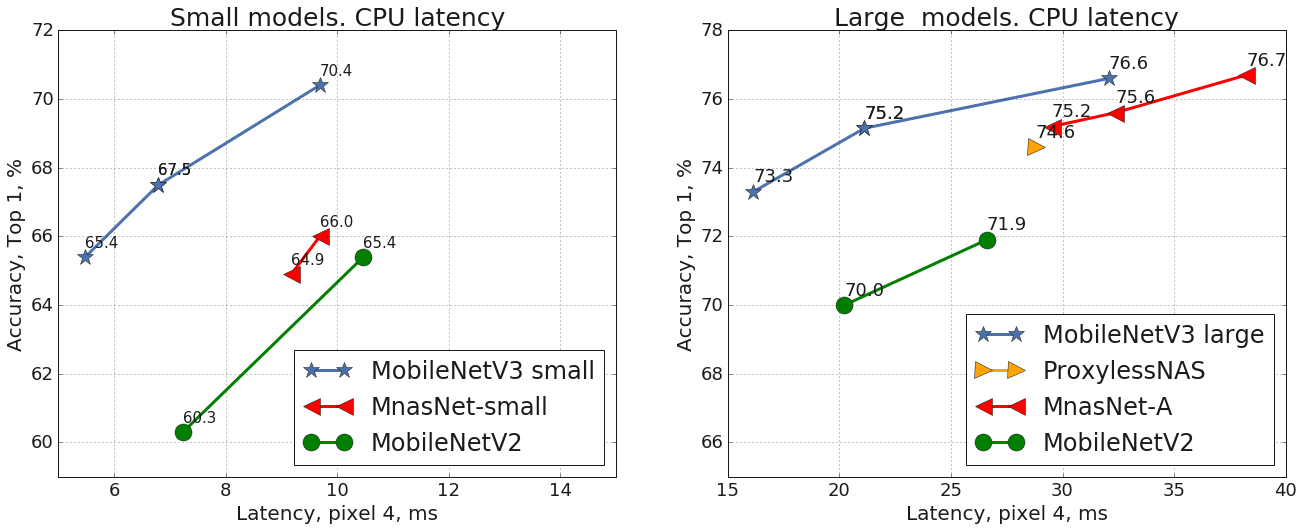
The graph below compares the accuracy and latency of each CNN model in an ImageNet classification task performed on a Pixel 4 CPU. The left shows the accuracy (vertical axis) and latency (horizontal axis) for the small model and the right for the large model. It can be seen that MobileNet V3 (blue) has high accuracy and low delay compared to each CNN model for both large and small models.
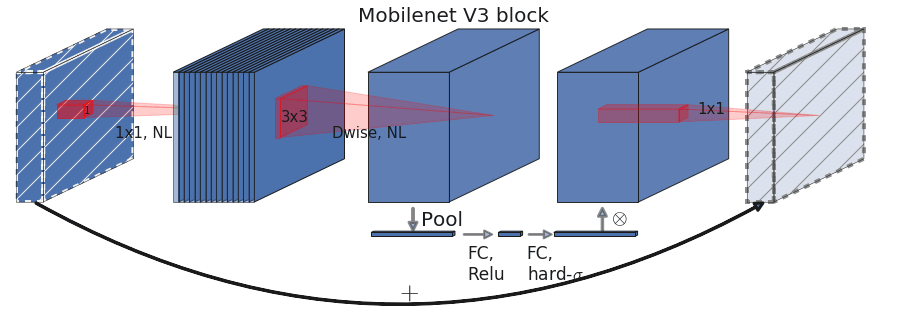
In addition, Google explains that MobileNetV3's search space is 'based on the latest advances in architectural design to adapt to the mobile environment.' A new activation function called 'hard-swish (h-swish)' based on
In addition, we have introduced a technology called “ Squeeze-and-Excitation Networks ” to replace the conventional sigmoid function with piecewise linear approximation. Combining h-swish and mobile-friendly Squeeze-and-Excitation Networks with a modified version of the reverse bottleneck structure introduced in MobileNetV2, a new building block for MobileNetV3 was born.
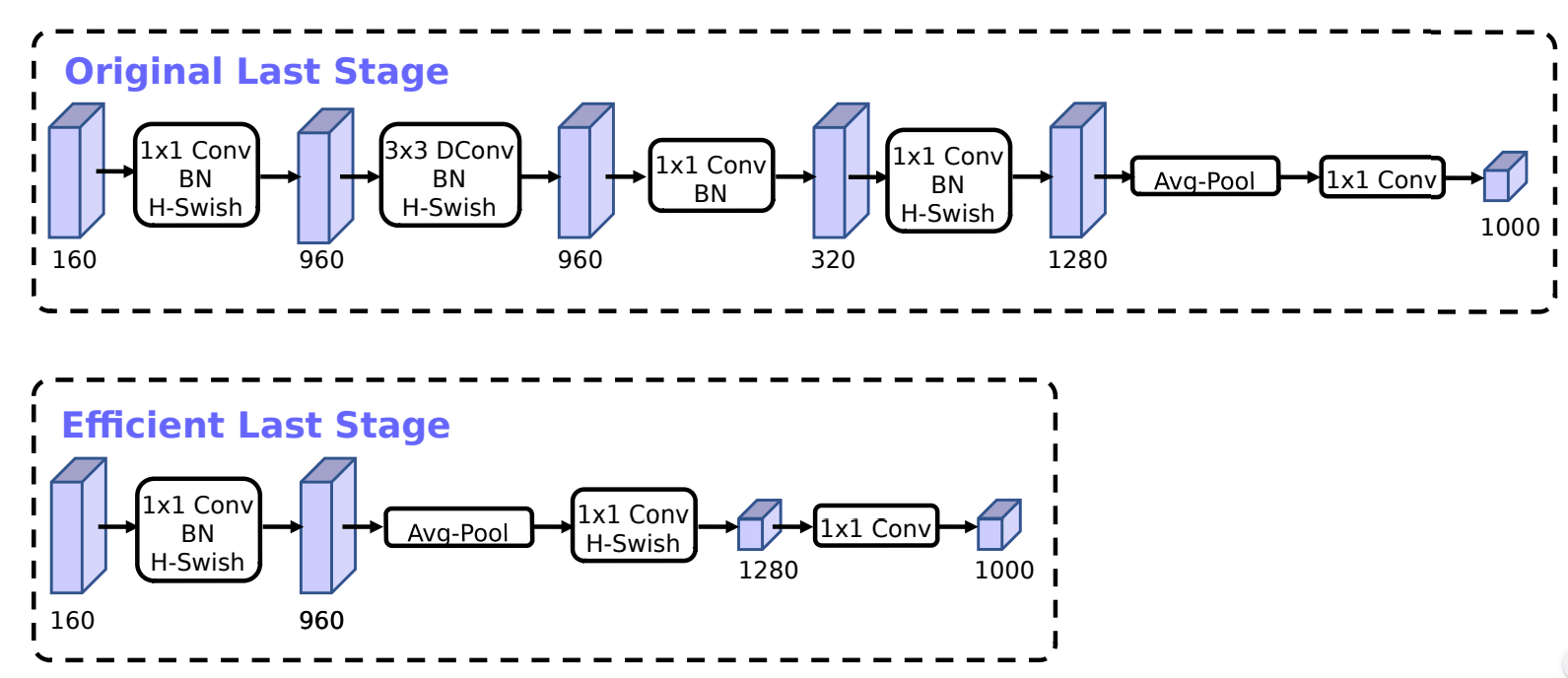
In addition, MobileNetV3 has succeeded in reducing latency by 15% by introducing a new efficient final step at the end of the network.
In addition, MobileNetV3 uses an object detection model in the
In addition, Google aims to optimize MobileNet V3 to achieve efficient semantic segmentation and introduces a low-latency segmentation decoder called “Lite Reduced Atrous Spatial Pyramid Pooling (LR-SPP)”. The combination of LR-SPP and MobileNetV3 will reduce latency by over 35% for high-resolution Cityscapes datasets .
◆ MobileNetEdgeTPU
The Pixel 4 Edge TPU is very similar to the Edge TPU architecture found in Coral products, but customized to optimize the camera functions that are important to Pixel 4. Using an accelerator-enabled automated machine learning approach has succeeded in significantly reducing the manual processes associated with neural network design and optimization of hardware accelerators, an important part of this approach is It seems to be creating a search space in a neural architecture. However, although this is indispensable for building a compact and high-speed CPU model, the Edge TPU is not optimized.
Therefore, in order to optimize the model accuracy and Edge TPU latency at the same time, we created MobileNetEdgeTPU that can achieve low latency with constant accuracy, which is different from existing MobileNetV2 and MobileNetV3, as an incentive search for neural network architecture. Compared to a model called “ EfficientNet-EdgeTPU ” optimized for Coral's Edge TPU, the accuracy is slightly inferior, but much lower latency can be achieved on Pixel 4.
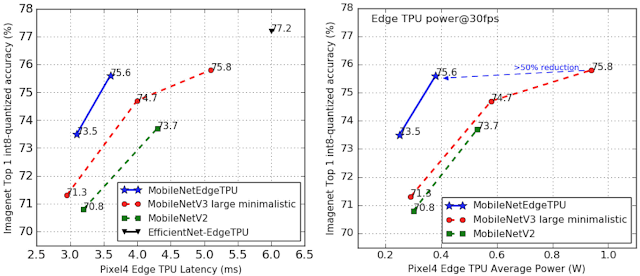
The following is a graph comparing the accuracy and latency in the ImageNet classification task for MobileNetEdgeTPU (blue), EfficientNet-EdgeTPU (black), MobileNetV2 (green), and MobileNetV3 (red). The horizontal axis represents latency, and the vertical axis represents accuracy. As you can see from the graph, MobileNetEdgeTPU has achieved low latency, which contributes to reducing the power consumption of Edge TPU. According to Google, the power consumption of MobileNetEdgeTPU is less than 50% of MobileNetV3 when equivalent accuracy is required.
In addition, MobileNetEdgeTPU classification model is also an effective feature extraction function in object detection task. Compared to the MobileNetV2-based detection model, MobileNetEdgeTPU can significantly improve the model quality of the COCO14 minival dataset with the equivalent runtime of Edge TPU. However, because MobileNetEdgeTPU is a CNN model for Edge TPU to the last, even if it runs on a mobile CPU, Google will be far lower performance than MobileNet V3 etc. which is a CNN model specially adjusted for mobile CPU Warning.
Related Posts:







in Software, Posted by logu_ii