Microsoft announces ``phi-1'' that hits HumanEval 50.6% exceeding GPT-3.5 with only 1.3 billion parameters

While small large-scale language models (LLM) such as
[2306.11644] Textbooks Are All You Need
https://doi.org/10.48550/arXiv.2306.11644
Microsoft Releases 1.3 Bn Parameter Language Model, Outperforms LLaMa
https://analyticsindiamag.com/microsoft-releases-1-3-bn-parameter-language-model-outperforms-llama/
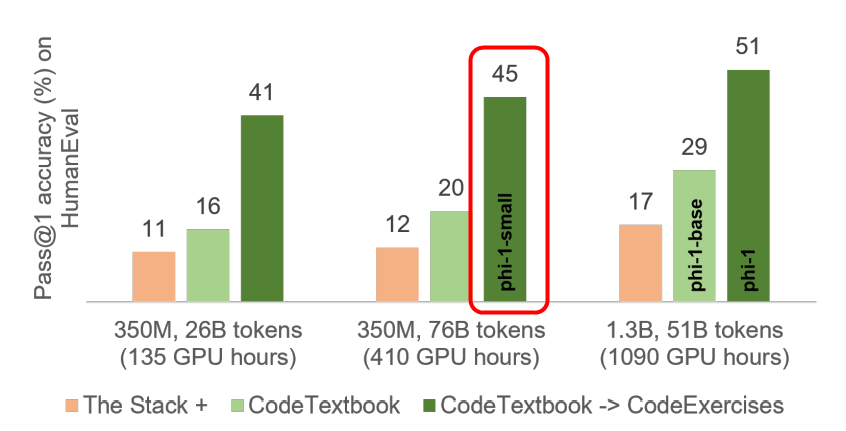
Below is a comparison of the phi-1's performance with other models. phi-1 showed high accuracy of 50.6% in HumanEval, a dataset for evaluating programming ability, and 55.5% in MBPP. This result is less than 67% of GPT-4, but exceeds GPT-3.5 with 175 billion parameters.

Regarding how phi-1 is lightweight, Sebastian Buebeck, one of the authors of the paper, said, ``Other models with over 50% HumanEval are 1000 times larger. was 100 times greater,' he explains.
New LLMs in town:
pic.twitter.com/lNvqvjkW0w — Sebastien Bubeck (@SebastienBubeck) June 21, 2023
***phi-1 achieves 51% on HumanEval w. only 1.3B parameters & 7B tokens training dataset***
Any other >50% HumanEval model is >1000x bigger (eg, WizardCoder from last week is 10x in model size and 100x in dataset size).
How?
***Textbooks Are All You Need***
According to the paper entitled 'Textbooks Are All You Need,' the model uses a textbook-quality dataset of 6 billion tokens collected from the Internet and a textbook dataset of 10 generated from GPT-3.5. It was made with 8 NVIDIA A100s in just 4 days of training using 100 million tokens.
The title of the characteristic paper is thought to be related to the paper ' Attention Is All You Need ' that laid the foundation for the Transformer model.
The research team is also developing an even smaller model, phi-1-small, trained in the same pipeline as phi-1. 'phi-1-small' achieves 45% in HumanEval despite having even fewer parameters at 350 million.
``We used textbook-quality training data for coding, and the results exceeded our expectations,'' co-author Ronen Erdan said. According to Eldan, phi-1 will soon be available on the AI platform Hugging Face.
High-quality synthetic datasets strike again. Following up on the technique of TinyStories (and many new ideas on top) at @MSFTResearch we curated textbook-quality training data for coding.
—Ronen Eldan (@EldanRonen) June 21, 2023
For skeptics- model will be on HF soon, give it a try. https://t.co/LSkNuRpLjr
As pointed out in the social news site Hacker News thread that covered this paper, ``This would not have been possible without the high-quality synthetic dataset generated by GPT,'' the importance of phi-1 The point is that ``you can get a high-performance model by improving the quality instead of increasing the size of the model''.
For example, the open source model ' Orca ', which is regarded as a new rival to GPT-4, is relatively lightweight with 13 billion parameters, but by learning with GPT-4 data, it can be used by OpenAI's product showed better benchmark results.
On the other hand, concerns have been raised about the method of using AI-generated information for AI learning. In the paper 'The Curse of Recursion' published in arXiv in May 2023, the accuracy of the new model decreases due to ' data poisoning ' that occurs by learning with data from other LLMs. was shown. The harm of fine-tuning a weak model with the output from a proprietary, privately held strong model like ChatGPT is called ' The False Promise of Imitating Proprietary LLMs'. It is said that
Researchers warn that ``model collapse'' is occurring due to ``loop in which AI learns AI-generated content'' due to the rapid increase in AI artifacts-GIGAZINE

Related Posts:






in Software, Posted by darkhorse_log