Chinese AI company DeepSeek releases 'DeepSeek-V3', an AI model comparable to GPT-4o, with an astounding 671 billion parameters

DeepSeek, a Chinese AI company, announced the large-scale language model ' DeepSeek-V3 ' on December 26, 2024. DeepSeek-V3, which has 671 billion parameters, is comparable to OpenAI's multimodal AI model '
deepseek-ai/DeepSeek-V3-Base · Hugging Face
https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
Introducing DeepSeek-V3!
pic.twitter.com/p1dV9gJ2Sd — DeepSeek (@deepseek_ai) December 26, 2024
Biggest leap forward yet:
⚡ 60 tokens/second (3x faster than V2!)
Enhanced capabilities
???? API compatibility intact
???? Fully open-source models & papers
???? 1/n
DeepSeek-V3, ultra-large open-source AI, outperforms Llama and Qwen on launch | VentureBeat
https://venturebeat.com/ai/deepseek-v3-ultra-large-open-source-ai-outperforms-llama-and-qwen-on-launch/
DeepSeek-V3 is Now The Best Open Source AI Model
https://analyticsindiamag.com/ai-news-updates/deepseek-v3-is-the-best-open-source-ai-model/
DeepSeek is preparing Deep Roles and released a new V3 model
https://www.testingcatalog.com/deepseek-preparing-deep-roles-and-dropping-high-performing-v3-model/
The newly announced DeepSeek-V3 is a large-scale language model trained with 671 billion parameters and 14.8 trillion tokens. According to overseas media TestingCatalog, DeepSeek-V3 surpasses the previous record of 405 billion parameters held by Llama 3.1 405B , making it the largest language model with parameters to date.
Training DeepSeek-V3 required approximately 2,788,000 GPU hours on NVIDIA's H800 GPU, which cost about $5.57 million (about 870 million yen). However, pre-training large-scale language models typically costs hundreds of millions of dollars (several hundred billion yen), so training DeepSeek-V3 is much cheaper.

DeepSeek-V3 is designed by combining
DeepSeek-V3 also employs a load balancing strategy that dynamically monitors and adjusts the load between networks without compromising the performance of the entire model on the MoE architecture. It also implements a technology called 'multi-token prediction (MTP)' that enables multiple future tokens to be predicted simultaneously. This enables the generation of 60 tokens per second, three times faster than the previous generation DeepSeek-V2 .
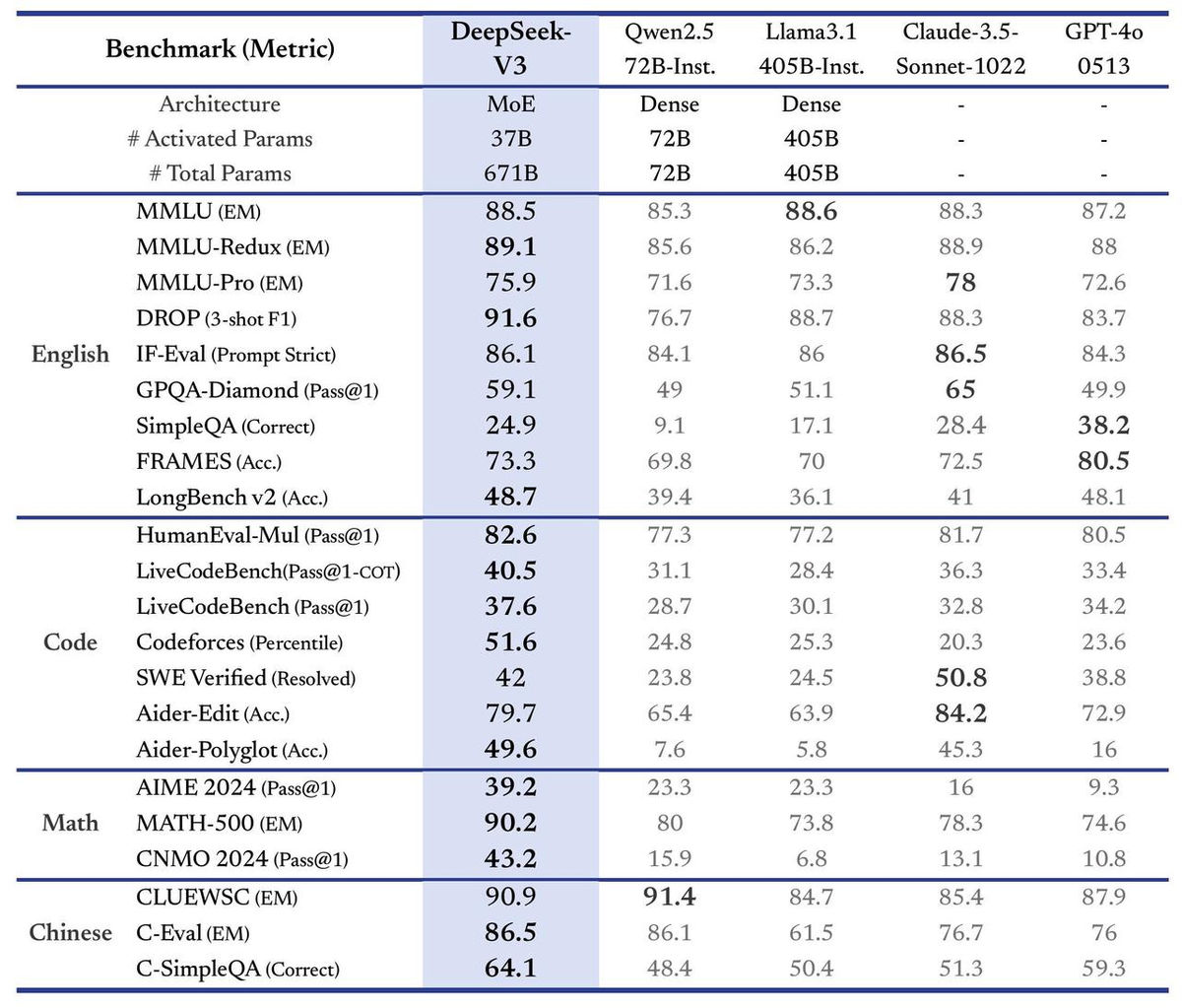
DeepSeek has published benchmark scores for DeepSeek-V3, which are reported to be comparable to ' Qwen2.5 72B ', 'Llama 3.1 405B', ' Claude 3.5 Sonnet-1022 ', and 'GPT-4o 0513'. It has been revealed that it has shown outstanding results against other AI models, especially in programming such as 'HumanEval-Mul', mathematics such as 'CNMO 2024', and Chinese language processing such as 'C-Eval'.
DeepSeek further stated, 'We have cleverly incorporated
In addition, for a limited time until February 8, 2025, API fees for DeepSeek-V3 will remain unchanged from DeepSeek-V2. The price for input is $0.27 (approximately 42 yen) per million tokens, and the price for output is $1.10 (approximately 173 yen) per million tokens.
???? API Pricing Update
— DeepSeek (@deepseek_ai) December 26, 2024
????Until Feb 8: same as V2!
???? From Feb 8 onwards:
Input: $0.27/million tokens ($0.07/million tokens with cache hits)
Output: $1.10/million tokens
???? Still the best value in the market!
???? 3/n pic.twitter.com/OjZaB81Yrh
DeepSeek has open-sourced DeepSeek-V3, and the source code can be downloaded from GitHub.
deepseek-ai/DeepSeek-V3
https://github.com/deepseek-ai/DeepSeek-V3
Related Posts: