What is the super huge data set 'LAION-5B' that made a great contribution to the development of image generation AI 'Stable Diffusion'?

In building AI, not only the algorithm but also the training dataset is important, and the quality of the dataset greatly affects the accuracy of AI.
LAION-5B: A NEW ERA OF OPEN LARGE-SCALE MULTI-MODAL DATASETS | LAION
https://laion.ai/blog/laion-5b/
A German non-profit organization called ' Large-scale Artificial Intelligence Open Network (LAION) ', which promotes the public release of large-scale machine learning models, datasets, and related codes, will launch a super-huge dataset in March 2022. 'LAION-5B' has been released. Machine learning community Hugging Face , AI development company doodlebot , and Stable Diffusion developer Stability.ai provide computing resources for the creation of LAION-5B.
LAION-5B consists of 5.85 billion image-text combinations filtered by CLIP , an image classification model, of which 2.3 billion are image-English text pairs, 2.2 billion are images and more than 100 Non-English text pairs, the remaining 1 billion pairs are images and text pairs that are not limited to a specific language, such as names. In addition, it is said that about 130 million pairs of Japanese data sets are included. In a statement published at the time of the release, the LAION research team said that while large-scale image-text models trained on billions of image-text pairs show high performance, training datasets of this size were not generally available. indicate. To address this problem, LAION seems to have decided to create and publish a large-scale image-text pair dataset.
LAION said, “The motivation behind creating the dataset is to conduct research and experimentation on training large-scale multimodal models and processing large, uncurated datasets crawled from the public internet. 'This dataset expands the potential for multilingual large-scale training and research of language vision models to the wider community, which was previously limited to those who have access to their own large datasets.' I will.”
In creating image and text pairs, LAION analyzes Common Crawl files that provide data on the Internet, selects text and image pairs, and uses CLIP to create highly similar image and text pairs. extracted the pair. Furthermore, text that is too short, images with too high resolution, duplicate data, illegal content, etc. were deleted as much as possible, and in the end, samples consisting of 5.85 billion image and text pairs remained.
LAION provides a library for download, a web interface for exploration and subsetting, a search tool , etc., and excludes watermarked images and NSFW data to improve comfort when using it as a dataset. I also set a tag. LAION said, “Watermarked images are a big problem when training image generation models such as DALL-E and GLIDE. To tackle this problem, we trained a watermark detection model and used it to We calculated confidence scores for all images with -5B.'
Among the data included in LAION-5B, the following shows the ratio of 'Width (width of image)', 'Height (vertical width of image)' and 'Text length (number of text characters)' for the English data set. You can see that 128 to 1024 pixels account for 80% or more of the width and height of the image, and 80% or more of the text characters are 100 characters or less. Also, the percentage of unsafe data is 2.9%, and the percentage of watermarked images is 6.1%.
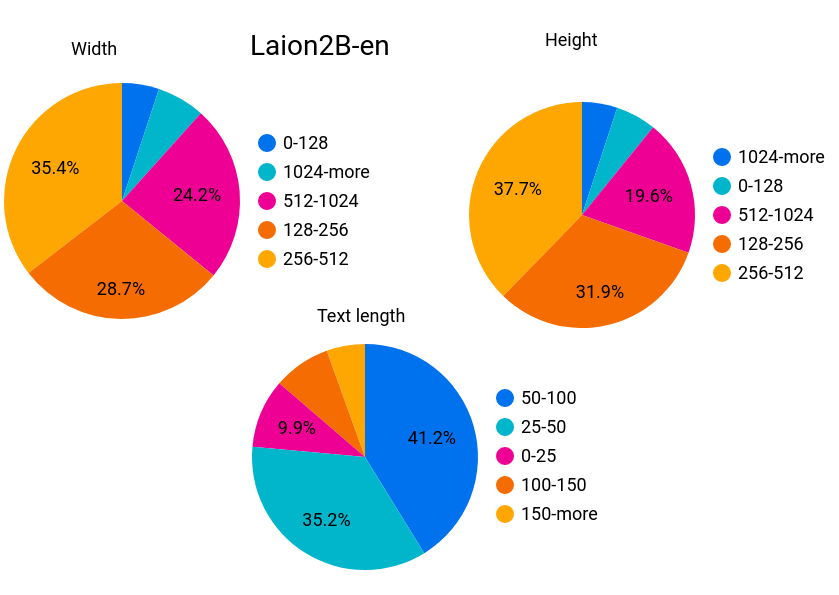
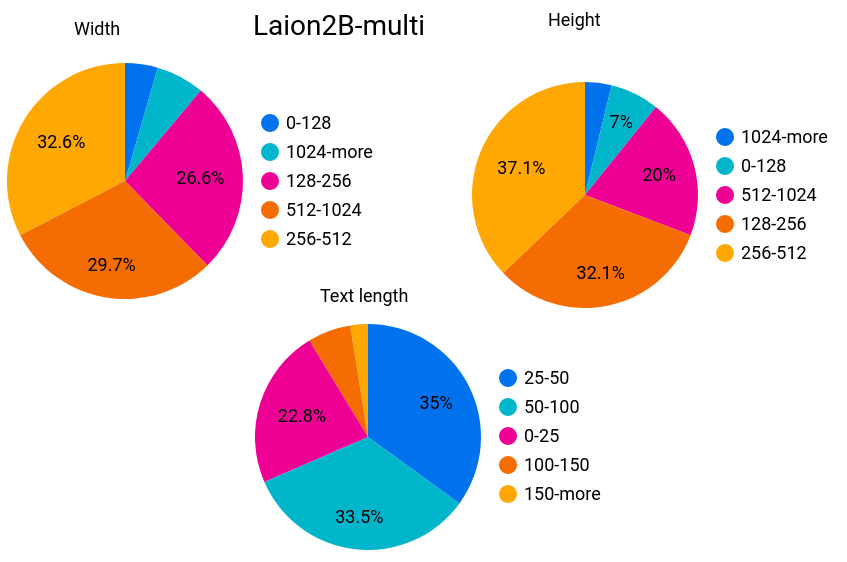
Regarding the non-English data set, looking at the graph below, which similarly shows 'image width', 'image height', and 'number of text characters', the overall trend is similar, although there are some differences. I understand. In this dataset, the percentage of unsafe data was 3.3% and the percentage of watermarked images was 5.6%.
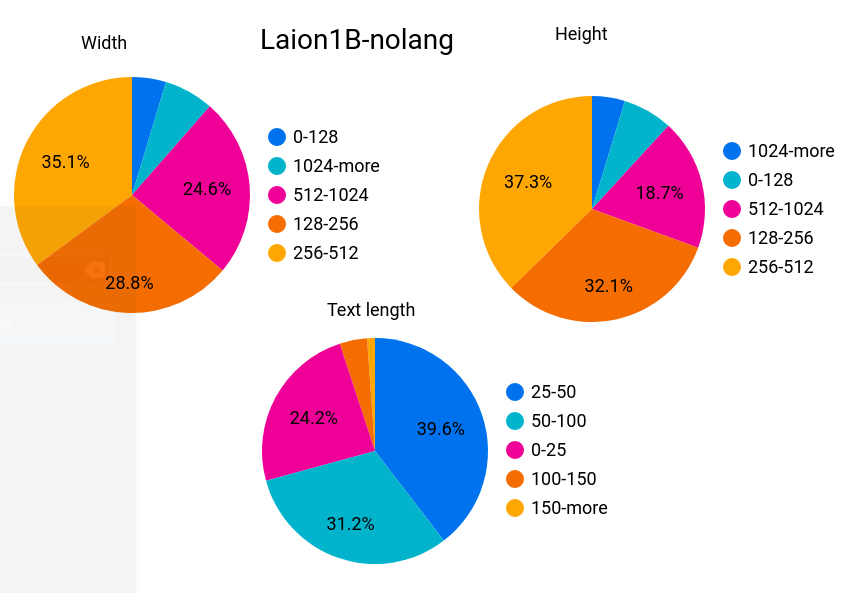
Below is a graph of a dataset that cannot be classified by language. The percentage of unsafe data is 3% and the percentage of images with watermarks is 4%. The dataset is released for free under the '
LAION warns that LAION-5B may contain offensive content due to its uncurated nature. Although you can filter out objectionable content to some extent based on safety tags, you may still encounter potentially harmful content afterwards. 'Since basic safety research is still ongoing, we do not recommend using it to create a ready-to-use commercial product.'
After its release, LAION-5B contributed greatly to the AI industry, such as being used in the development of Stable Diffusion, but it has also been pointed out that the dataset contains medical images that have leaked from somewhere. . There's also a tool called 'Have I Been Trained?' that allows you to search if your work has been used in datasets.
``Have I Been Trained?'' that allows you to search whether your work has been used arbitrarily for image generation AI-GIGAZINE
Related Posts:







in Software, Posted by log1h_ik